本文主要是介绍2021AAAI)Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for MSA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Self-MM
1. 动机:
根据表征学习中指导的不同,我们将现有的方法分为前向指导和后向指导两类。
在正向制导方法中,研究致力于设计用于捕获跨模态信息的交互(MFN之类)模块(Zadeh et al 2018a;Sun等2020;蔡等人2019;Rahman et al 2020)。然而,由于统一的多模态注释,它们很难捕获特定于模态的信息。在反向引导方法中,研究人员提出了附加的损失函数作为先验约束(MISA之类),这使得模态表示同时包含一致和互补的信息(Yu等)2020年;Hazarika, Zimmermann, and Poria 2020)。
对于CH-SIMS和MISA的工作,在前者中,单模态标注需要额外的人工成本,而在后者中,空间差异难以表示特定于模态的差异。
所以,与Yu等人(2020a)即CH-SIMS那篇文章,不同的是,我们的方法不需要人工标注的单峰标签,而是使用自动生成的单峰标签。它基于两种直觉。第一,标签差异与情态表征与类中心之间的距离差异呈正相关。其次,单模态标签与多模态标签高度相关。因此,我们设计了一个基于多模态标签和模态表示的单模态标签生成模块。
考虑到自动生成的单峰标签在起始时代不够稳定,我们设计了一个基于动量的更新方法,该方法对随后生成的单峰标签应用更大的权重。此外,我们引入了一种自调整策略,在整合最终的多任务损失函数时调整每个子任务的权值。我们认为,在自动生成的单模态标签和人工标注的多模态标签之间,具有小标签差异的子任务很难学习特定于模态的表示。因此,子任务的权重与标签差呈正相关。
我们的工作的新贡献可以总结如下:
1. 我们提出了基于模态表示和类中心之间的距离的相对距离值,与模型输出正相关。
2. 我们设计了一个基于自监督策略的单峰标签生成模块。此外,引入了一种新的权值自调整策略来平衡不同的任务损失约束。
3 在三个基准数据集上进行了大量实验,验证了自动生成单峰标签的稳定性和可靠性。此外,我们的方法优于目前最先进的结果。
2. 相关工作
省略。
3. 方法
Self-MM的目标是通过联合学习一个多模态任务和三个单模态子任务来获取信息丰富的单模态表征。与多模态任务不同,单模态子任务的标签是在自监督方法中自动生成的。为了方便下面的章节,我们将人工标注的多模态标签称为m-label,将自动生成的单模态标签称为u-label。
3.1 任务设定
回归任务,有三个模态t、a、v。有四个输出,一个多模态Ym-hat,三个单模态输出Ys-hat,单模态输出是为了辅助表征学习,最终只使用Ym-hat作为预测结果。
3.2 整体框架
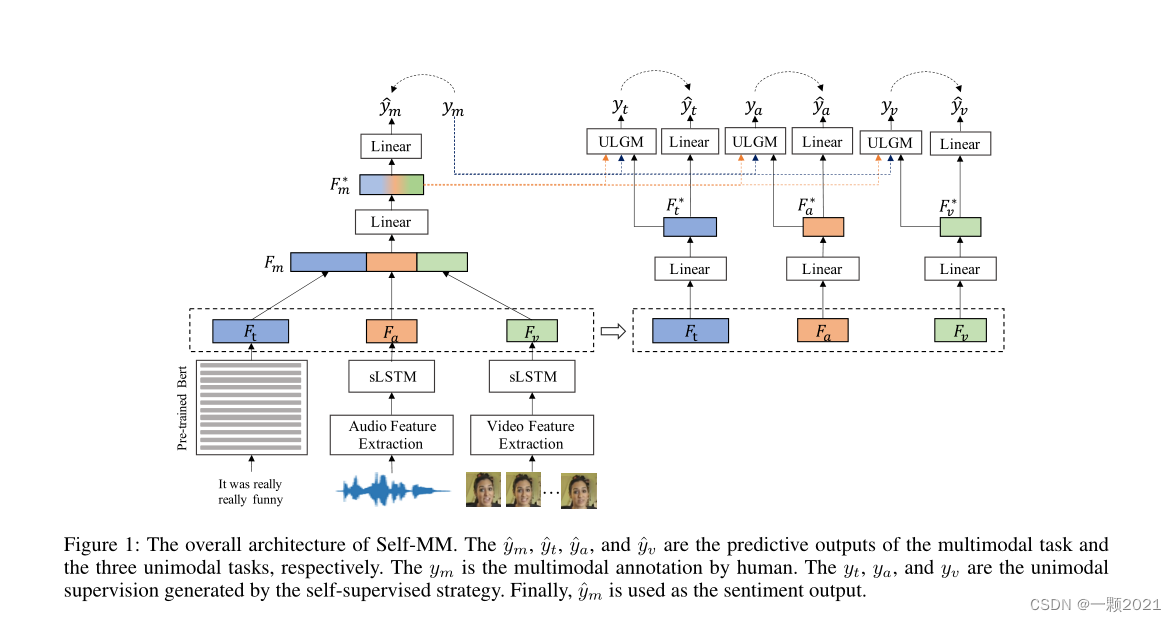
Multimodal task
对于文本,用Bert提取特征,视频和音频使用单向LSTM提取特征。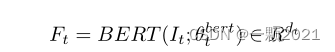
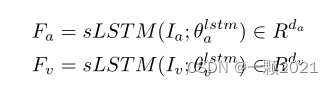
然后将三个拼接后投射到一个低维空间。
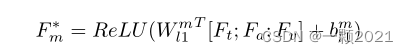
最后经过线性层,用融合的多模态表示来预测情感。
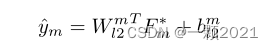
Uni-modal Task
对于三个单模态任务,它们与多模态任务共享模态表示。为了减小不同模态之间的维度差异,我们将它们投影到一个新的特征空间中。然后,用线性回归得到单模态结果。
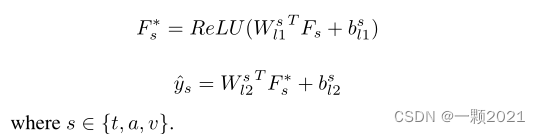
说白了就是两个线性层。
为了指导单峰任务的训练过程,我们设计了一个单峰标签生成模块(Unimodal Label Generation Module)==(ULGM)==来获取单峰标签。ULGM的详情见第3.3节。
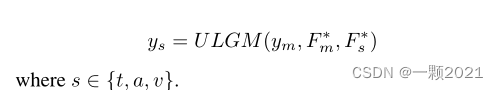
最后,在m标签和u标签的监督下,共同学习了多模态任务和三个单模态任务。值得注意的是,这些单模态任务只存在于训练阶段。因此,只使用ym作为最终输出。
3.3 ULGM
重点来了,感觉这一部分可以用在任何没有细粒度标注的多模态数据集。
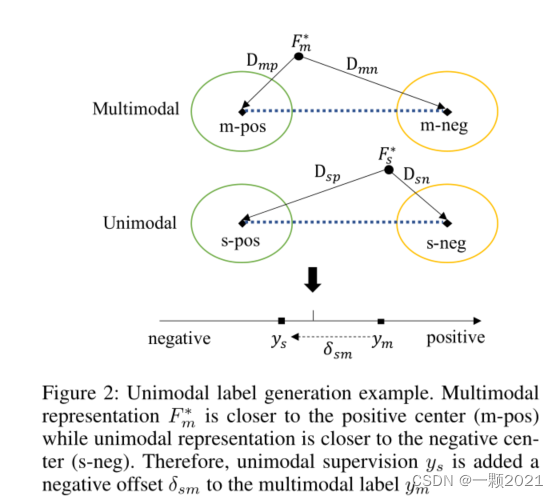
ULGM旨在基于多模态注释和模态表示生成单模态监督值。为了避免对网络参数更新造成不必要的干扰,将ULGM设计为无参数模块。作者认为单模态标签和多模态标签是高度相关的,假设计算模态表示与模态中心点的中心距离为α,作者认为单模态的α与多模态的α的比值约等于单模态标签与多模态标签的比值,通过这一关系计算出单模态标签距离多模态标签的偏移,进而得出单模态标签。因此,ULGM根据从模态表示到类中心的相对距离计算偏移量,如图所示。
算法流程:
1.首先计算正样本中心和负样本中心Cpi和Cni ,i∈{m,t,a,v}
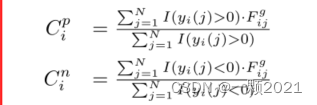
N是训练样本个数,I(.)是指标函数,即对于一个子集合A,若x属于A,
则IA(x)= 1,否则为0。Fgi,g是模态i第j个样本的全局表示。
2.计算样本与正负中心点之间的距离。
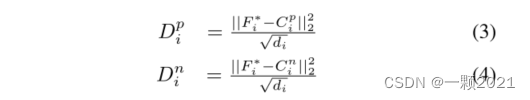
3.计算样本与正负中心点之间的相对距离αi
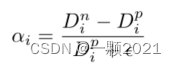
==可以直观地看出,αi与最终结果呈正相关。即αi值越大,情感越积极,值越小,情感越消极。离负样本中心距离越大,离正样本的距离越小,αi的值就越大。
4.计算单模态标签。
为了得到监督和预测值之间的联系,考虑以下两种关系。
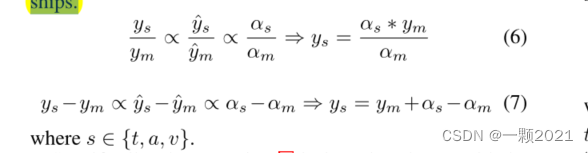
作者认为单模态标签和多模态标签是高度相关的,生成的单模态标签应该与真实的多模态标签的比值和输出的单模态标签与输出的多模态标签的比值成正相关,同时与二者计算出来的的相对距离的比值成正相关。
作者在这里考虑了两种情况,一种乘法,另一种加法。如上图。但是乘法会遇到分子为0的情况,当ym=0,则生成的ys始终为0,所以考虑等权求和得到单峰监督。

5.基于动量的更新策略
由于模态表示的动态变化,由式(8)计算得到的生成的u-label不够稳定。为了减轻不利影响,我们设计了一个基于动量的更新策略,该策略将新生成的值与历史值相结合。

后续生成的单模态标签权重大于前一个。与经验一致。(PS:这里第二项分子为2,是不是弄反了?)
最终算法如下。

3.4 优化目标
最后,我们使用L1Loss作为基本优化目标。对于单模态任务,我们使用u标签和m标签之间的差异作为损失函数的权重。这表明网络应该更加关注差异较大的样本。(为什么说高度相关,这里又差异更大)
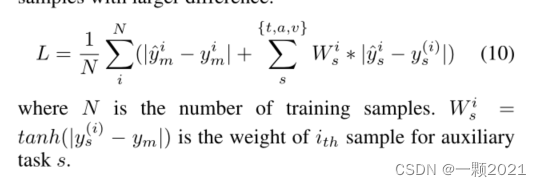
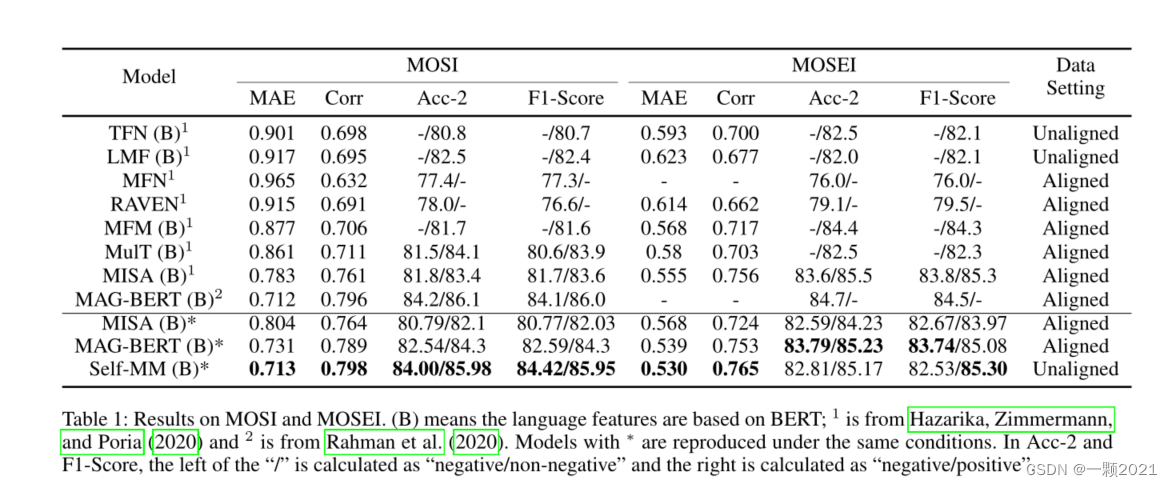
4.实验
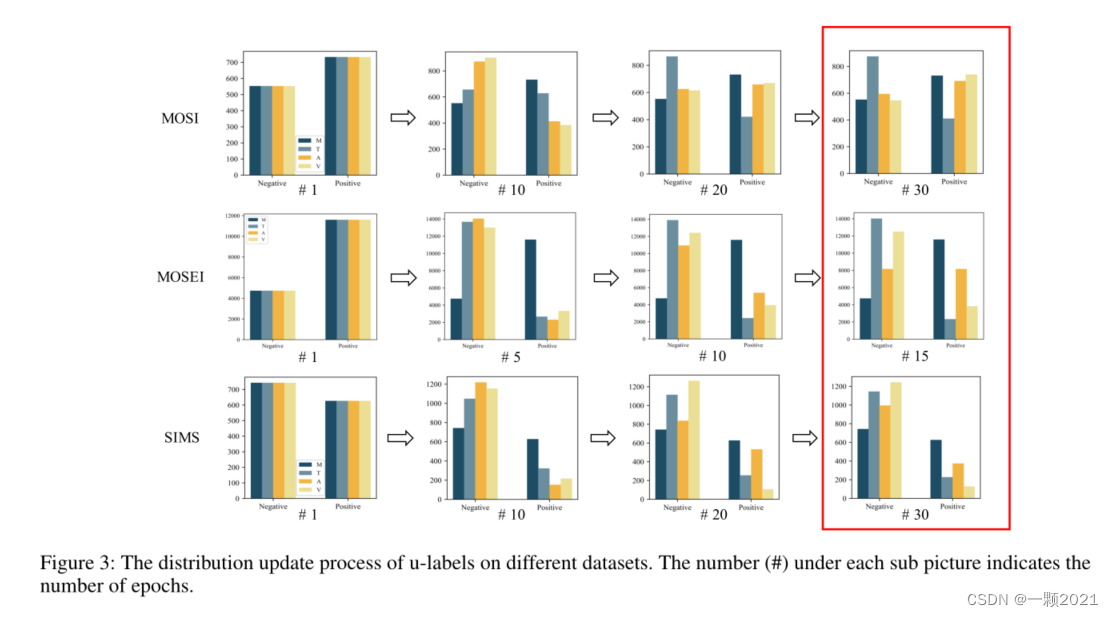
u标签在不同数据集上的分布更新过程。每个子图片下面的数字(#)表示epoch的数量。可以看到30轮后生成的单模态标签和多模态标签差异很大。
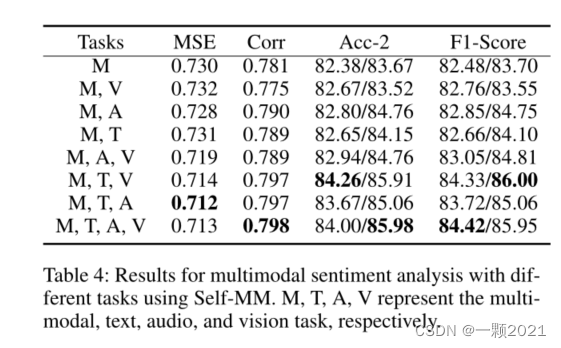
这里消融实验看起来多模态标签+文本+语音/图像已经够好可以媲美
M+T+A+V。
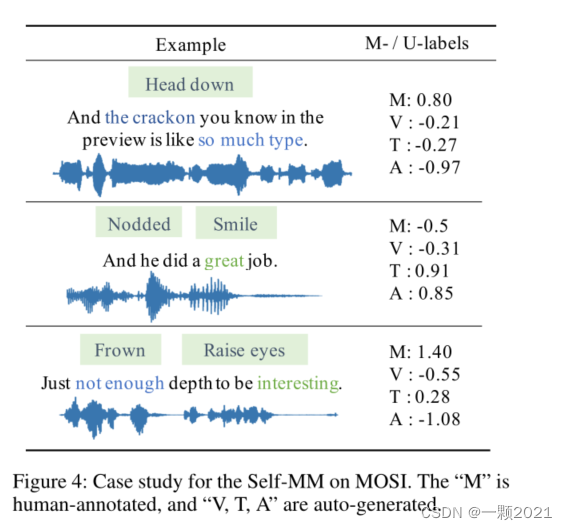
最后是案例分析,可以看到生成的单模态标签更准确且跟多模态标签差异很大,这些信息迫使模型学习到差异。
这篇关于2021AAAI)Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for MSA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






