本文主要是介绍论文阅读25 | Exploring Modality-shared Appearance Features and Modality-invariant Relation Features reid,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:Exploring Modality-shared Appearance Features and Modality-invariant Relation Features for Cross-modality Person Re-Identification
1.创新点
本文的创新点在于,作者提出表观特征的不同通道关注着人体的不同部位,所以使用三维卷积寻找不同通道之间的关系,即人体部位之间的关系(与模态无关),可以有助于识别不同体型的行人。使用了像PCB的切块局部特征原理,提高识别性能。损失方面,作者提出了一个四元组损失(两个三元组的结合,包括anchor,跨模态正样本,跨模态负样本,相同模态负样本)
2.网络架构
网络结构主要包括三部分:模态具体特征提取、模态共享特征提取、部分对齐块。第一部分使用双流网络分别提取RGB和IR图像的具体特征;第二部分使用多级双流模态共享特征提取器,提取模态共享特征(模态共享表观特征、模态不变关系特征);第三部分采用部分对齐块,从不同的part中提取最终的人物特征。
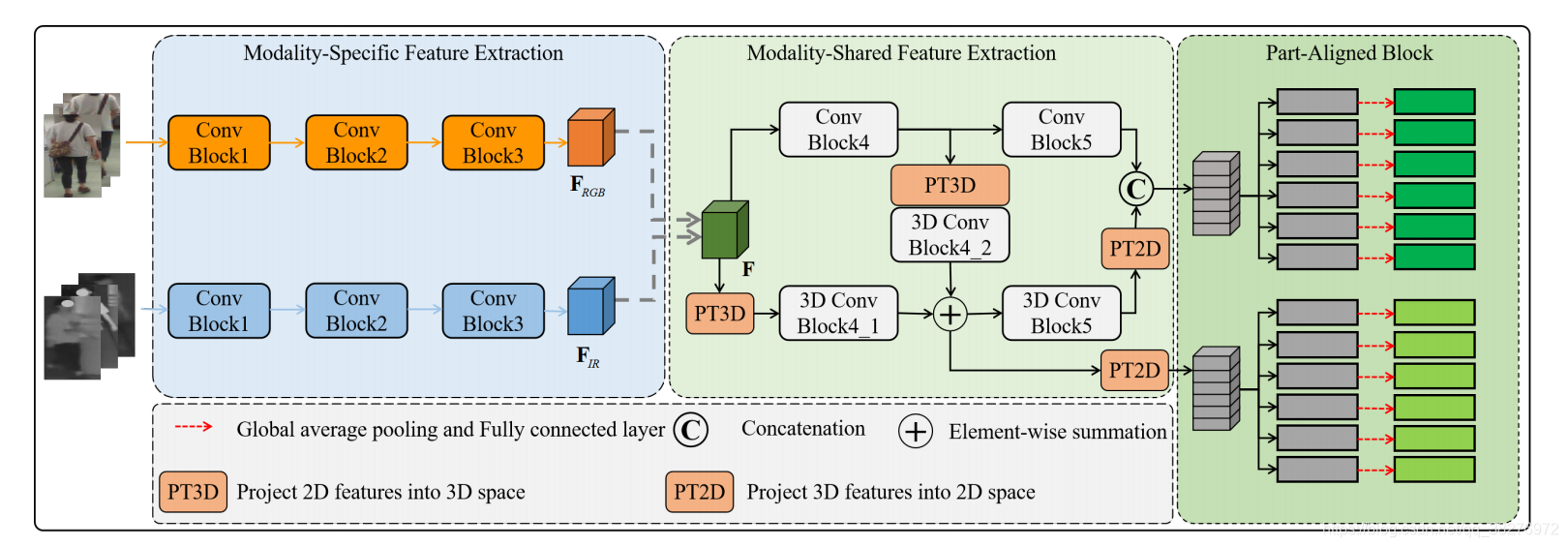
(1)模态具体特征提取
对于一个多层的神经网络,不同层提取出来的特征具有不同的特性。低级特征包含更多的空间或局部信息(例如,颜色、纹理、边缘和轮廓),而高级特征包含更多的语义信息(例如,对象、人体的某个部位)。与高级语义信息相比,低级空间信息更与模态相关。例如,人体的语义信息可以同时包含在RGB图像和红外图像的高级特征中,而颜色信息只存在于来自RGB图像的低级特征中 。
因此,这两个子网络使用了一个相对较浅的CNN来进行特定模态的特征提取。两个分支结构相同,都使用resnet的前三个block,参数独立。
(2)模态共享特征提取
提取模态共享特征的目的,是提取可区分的模态共享特征来减少跨模态的变化和模态内的变化。现存方法大多只提取模态共享的外观特征,它可能无法捕获足够的模态不变信息和鉴别信息。行人身体部位之间的关系(即模态不变关系特征),会是对模态共享外观特征的补充。为此,设计了一个多级双流模态共享特征提取器,联合提取这两种模态共享特征,可以增强最终模态共享特征的鉴别性。
特征提取器包含两个子网络。一个是基于二维CNN的子网络,将特定模态特征投影到共享二维特征空间中,来提取模态共享的外观特征。另一个是基于三维CNN的子网络,通过将模态特定特征和模态共享外观特征投影到共享的三维特征空间中,来捕捉模态不变关系特征。
模态共享表观特征
使用resnet50的后两个block提取共享表观特征,依次得到特征Fa1和Fa2。这两个不同层次的特征都会被使用,因为在不同的等级包含的语义信息不一样,可以增强最终的特征鉴别能力。
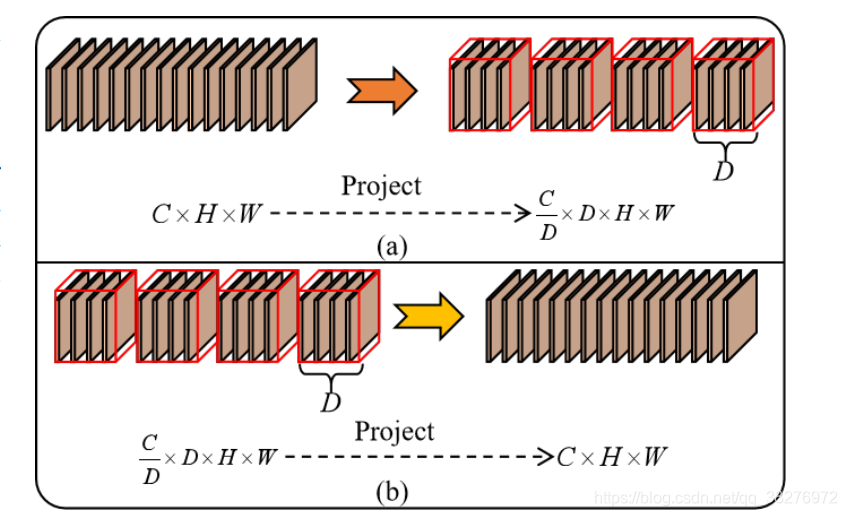
PT3D
PT3D其实就是沿着通道方向,把特征图分成很多组,每组包含D个通道,所以每一组都被构造为一个尺寸为D×H×W的三维特征。通过这种方式,提取的特征被投影到一个共享的三维特征空间中。
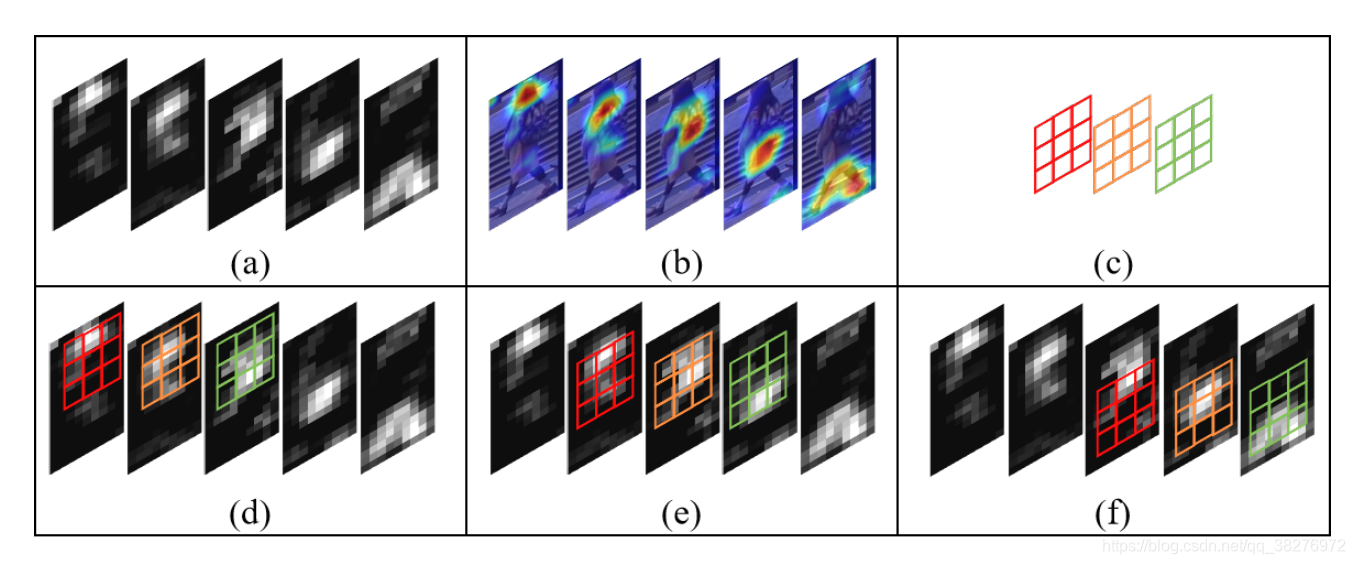
三维卷积
在这个共享的三维特征空间中,通过使用两个堆叠在一起的3D卷积层(卷积核3x3x3),可以建立特征中的空间关系和通道关系。(a)表示从一组外观特征转换来的一个三维特征;(b)表示外观特征包含了人体不同部位的空间信息;©是一个3x3x3的卷积核;(d)-(f)表示在共享三维空间中人体不同部位之间的外观特征的关系可以被卷积核捕获。
模态共享关系特征
外观特征的不同通道主要包含了人体不同部位的鉴别信息。因此,通过捕捉不同外观特征的通道之间的关系,可以获得关系特征。
对于下面的分支,首先使用PT3D投影操作(Projecting features inTo 3D feature space),将特征映射到三维共享空间中,然后利用三维卷积块来提取特征之间的关系。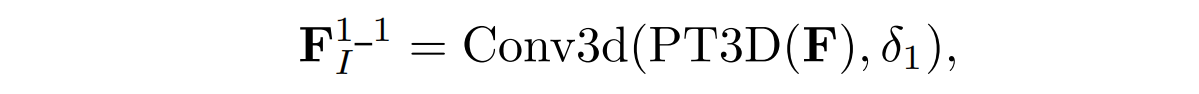 考虑到提取的模态特定特征和模态共享外观特征具有不同的性质,所以同时也捕获了模态共享外观特征的关系,以提高模态不变关系特征的多样性,并进一步提高了模态共享特征的可识别性。
考虑到提取的模态特定特征和模态共享外观特征具有不同的性质,所以同时也捕获了模态共享外观特征的关系,以提高模态不变关系特征的多样性,并进一步提高了模态共享特征的可识别性。
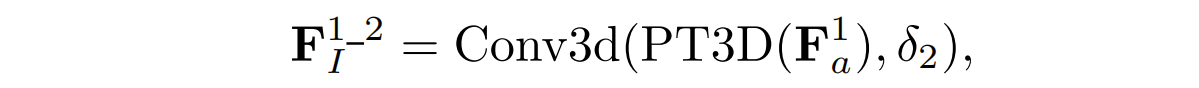
第一个模态不变性特征,由上两个特征逐元素相加得到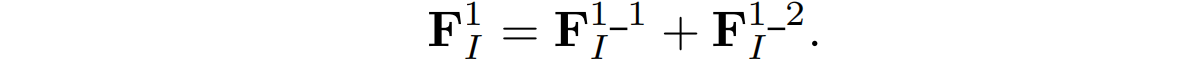
第二个模态不变性特征,由第一个模态不变性特征直接经过一个三位卷积获得
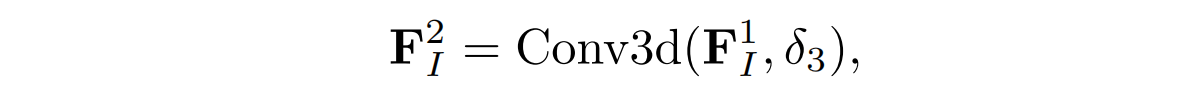
最后,将提取的模态不变关系特征投影回二维特征空间,并且和模态共享外观特征连接起来,方便后续操作。由此得到了两个层次上的模态共享特征,即,
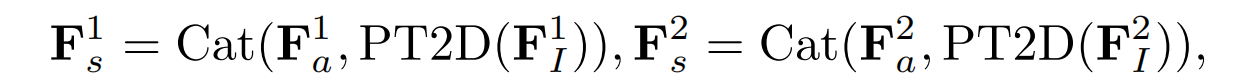
Fs1和Fs2表示最终的模态共享特征。
(3)部分对齐块
给定提取的模态共享特征F1s和F2s,采用部分对齐块从不同的人体部位提取最终的人物特征。具体的,基于PCB的模型,将F1s和F2s分别切割为六个part。对于每个part,采用全局平均池(GAP)获取每个部分的全局信息,然后使用一个全连接层来获得最终的特征嵌入,表示图像相应的部分。
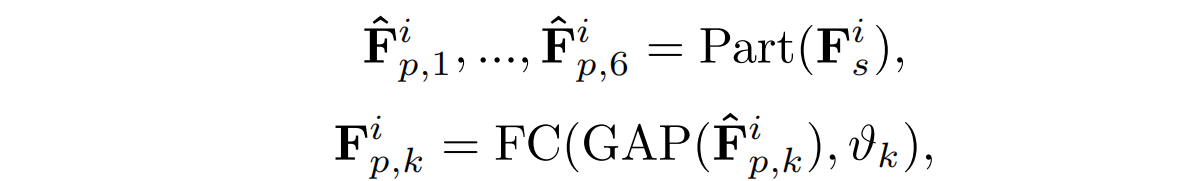
不同部位的Fipk,应该可以区分不同的人,因此使用Fipk来预测行人的识别,具体地说,对于每个部分内的特征,会执行一个FC层来预测它属于哪个人的识别。cls表示从第i级特征中的第k部分中得到的人的识别分类分数。
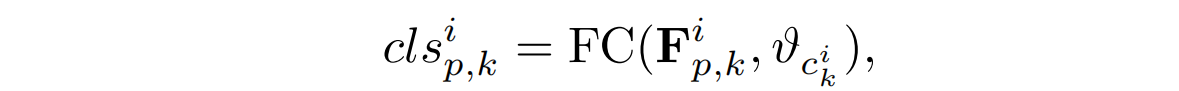
3.损失函数
(1)跨模态四元组损失
所有的输入特征都是经过了L2正则化的,可以稳定收敛。基于双向三元组损失的改进,考虑了参考样本与跨模态最远的正样本距离应该小于同模态最近的负样本的距离一个margin。
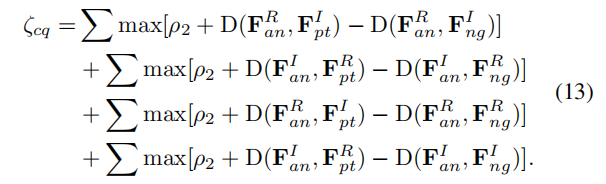
(2)同模态三元组损失
每个模态内,最远正样本距离小于最近负样本距离一个margin
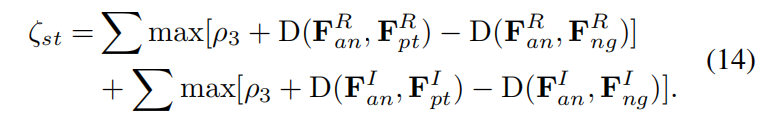
(3)ID损失
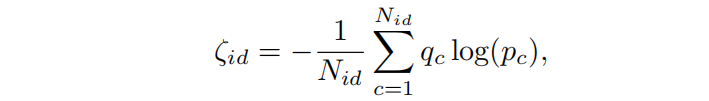
Nid表示行人的类别数,pc表示预测类别,qc表示真实类别。在提出的模型中,对于每个层次(i=1,2)的每个部分(j=1…6)的特征,都使用ID损失来促进模型学习更具有鉴别性的特征。
(4)总损失
最终,将每个层次的每个part的三个损失相加,作为总损失。
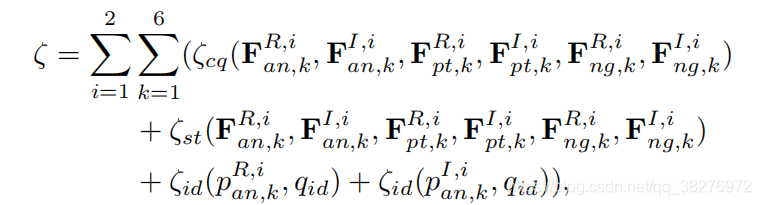
实验指标,在SYSU-MM01上all search的single shot中rank1达到62.56。RegDB上的V to I上rank1达到76.10。
这篇关于论文阅读25 | Exploring Modality-shared Appearance Features and Modality-invariant Relation Features reid的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)