appearance专题

Cross-Image Attention for Zero-Shot Appearance Transfer——【代码复现】
本文发表于SIGGRAPH 2024,是一篇关于图像编辑的论文,Github官网网址如下: garibida/cross-image-attention: “Cross-Image Attention for Zero-Shot Appearance Transfer”的正式实现 (github.com) 一、基本配置环境准备 请确保复现之前已经准备好python、pytorch环

深入探索CSS3 appearance 属性:解锁原生控件的定制秘密
CSS3 的 appearance 属性,作为一个强大的工具,让我们得以细致入微地控制元素的外观,特别是对于那些具有平台特定样式的表单元素,如按钮、输入框等。本文不仅会深入解析 appearance 属性的基本工作原理和使用场景,还将通过详尽的代码示例和额外的属性值介绍,带你全面掌握这一属性的精髓,助力你在网页设计中实现极致的控件样式定制。 appearance 属性详解 属性值 auto:

自我扩展的知识 修改input的date的默认样式、修改鼠标样式、appearance 属性
1、修改input 中的data样式 目前WebKit下有如下9个伪元素可以改变日期控件的UI: ::-webkit-datetime-edit – 控制编辑区域的 ::-webkit-datetime-edit-fields-wrapper – 控制年月日这个区域的 ::-webkit-datetime-edit-text – 这是控制年月日之间的斜线或短横线的 ::-webkit-date
Multiple Object Tracking with High Performance Detection and Appearance Feature
来源:ECCV 2016 本文的跟踪器是POI(Person of Interest),在基于数据关联(data association)的MOT中detection和学习appearance feature是十分重要的。这篇论文使用了高性能的检测和基于深度学习的外观特征,做了大量的实验,结果很有说服力。 基本思路:在每帧上用检测器检测行人的位置,然后利用行人检测框的外观特征进行前后帧行人框的
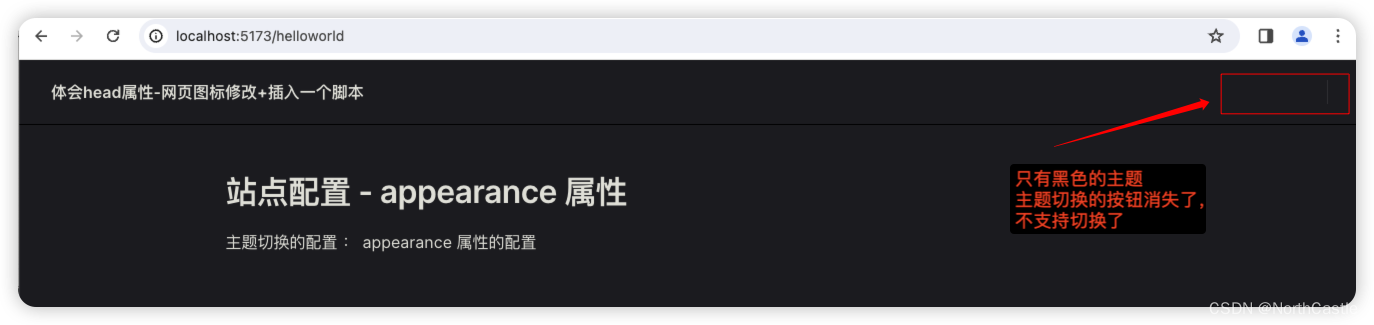
VitePress-17- 配置- appearance 的作用详解
作用说明 appearance : 是进行主题模式的配置开关,决定了是否启用深色模式。 可选的配置值: true: 默认配置,可以切换为深色模式; false: 禁用主题切换,只使用默认的配置; dark: 默认使用深色模式,支持切换; force-dark: 强制使用深色模式,不支持切换。 案例 本案例展示一下 appearance 配置的作用效果 项目结构 为了
ReID中PCB模型输出维度_带你入门多目标跟踪(四)外观模型 Appearance Model
行人跟踪作为MOT中的一个典型的问题,十分具有研究价值,本系列文章以行人跟踪为例来介绍MOT。 在讲解外观模型问题前,首先需要对MOT的各个部件有一个大概的了解。在设计一种MOT算法时,有两点问题需要格外关注。 一是如何测量在视频帧中各目标之间的相似性(measure similarity between objects in frames); 二是如何基于第一点测量出的相似性,进行视频中目标I

tintColor 、Appearance、核心绘图、drawRect方法
1.tintColor 特点:不区分视图的种类,根据设置的范围大小,对所有视图都会起到改变颜色的作用 设置父视图的tintColor,然后在这个父视图内部的所有子视图都将受父视图设置的tintColor影响,从而变成同色系的视图 有一些视图可能具有的不是tintColor,而是xxxTintColor, 如导航栏有的就是 barTintColor,这种视图特有的tint
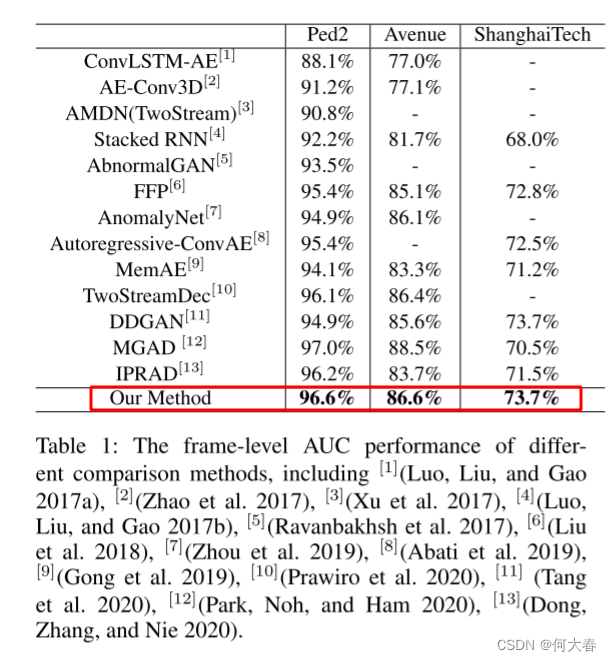
Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读
Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读 AbstractIntroductionRelated WorkMethodExperimentsConclusions阅读总结 论文标题:Appearance-Motion Memory Consistency Network
Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读
Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读 AbstractIntroductionRelated WorkMethodExperimentsConclusions阅读总结 论文标题:Appearance-Motion Memory Consistency Network

-webkit-appearance实现iPad端日历框样式的改变
2012年11月1日 随着iPad的盛行,很多人开始在iPad上看网页,对于携程这样一个旅行网来说,日历控件的使用是必不可少的,然后目前使用自定义的日历控件在iPad上会影响用户的操作(使用input文本框来模拟实现,会弹出键盘导致日历弹出层被覆盖等情况)。解决的方法肯定会有,而且方法应该也挺多的,但对于JS能力不强的我而言,想到的是利用HTML5中的input日历属性值。

论文阅读:“Appearance Capture and Modeling of Human Teeth”
文章目录 AbstractIntroductionMethod OverviewTeeth Appearance ModelEnamelDentinGingiva and oral cavity Data AcquisitionImage captureGeometry capture ResultsReferences Abstract 如果要为电影,游戏或其他类型的项目创建在

论文解读:Splicing ViT Features for Semantic Appearance Transfer
Project webpage: https://splice-vit.github.io Abstruct 将两张图片中语义相近的目标的结构和风格(外观)拼接 • 输入一个 Structure/ Appearence 图像对 : 训练生成器 。 • 关键思想是利用 预训练 和固定的视觉转换器 ( ViT ) 模型( 作为外部语义先验 )。 • 从 deep Vit fe

基于图像的虚拟试衣:Parser-Free Virtual Try-On via Distilling Appearance Flows(2021)
Paper Parser-Free Virtual Try-On via Distilling Appearance Flows 算法比较 WUTON和PF-AFN比较 WUTON 通过训练基于人体分析的老师网络来指导学生网络,让学生网络模拟基于人体分析的老师网络。学生网络输入中除外没有人体分析,老师网络和学生网络结构的输入输出完全相同。PF_AFN 学生网络和导师网络的输入输出完全不

Cesium Primitive报错:Appearance/Geometry mismatch
Cesium 在用Primitive创建对象时报错:Appearance/Geometry mismatch An error occurred while rendering. Rendering has stopped.DeveloperError: Appearance/Geometry mismatch. The appearance requires vertex shader

论文阅读 FAB-MAP 3D: Topological Mapping with Spatial and Visual Appearance
2010_FAB-MAP 3D_Paul_Newman_ 的注释汇总 --------------------------------------------------------------------------------------------------- Abstract 本文介绍了一种使用空间和视觉外观数据进行基于外观的导航和映射的概率框架。 与基于外观导航的最新工作一样,我们
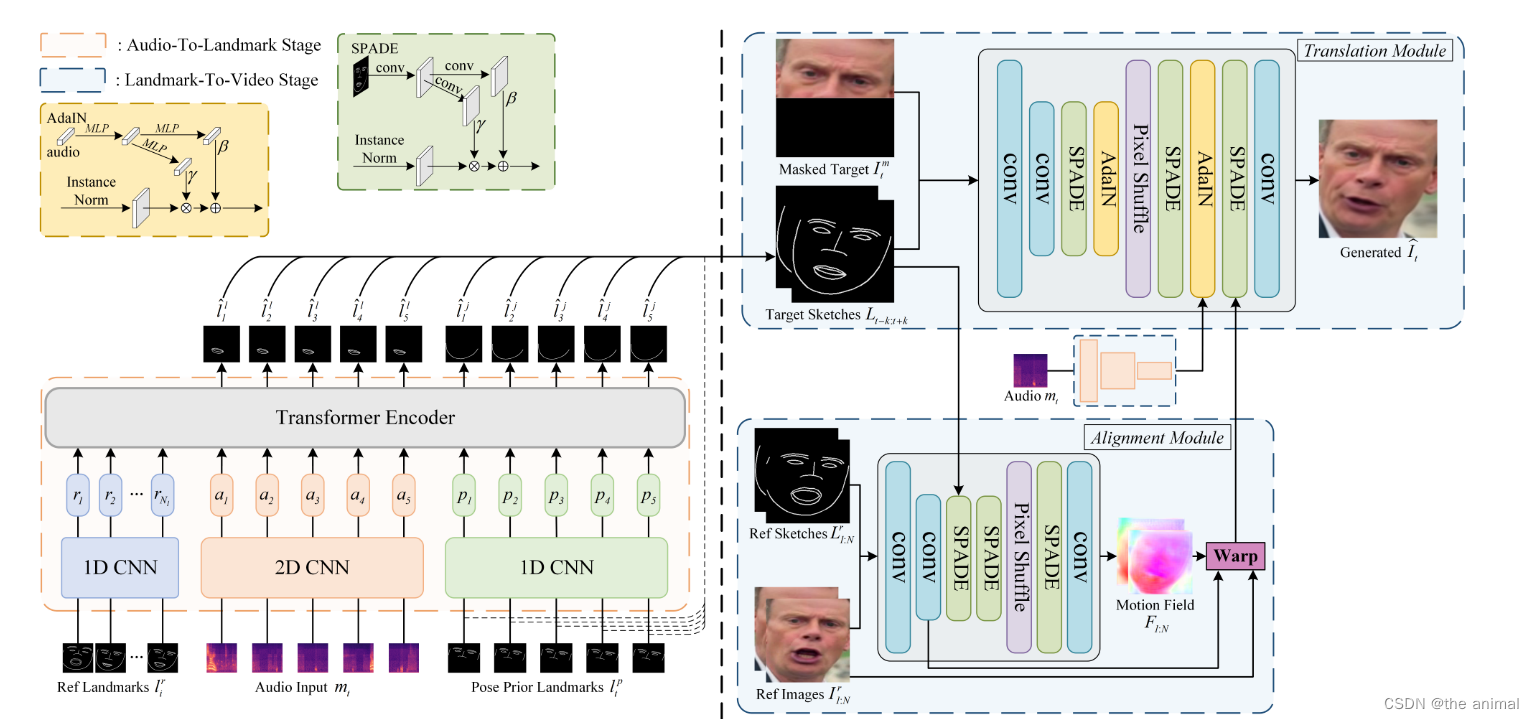
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
主要问题:1)模型如何生成具有与输入音频一致的面部运动(特别是嘴部和下颌运动)的视频?2)模型如何在保留身份信息的同时生成视觉上逼真的帧? 摘要: 从音频生成说话脸部视频引起了广泛的研究兴趣。一些特定个人的方法可以生成生动的视频,但需要使用目标说话者的视频进行训练或微调。现有的通用方法在生成逼真和与嘴唇同步的视频同时保留身份信息方面存在困难。为了解决这个问题,我们提出了一个两阶段的框架,包括从音频
![[23] IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts](https://img-blog.csdnimg.cn/0c0a5f8f5d104f1bb9d42ee6397fd5d4.png)
[23] IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
pdf Text-to-3D任务中,对3D模型外观的控制不强,本文提出IPDreamer来解决该问题。在NeRF Training阶段,IPDreamer根据文本用ControlNet生成参考图,并将参考图作为Zero 1-to-3的控制条件,用基于Zero 1-to-3的SDS损失生成粗NeRF。在Mesh Training阶段,IPDreamer将NeRF用DMTet转换为3D Mesh
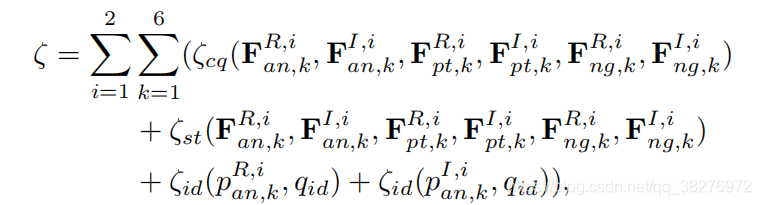
论文阅读25 | Exploring Modality-shared Appearance Features and Modality-invariant Relation Features reid
论文:Exploring Modality-shared Appearance Features and Modality-invariant Relation Features for Cross-modality Person Re-Identification 1.创新点 本文的创新点在于,作者提出表观特征的不同通道关注着人体的不同部位,所以使用三维卷积寻找不同通道之间的关系,即人体部位