本文主要是介绍[23] IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

- Text-to-3D任务中,对3D模型外观的控制不强,本文提出IPDreamer来解决该问题。
- 在NeRF Training阶段,IPDreamer根据文本用ControlNet生成参考图,并将参考图作为Zero 1-to-3的控制条件,用基于Zero 1-to-3的SDS损失生成粗NeRF。
- 在Mesh Training阶段,IPDreamer将NeRF用DMTet转换为3D Mesh,并分别优化Mesh的几何与纹理。1)用参考图的法向图编码作为控制信号,用IPSD (Image Prompt Score Distillation) 优化3D Mesh的几何;2)用渲染rgb图像编码(和法向图差异)作为控制信号,用IPSD优化3D Mesh的纹理。
- 将Text-to-3D任务,转换为单图重建任务,实现了更好的外观控制。

目录
Method
NeRF Training
Mesh Training
Experiments
Some Results
编辑Comparison with SOTA Text-to-3D Methods
Method
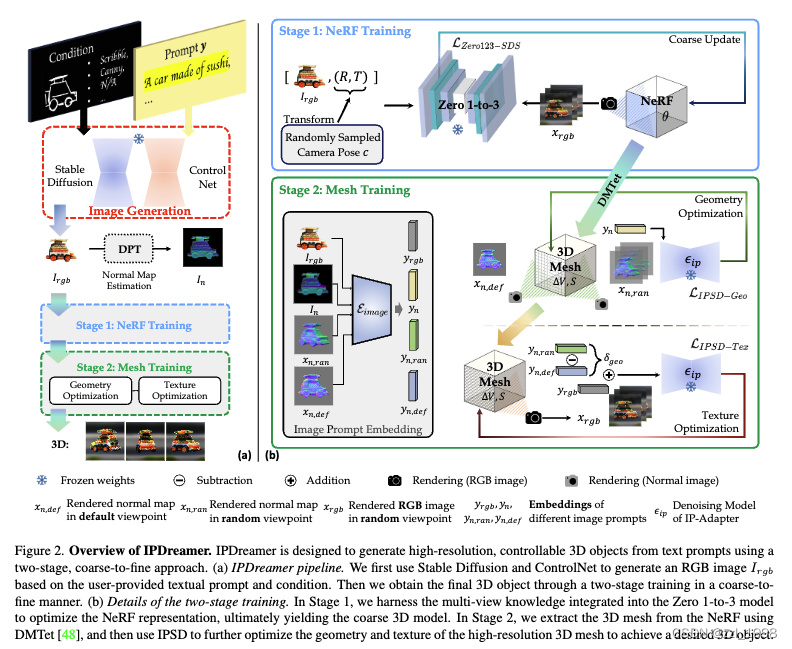
NeRF Training
- Image Generation. 给定文本描述和控制条件,本文用ControlNet生成参考图片。
- Training of the Coarse NeRF Model. 给定参考图片,本文用基于Zero 1-to-3的SDS损失生成粗NeRF。
Mesh Training
- Mesh Extraction. 给定粗NeRF,本文用DMTet将其转换为3D Mesh。3D Mesh由顶点V和四面体T(tetrahedrons)组成。每个顶点包含一个signed distance field (SDF) 值
和形变值
组成。
描述了相较于初始正则坐标的变换。本文基于IPSD优化
。
- Geometry Optimization. Fantasia3D和ProlificDreamer用SDS优化3D Mesh的法向图,实现几何优化。但常用扩散模型缺少法向图的训练数据,导致几何优化效果不佳。为解决该问题,本文引入法向图编码
,其中
是IP-Adapter的denosing model。IPSD几何损失表达如下:
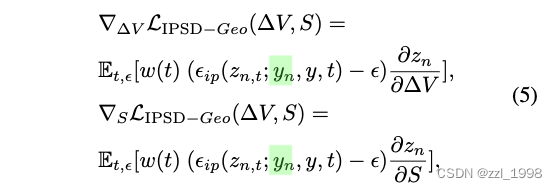
- Texture Optimization. 首先,提取参考图像编码
。其次,计算渲染角度和参考角度的法向图编码,并计算差值得到
。这一步的目的是希望用
来表征任意渲染角度图像的图像编码。IPSD纹理损失表达如下:
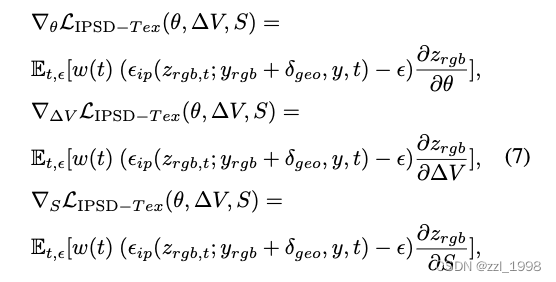
Experiments
Some Results

Comparison with SOTA Text-to-3D Methods

这篇关于[23] IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





