本文主要是介绍ReID中PCB模型输出维度_带你入门多目标跟踪(四)外观模型 Appearance Model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
行人跟踪作为MOT中的一个典型的问题,十分具有研究价值,本系列文章以行人跟踪为例来介绍MOT。
在讲解外观模型问题前,首先需要对MOT的各个部件有一个大概的了解。在设计一种MOT算法时,有两点问题需要格外关注。
一是如何测量在视频帧中各目标之间的相似性(measure similarity between objects in frames);
二是如何基于第一点测量出的相似性,进行视频中目标ID的恢复(how to recover the identity information based on the similarity measurement between objects across frames.)。
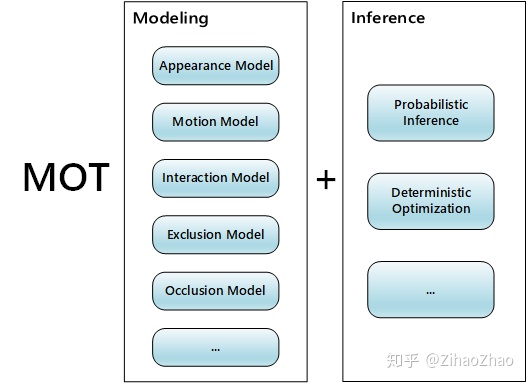
第一点中包括了外观模型、运动模型、交互模型、排斥模型、遮挡模型等(modeling of appearance, motion, interaction, exclusion, and occlusion)。
至于第二点,其实是选取何种推断方式。以往论文里会比较多的使用概率推理(Probabilistic Inference)或确定性最优化(Deterministic Optimization)的方法。
上篇文章讲的匈牙利算法和KM算法就属于Deterministic Optimization中的二分图匹配算法(Bipartite graph matching)。
除二分图匹配以外,Deterministic Optimization中还有很多算法可以应用在MOT中,比如动态规划(Dynamic Programming)、最小费用最大流算法(Min-cost Max-flow)、条件随机场(Conditional Random Field)、MWIS相关算法(Maximum-weight Independent Set)等等。感兴趣的读者可以自行找资料学习。
P.S. 这些术语以英文为准,若发现翻译错误,还请了解的朋友帮忙指正。
这篇文章將针对第一点中的外观模型展开讲解。
作为第一个讲解的部件,外观模型的重要性不言而喻。通俗地讲,外观建模问题就是如何抽取有鉴别力的特征。
”良好的特征会简化问题“ ”特征好了之后,调参的难度会降低一些“ “检测越好,特征越好,跟踪质量就越高”
——某MOT群日常聊天中大佬们常说的话
我个人把外观模型分为两类,一类是深度学习之前的传统方法,通过手工设计算法来抽取特征,比较有代表性的是KLT算法(Kanade-Lucas-Tomasi )。另一类就是深度学习时代的基于CNN抽取特征,许多ReID的网络都能用作这一类的特征抽取器。
学界目前研究重点是基于CNN进行特征抽取,我在这里对第一类只做简单介绍。
1. 手工设计算法抽取特征
以比较有代表性的KLT为例,KTL最早的雏形是Lucas and Kanade 的工作[1] ,之后由Tomasi and Kanade在[2]中进一步发展,之后也是最知名的工作就是Shi and Tomasi 发表在CVPR94上的[3]

其核心思想是寻找一些适合用来跟踪的特征点,根据这些特征点,进行下一步的跟踪。它认为一个好的特征点的定义就是能更容易被跟踪。其原理,简而言之,是通过检查每个2乘2梯度矩阵的最小特征值来定位好的特征,并且使用Newton-Raphson方法跟踪特征,以最小化两个窗口之间的差异。
Reference:
[1] Bruce D. Lucas and Takeo Kanade. An Iterative Image Registration Technique with an Application to Stereo Vision. International Joint Conference on Artificial Intelligence, pages 674-679, 1981.
[2] Carlo Tomasi and Takeo Kanade. Detection and Tracking of Point Features. Carnegie Mellon University Technical Report CMU-CS-91-132, April 1991.
[3] Jianbo Shi and Carlo Tomasi. Good Features to Track. IEEE Conference on Computer Vision and Pattern Recognition, pages 593-600, 1994.
2. 基于CNN提取特征
在深度学习大火的今天,基于CNN的特征抽取获得了比手工设计算法提取特征更好的效果。对于MOT(行人跟踪),一个不错的方法是使用行人重识别(Re-Identification/ReID)的网络作为特征抽取器。行人重识别算法通常提取行人图像特征,对特征进行距离度量,从而判断是否是同一个人。 这些特征就可以用来辅助我们进行行人跟踪。若两个检测框框出的是同一个行人,那么这两个向量的距离会比较小;若不是同一个行人,这两个向量的距离会比较大。

若将这些距离进行可视化,就可以很清晰地看出效果,类似的目标被分在了相近的位置。
读者可以设想,在视频的前后两帧中,我们已经通过目标检测的方法得到了若干检测框,之后把检测结果都通过ReID的网络抽取成特征,如果ReID的网络鉴别力足够高,我们可以判断这些向量相互之间的距离,直接完成所有目标的配对,甚至无需其他MOT组件和Inference过程!
当然,这只是理想情况,虽然ReID能完成行人鉴别的功能,但其效果还不能完美到替代MOT任务。我们可以认为ReID学习到了一些对行人进行鉴别的能力,这种能力可以辅助我们进行多目标跟踪,或者提高我们已有跟踪算法的效果。所以更多时候,在MOT中将ReID的网络作为一个组件,会是一个更合适的选择。
举个例子来简单介绍一下ReID的网络。一个比较经典的方法是使用Triplet loss来训练一个去掉了全连接层的ResNet,最后一层卷积层的输出就是我们需要的特征。
Triplet loss是深度学习中的一种损失函数,用来训练差异性较小的样本,使用锚(Anchor)示例、正(Positive)示例、负(Negative)示例构成一个三元组,通过训练使Anchor与Positive的特征距离减小,使Anchor与Negative的距离增大,通过这种方式来学习出一个对行人有鉴别力的网络。再利用这个网络,就能抽取出我们想要的特征。
ReID目前是一个很火爆的研究方向,各种新文章新结构层出不穷,这里就不做详细介绍了。这些结构基本都可以看成一个特征抽取器,用在MOT上。有兴趣的读者可以自行研究。
值得提醒的一点,建议大家选择模型时,尽量挑选鲁棒性高的模型。个别模型已经在某数据集上严重过拟合,这种模型对于我们是没有太大帮助的,毕竟我们是要将这个模型运用在它从未学习过的数据集上。
若使用ReID数据集进行外观模型的训练,个人建议多使用一些数据集,还可适当加入一些自己收集的数据,这样可以获得鲁棒性更高的模型。我个人习惯是使用Market1501,Duke,CUHK03进行混合,再加入自己的数据来训练外观模型。
当然,还可以采用多种外观模型,再进行各种模型融合,也是很一种很有效的手段。集成学习是当之无愧的刷分大杀器。
对外观模型的介绍基本就是这些,个人认为,只要能用来提取框内目标有鉴别力特征的模型,都可以用作外观模型,用来提高MOT的效果,不仅限于文中介绍到的这些。甚至外观模型这个概念本身,大家都不必太过执着,能抓到耗子的就是好猫,特征为王,能抽到好特征的模型就是好模型。
大家有什么问题可以在下面评论,欢迎交流讨论。码字仓促,文中若有错误还请大家不吝指教,多多包涵。转载请联系作者并注明出处,侵权必究。
这篇关于ReID中PCB模型输出维度_带你入门多目标跟踪(四)外观模型 Appearance Model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





