本文主要是介绍Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读
- Abstract
- Introduction
- Related Work
- Method
- Experiments
- Conclusions
- 阅读总结
论文标题:Appearance-Motion Memory Consistency Network for Video Anomaly Detection
文章信息:

发表于:AAAI 2021(CCF A会议)
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/16177/15984
源代码:https://github.com/NjuHaoZhang/AMMCNet_AAAI2021
Abstract
监控视频中的异常事件检测是一项重要但具有挑战性的任务,已经提出了许多方法来解决这个问题。以前的方法要么只考虑外观信息,要么直接整合外观和运动信息的结果,而不明确地考虑它们的内生一致性语义。受人类从多模态信号中识别异常帧的规则的启发,我们提出了一种外观-运动-记忆一致性网络(AMMC-Net)。我们的方法首先充分利用外观和运动信号的先验知识,明确地捕捉它们在高级特征空间中的对应关系。然后,它将多视图特征相结合,以获得规则事件的更本质、更稳健的特征表示,这可以显著增加异常事件和规则事件之间的差距。在异常检测阶段,我们进一步在潜在空间中引入提交误差和像素空间中的预测误差,以提高检测精度。在各种标准数据集上的可靠实验结果验证了我们方法的有效性。
Introduction
视频异常检测(VAD)是监控视频中的一项关键任务。它已经研究了很多年,但由于收集异常数据的困难和挑战,仍未解决(Kiran、Thomas和Parakkal,2018)。与常规事件相比,异常发生的频率较低,而且异常类型多样,甚至是无限的。因此,收集平衡的正常和异常数据并使用传统的监督二进制分类方法来解决这个问题似乎是不可行的。考虑到视频监控中的常规事件非常丰富,一个普遍的场景(Luo,Liu,and Gao 2017a;Kiran,Thomas,and Parakkal 2018;Liu等人2018;Ionescu等人2019)只是提供的正常数据。
在这种设置下,对规则事件的外观和运动信息进行建模是第一原则。除了独立地表示这两种类型的数据外,对它们之间的对应关系进行建模也是至关重要的。
自然界中存在的一致性定律是一个重要概念,在计算机视觉中得到了广泛应用(Wang,Jabri,and Efros 2019)。与上述使用时间对应关系的工作不同,本文提出的VAD中的一致性明确考虑了对规则事件中的外观和运动信号之间的对应关系进行建模。例如,在超市购物中心的环境中,经常发生的事件是人们向前推购物车或与购物车呆在一起。一些异常可以分别通过外观(火灾爆发)或动作(人们相互打斗)来检测。相反,一些异常需要通过考虑外观和运动之间的相关性来检测。例如,当人们站着不动,购物车在人类无法控制的情况下向前移动时,就会发生异常情况。单从外观上看,人和购物车都是规则的物体,任何不寻常的外观都会发生变化。仅从运动来看,人们站着不动和购物车向前移动都是正常情况。如果不考虑外观和运动之间的相关性,异常检测器可能不可避免地会在这些异常上失败。只有对外观(人、购物车)和运动(人向前推购物车)之间的一致性进行建模,我们才能检测到这些异常,并使异常检测器更加稳健。
然而,先前的方法忽略了VAD中外观和运动之间的一致相关性,包括重建(Hasan等人,2016)、预测(Liu等人,2018)和运动融合(Xu等人,2017;Yan等人,2018;Vu等人,2019)。前两种方法忽略了运动信息,后一种方法在测试阶段直接结合了两种模态的信息。在训练阶段,它没有在同一空间对这两种类型的信息进行联合建模,也没有捕捉到这两种模式的一致性。
为了明确地对外观和运动信息之间的一致性进行建模,我们提出了一种用于视频异常检测的外观-运动-记忆一致性框架。
1) :我们首先学习常规事件中的外观和运动信号的先验信息,并将其存储在两个名为AppMemPool和MotMemPool的内存池中。由于像素空间中有许多与异常检测无关的背景像素,并且原始特征包含样本中存在的特定信息,因此我们选择在特征空间中对这两个特征的先验信息进行建模。考虑到单个存储单元的表示能力不足,我们建议使用多个存储单元来表示查询向量的原型特征。
2) :然后,我们通过学习从AppMemPool引导的特征到MotMemPool指导的特征的两个映射函数,反之亦然,对外观和运动之间的一致相关性进行建模,称为外观-运动特征传递网络(AMFT)。
3) :由于记忆项只包含来自训练数据的先验信息,并且每个输入的唯一信息可能会丢失,为了通过记忆先验来补偿丢失的信息,我们最终集成了来自编码器的初始特征,即记忆模块生成的原型特征,以及来自AMFT的变换后的特征,以形成规则事件的鲁棒性和表达性特征。
4) :在测试阶段,我们结合原始特征和记忆项之间的外观/运动预测误差和提交误差(Den Oord,Vinyals,and Kavukcuoglu 2017)来计算异常分数,并确定帧是否异常。
Related Work
最近,已经提出了大量的方法来解决视频异常事件检测。在(Hasan等人2016;Sabokrou、Fathy和Hoseini 2016)中,基于在常规事件上训练的模型不能重建他们没有看到的异常事件的假设,提出了基于重建的模型。Conv AE(Hasan等人,2016)使用深度自动编码器从训练视频集中重建帧的输入序列。Conv3D AE(Sabokrou、Fathy和Hoseini 2016)使用3D卷积神经网络对视频片段的外观和运动信息进行编码。使用去卷积神经网络来重构输入视频剪辑。提出了一系列基于预测的模型(Luo,Liu,and Gao 2017a;Shi等人2015;赵等人2017)来缓解重建模型中的同一性映射。这些方法将视频帧视为时间模式或时间序列,目标是学习一个生成模型,该模型可以使用过去的帧来预测未来的结构。在(Luo,Liu,and Gao 2017a;Shi等人2015)中,输入视频的卷积表示被输入到卷积LSTM。。然后,去卷积层将所学习的特征的输出重建为原始分辨率。(赵等人2017)提出了一种时空自动编码器(STAE),该编码器利用深度神经网络通过执行三维卷积从空间和时间维度提取特征,重建当前片段并生成未来帧。此外,还提出了一些基于双流网络的模型(Xu et al.2017;Yan et al.2018)来解决异常检测问题。这些方法最初用于动作识别(Simonyan和Zisserman 2014),因为它允许分别对外观和运动信息进行显式建模。在另一项工作中(Vu等人,2019),Hung提出了一种使用强度和运动数据的多级表示来编码规则帧的框架。该检测器可以通过在低级数据之外的高级表示中发现异常对象并结合这些检测结果,以高精度和低错误检测来定位异常区域。更多作品可以在(Kiran,Thomas,and Parakkal 2018)中找到。
与我们的工作最相关的方法是以下三篇论文(Gong等人,2019;Nguyen和Meunier 2019;Xu等人2017)。在(Gong et al.2019)中,提出了一种称为MemAE的内存增强自动编码器,以提高网络的性能。给定一个输入,MemAE首先从编码器获得编码,然后将其用作查询,以检索最相关的内存项进行重建。它试图利用自动编码器架构来重建外观。在(Nguyen和Meunier 2019)中,提出了一种rgb到光流翻译网络,以利用外观与其运动之间的对应关系。它使用U-Net结构来预测给定输入RGB帧的相应运动。(Xu et al.2017)提出了一种将传统的早期融合和后期融合策略相结合的双融合框架。它首先使用堆叠的去噪自动编码器来分别学习外观和运动特征以及联合表示(早期融合)。然后,多个一类SVM模型基于所学习的特征来预测每个输入的异常分数。最后,它使用后期融合策略来组合计算的分数并检测异常事件。与上述方法相比,我们提出的模型可以明确地强制两种模式在训练阶段在共享空间中表示它们的特征,从而有助于异常检测
Method
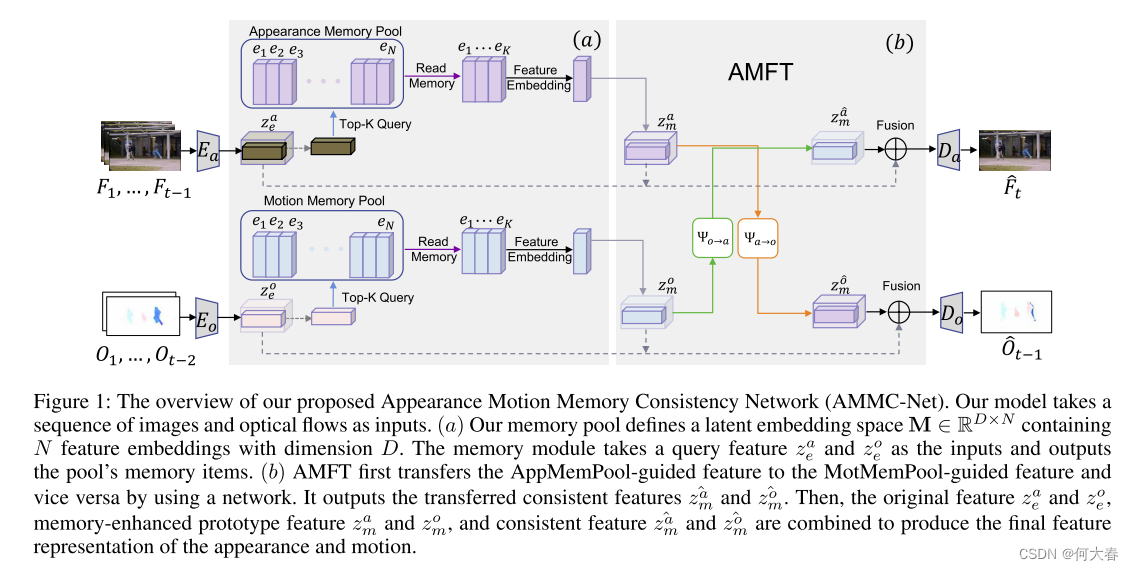
如图1所示,我们提出的AMMC-Net可以分为三个部分:编码器、解码器和外观运动记忆增强特征转移模块(AMMT)。我们首先将图像片段及其光流片段输入到编码器中,以获得外观和运动的初始特征表示。然后,我们将初始特征图输入到内存模块(AppMemPool和MotMemPool)中,以提取这两种模式的原型项目。接下来,我们使用两个神经网络在两个输入原型特征之间传递信息,以获得两个一致的特征。之后,我们在初始特征、记忆引导的原型特征和一致特征之间进行特征融合。最后,将融合的特征输入解码器,以预测未来的外观(图像)和运动(光流),如算法1所示。

Encoder and Decoder
编码器用于从输入视频帧中提取特征表示。解码器被训练为通过获取从先前步骤获得的聚合特征来重构样本。我们采用编码器中使用的res块和类似UNet的跳跃连接结构(Ronneberger、Fischer和Brox 2015)作为骨干网络来构建整个模块。首先,为了增强网络输出的范围和提高表示能力,本文将原来的ReLU修改为Tanh。其次,将原始体系结构的4尺度缩减为3尺度,以控制模型的复杂性,减少参数数量和训练时间。
AMMT
它由三个组件组成,即内存池、特征传输模块和特征聚合模块。存储器池首先提取外观和运动特征的原型模式。然后,我们将这些特征图输入到特征转移模块(AMFT)中,以学习转移的特征。最后,我们聚合编码器特征、记忆先验和传输特征。
-
Memory Pool.
与异常事件类型的多样性和无界性相比,可用于训练的常规事件可以是详尽无遗的。因此,从理论上总结规则模式的先验信息是可行的。然而,原始特征包含正常事件的先验信息及其特定信息。只有先验信息在两种模式之间具有很强的相关性。因此,我们引入了一种具有离散潜在空间的内存模块,并将其与传统的重构模型相结合,以提取原型特征并将其存储在内存池中。具体来说,我们为外观和运动信息设计了单独的内存模块,称为AppMemPool和MotMemPool。我们的记忆模块定义了一个潜在嵌入空间 M ∈ R D × N M∈R^{D×N} M∈RD×N,包含N个维度为D的记忆项。我们将外观和运动记忆池分别表示为 M a M^a Ma和 M o M^o Mo。内存池接收来自编码器的功能, z e a z^a_e zea和 z e o z^o_e zeo作为输入。然后,它计算从编码器到每个存储器项的每个空间特征,并选取K个最接近的项作为存储器先验特征 z m a z^a_m zma和 z m o z^o_m zmo。我们展示了算法1第3行到第6行的整个过程。

-
Appearance-Motion Feature Transfer Module.
我们在记忆先验空间中对外观和运动相关性进行建模。具体地,在接收到存储器先验特征 z m a z^a_m zma和 z m o z^o_m zmo之后,我们首先使用1x1卷积层对先验特征进行特征约简。然后我们应用两个映射函数 Φ a → o Φ_{a→o} Φa→o和 Φ o → a Φ_{o→a} Φo→a,以学习外观和运动先验之间的一致相关性,并获得转移的特征 z ^ m o \widehat{z}^o_m z mo和 z ^ m a \widehat{z}^a_m z ma。整个过程如算法1中从第7行到第10行所示。与之前在特征空间中执行从外观到运动的方法(Vu等人,2019)相比,我们了解到在先验空间中外观和运动之间的一致相关性。因为在记忆空间中,它可以避免复杂背景的副作用,并且直接学习从运动(光流)到外观(图像)的转换是一个病态的问题,因此使用先验信息将使问题更加可行。

-
Feature Aggregation
由于内存项只包含先前的信息,它们将丢失每个输入的唯一信息。为了使特征更具代表性,我们聚合来自编码器的原始特征 z e a z^a_e zea( z e o z^o_e zeo)、记忆先验 z m a z^a_m zma( z m o z^o_m zmo)和转移的特征 z ^ m o \widehat{z}^o_m z mo( z ^ m a \widehat{z}^a_m z ma)。最后,我们将融合的特征输入到解码器中,以预测未来的帧 F ^ t \widehat{F}^t F t和光流 O ^ t − 1 \widehat{O}^{t−1} O t−1。我们在算法1中从第11行到第14行对这些进行了说明。

Loss Function
设F表示rgb图像序列, F ^ \widehat{F} F 表示F的预测,O表示F的相应光流剪辑, O ^ \widehat{O} O 表示O的预测。当给定 F 1 … t − 1 F_{1…t−1} F1…t−1和 O 1 … t − 2 O_{1…t−2} O1…t−2时,模型输出 F ^ t \widehat{F}_t F t和 O ^ t − 1 \widehat{O}_{t-1} O t−1。为了生成更真实的帧,我们在模型中利用了GAN变体(最小二乘GAN(Mao et al.2017))。我们遵循(Mao et al.2017)的原始训练程序进行minmax game。具体来说,我们交替训练生成器和鉴别器。生成器试图产生一个看起来现实的结果,并愚弄鉴别器。鉴别器试图对哪个图像是真实的还是伪造的(生成的)进行分类。
- 训练生成器.
为了训练AMMC-Net的生成器,我们分别从外观和运动信号的像素空间和特征空间构造以下损失函数。
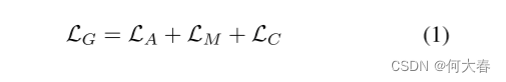
对于外观,我们采用强度、梯度、流量和对抗性损失(分别为 L i n t L_{int} Lint、 L g d l L_{gdl} Lgdl、 L o p L_{op} Lop和 L a d v G L^G_{adv} LadvG)。
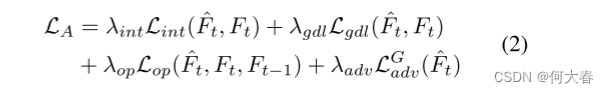
其中超参数 λ i n t λ_{int} λint、 λ g d l λ_{gdl} λgdl、 λ o p λ_{op} λop、 λ a d v λ_{adv} λadv用于调整每个部分的重要性。
我们采用 l 2 l_2 l2的距离,以最小化强度空间中预测帧 F ^ \widehat{F} F 与真实值 F F F之间的损失:
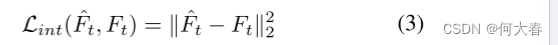
为了锐化图像预测,随后(Mathieu,Couprie,and Lecun 2016),在我们的损失函数中采用了梯度损失。它直接惩罚预测与其基本事实之间的图像梯度的差异:
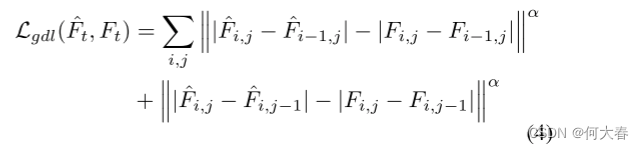
其中i,j表示视频帧的空间索引,α可以调整预测图像的清晰度。
为了保持运动的一致性,这对VAD至关重要,我们采用了运动约束损失(Liu et al.2018)来强制预测帧之间的光流接近真实帧:
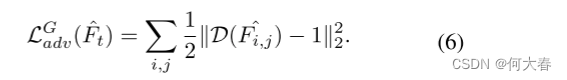
对于运动,我们应用平滑的 l 2 l_2 l2损失,如方程(7)所示,因为它更适合于光流的高稀疏性(Girshick 2015):
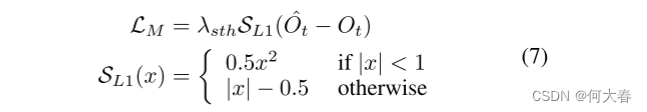
为了优化内存模块(AppMemPool和MotMemPool),我们将外观 z e a z^a_e zea和运动 z e o z^o_e zeo的查询特性推至接近所选内存项 e a e_a ea和 e o e_o eo的查询特性,如下所示:
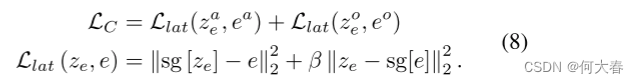
由于在我们的内存网络中存在不可微分的argmax操作,我们遵循停止梯度技巧sg(Bengio,Leonard,and Courville 2013;Den Oord,Vinyals,and Kavukcuoglu 2017)来处理损失反向传播。这里,β表示两种损失项目的重量。 - 训练判别器
为了迫使生成器学习正态分布,鉴别器试图将基本事实帧分类为真帧,将预测帧分类为假帧。在这里,我们遵循LSGAN(Mao et al.2017),如下所示:
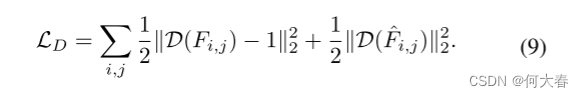
Anomaly Detection in Testing Data - Memory Commit Error
由于我们已经了解了内存中常规事件的先验知识,异常可能从查询特征 z e a z^a_e zea到内存原型 z m a z^a_m zma有很大的距离,而正常模式会导致较小的距离。我们使用内存提交错误来测量距离,如下所示:
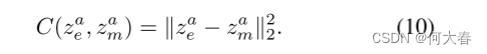
第th帧的低错误表示它更有可能是正常的。 - Image Prediction Error
大量相关工作(Liu et al.2018)表明,与相同情况下的MSE相比,PSNR可以增加正常和异常事件之间的差距。因此,我们在我们的方法中采用了PSNR。
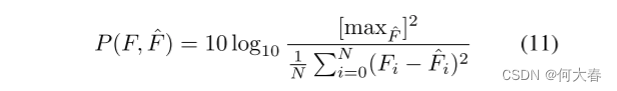
- Anomaly Score
许多以前的方法(Nguyen和Meunier 2019)只将像素空间中的误差视为异常指标,忽略了特征空间中的错误对异常检测的影响。我们的AMMC网络弥补了这一缺陷。在测试阶段,结合潜在空间中的内存提交误差和像素空间中的图像预测误差,我们可以确定一个案例是否是异常。最终的正常分数可以推导如下:
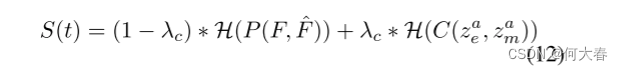
其中 λ c λ_c λc表示两种类型误差之间的权重。H表示基于最小-最大的归一化操作,我们将整个测试视频中所有帧的两种类型的误差归一化到范围[0,1]。
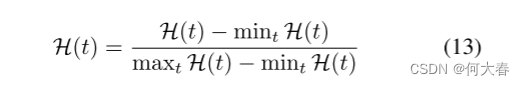
因此,最终的 S ( t ) S(t) S(t)表示特定帧的法线程度。越大越正常,越小越异常,我们可以通过选择阈值来确定特定帧是正常还是异常。
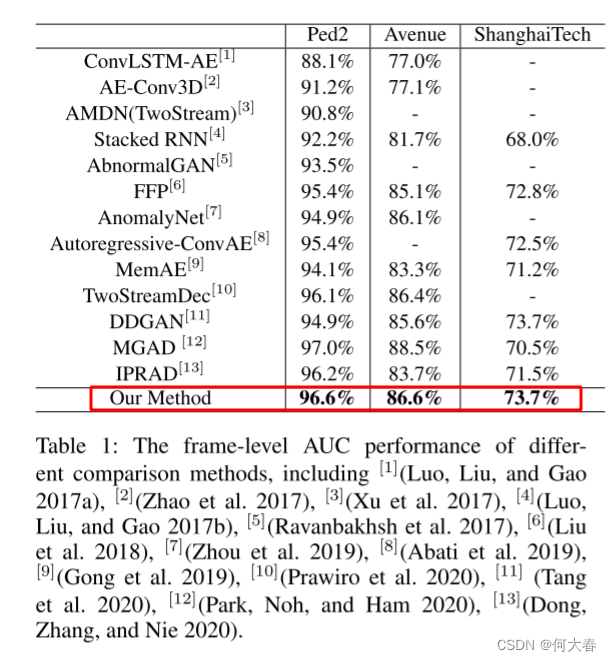
Experiments
Conclusions
在本文中,我们对外观和运动之间的一致性进行建模,以解决视频异常检测问题。我们首先优化外观和运动预测网络来构建两个内存池。然后,我们使用外观-运动特征转移(AMFT)网络来实现外观和运动模式之间的通信和融合操作。在测试阶段,给定由图像及其光流组成的输入序列,使用AMFT从AppMemPool和MotMemPool中提取外观运动特征。最后,我们将像素空间中的预测误差与特征空间中的提交误差相结合,计算测试帧的得分。与现有技术相比,许多实验证明了我们的方法的有效性。固体消融研究证明了我们提出的AMMCNet在捕捉视频异常检测的外观和运动之间的一致性方面的有效性。
阅读总结
1:运动外观一致
2:Memory模块
这篇关于Appearance-Motion Memory Consistency Network for Video Anomaly Detection 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









