本文主要是介绍论文阅读 FAB-MAP 3D: Topological Mapping with Spatial and Visual Appearance,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2010_FAB-MAP 3D_Paul_Newman_ 的注释汇总 ---------------------------------------------------------------------------------------------------
Abstract
本文介绍了一种使用空间和视觉外观数据进行基于外观的导航和映射的概率框架。 与基于外观导航的最新工作一样,我们采用词袋方法,其中使用场景中视觉单词的正面或负面观察来区分已访问的地方和新的地方。
在本文中,我们为该方法添加了重要的额外维度。 我们明确地将视觉词的空间分布建模为随机图,其中节点是视觉词,边缘是距离分布。
至关重要的是,这些词间距离是视点不变的,并共同构成了强烈的场所特征,因此,显着影响了使用空间和视觉外观的影响 简而言之,我们想让一个机器人用图形表示其轨迹的拓扑表示,其中每个节点是一个不同的位置,边表示位置之间的过渡 在这项工作中,我们提供并测试一种配方,该配方不仅使用场景的视觉外观,还使用其几何形状的各个方面。
I. INTRODUCTION
简而言之,我们想让一个机器人用图形表示其轨迹的拓扑表示,其中每个节点是一个不同的位置,边表示位置之间的过渡 在这项工作中,我们提供并测试一种配方,该配方不仅使用场景的视觉外观,还使用其几何形状的各个方面。
FAB-MAP的本质在于,它使用视觉单词观察的生成模型和解释视觉单词遗漏观察的传感器模型,在线学习场景外观的概率模型。
我们在这项工作中采用了相同的方法,但是增加了复杂性,即单词之间的空间范围的观察与视觉单词对的观察相结合 我们必须强调,尽管在整个工作中,我们只需要可以在局部帧中得出的场景内距离,而在任何地方我们都不需要一幅度量世界的图片。
II. RELATED WORK
在计算机视觉中探索了使用形状和空间信息进行对象识别和分类
Burl等。 [4]介绍了将对象描述为一组以可变空间配置排列的特征部分的星座模型。 后来[13]将其用于类别级对象识别。
Ranganathan等。 [21]扩展了用于识别移动机器人室内工作空间的模型。 他们提出了一种针对室内场所的3D生成模型,该模型使用通过其形状和外观建模的对象以及使用立体摄像机的深度获取的特征位置进行建模。
属性和随机图的概念由[27]提出,他们将它们应用于结构模式识别。 [23]将该框架推广到功能描述的图形,并将其应用于室内机器人应用的2D视图对象识别。
也有一些基于外观的映射和闭环检测相关研究 Konolige等。 [16]提出了一种拓扑映射方案,基于视图的地图,在立体视图中使用几何特征匹配并维护词汇树[20]来检查闭环候选者。 Milford和Wyeth [19]使用受生物启发的技术描述了基于外观的大规模导航实验 。阿普斯等。 [26]通过指纹(基于多模态特征的表示,例如来自相机的色箱和来自激光扫描仪的角)来放置模型,并使用POMDP(部分可观察的马尔可夫决策过程)进行映射和全局定位。 在[1]中,Angeli等人。 提出了一种使用袋字法与对极几何检查相结合的增量式闭环检测方案。
III. RANDOM GRAPH LOCATION MODEL三, 随机图形定位模型
移动机器人收集环境的图像和范围观测值,并计算观测值来自拓扑图中已知位置或来自新地点的概率。
对于视觉数据,我们采用词袋表示法[24],其中图像表示为大小为| v |的词汇或属性的集合。 此外,我们假设车辆配备了距离测量传感器,例如激光测距仪或立体摄像机,该传感器可提供场景中检测到的视觉特征相对于车辆的3D位置1 每个位置均建模为随机图Lk = {Ek,Hk}, 其中,Ek表示随机顶点集{ei | 1≤i≤| v |},其中二进制变量ei表示事件 :第i个单词存在于location2中。 位置的外观以集合{p(e1 = 1 | Li),… p(e | v | = 1 | Li)},表示,含义是指在这个地点,每个单词出现的概率估计。
Hk是随机弧集{hij | 1≤i,j≤| v |},其中hij是第i个单词与第j个单词之间的3D空间中欧氏距离上的离散概率分布(直方图)。这些分布通过保持对所有成对单词(包括相同类型的单词)之间距离的信任来捕获位置的空间外观(有关详细信息,请参见第IV节)。
局部场景的观察由图形Gk = {Zk,Dk}表示,其中Zk是向量z1,…。 。 。 ,z | v | ,其中每个zi是一个二进制变量,指示场景中词汇第i个单词的存在(或不存在)。
Dk是在词对之间观察到的空间距离的集合,包括在相同类型的词之间感知到的距离。 令cij为第i个单词与第j个单词之间观察到的所有成对距离的计数。
请注意,当第ith个单词和/或第j个单词多次出现且cij为零(当未观察到任一单词)时,cij超过1。
Note that cij exceeds one when either ith and/or the jth word occurs multiple times and cij is zero, when either word is not observed.
形式上,观察到的空间距离Dk可以表示为{dnij | 1≤i,j≤| v |,1≤n≤cij}。
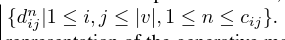

图1:生成模型:位置独立生成对象特征ei,该特征产生观测值,由视觉传感器(顶部)检测到。 存在单词观察的一阶相关。 另外,位置在单词对距离hij上具有分布,hij引起以每个单词对(底部)的观测值zi和zj为条件的观测距离。 该模型包括多个单词出现的距离观测
图1提供了位置生成模型的表示。
位置L独立生成对象特征,ei产生观测值,zi被视觉传感器检测到。
一个基于外观的传感器检测模型,Detvisual,把存在的外观特征变量和检测到的特征变量链接起来。
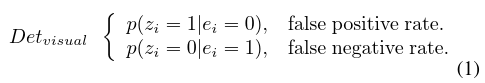
此外,每个位置在单词上都有分布对hij,这导致了测得的距离dij。
范围测量过程中的不确定性以高斯条件密度Detrange建模,该条件密度以hij的离散范围为中心,并由方差σrange进行参数化。
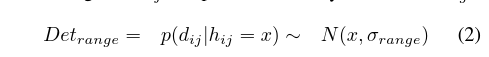
IV. LEARNING DISTRIBUTIONS OVER WORD DISTANCES
一个地点的空间外观以单词距离上的概率分布为特征(图3)。
 图3:一个示例,显示了带有三个场景(正方形,三角形和圆盘)的平面场景(顶部)的空间模型。 成对距离的分布如下所示。 请注意,该图未按比例绘制。
图3:一个示例,显示了带有三个场景(正方形,三角形和圆盘)的平面场景(顶部)的空间模型。 成对距离的分布如下所示。 请注意,该图未按比例绘制。
户外移动机器人观察到的视觉单词可能会出现很大的距离变化,例如,在树叶上检测到的特征通常会在很短的距离内看到,而在重复结构(如砖墙或栏杆)上的特征可能会显示出很大的变化(多模式行为)。
为了重现这些复杂的多峰分布,我们采用非参数直方图表示。
正式地,令Lmax为场景中任何两个单词之间的最大距离。这通常是测距传感器的最大范围。
将连续范围细分为bins,bk,每个长度,Δ,并令R为每个直方图中bin的总数(R = Lmax/Δ)
下面的概率表示出现bk这样的点对距离的概率。
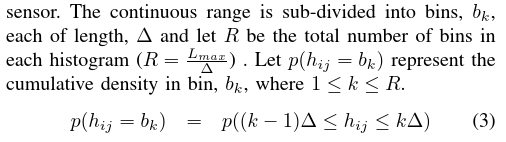
给定从训练数据中观察到的词间距离,通过核密度估计(KDE)估计每个bin中的概率质量[14]。在这种方法中,通过以训练数据{xi} i = 1 … N为中心的核函数的线性组合来估计点x的密度,样本{xi}为i.i.d根据基本分布。
核K(u)满足K(u)≥0且积分K(u)du = 1的条件。使用最广泛的核是均值和单位方差为零的高斯,其KDE可写为:
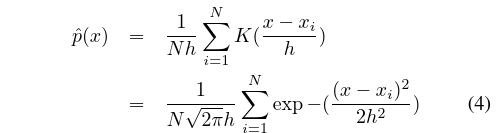
核函数的特征在于确定模型准确性的带宽(h)。 内核太窄会导致过度拟合,而非常宽的带宽会导致未拟合[14]。
已经提出了许多技术用于数据驱动的带宽选择。 这些方法使估计值pˆ(x)与实际密度p(x)之间的渐近积分平均积分平方误差(AMISE)最小化。
最成功的方法取决于通过求解方程插件方法[22]来估计密度导数泛函。

我们基于改进的快速高斯变换(IFGT)[28],使用一种高效的精确精确逼近算法来实现最佳带宽估计,其计算复杂度在训练点数量上呈线性关系。
一旦估计了最佳带宽,方程式4将用于计算每个直方图bin的概率。3
原文备注
这里还有进一步工作的余地。 由于距离是非负的,因此可以使用具有正支持的核(例如γ核)进行密度估计,其中可以通过期望最大化来学习混合参数[5]。
有时由于训练数据有限,稀有单词对的范围样本很少。 这种采样误差可能会导致某些直方图分区中的概率估计值可以采用0或1的简并值。为了减轻这种影响,必须对最大似然概率估计值进行平滑处理,然后重新归一化。
存在多种平滑技术[11],通常采用等式5的形式。
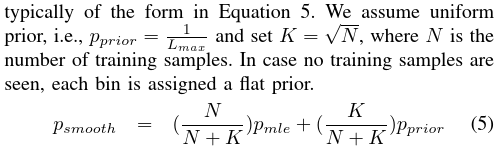
V. PROBABILISTIC NAVIGATION AND MAPPING
A. Estimating Location
在时间k,将工作空间建模为nk个离散位置和不相交位置的集合Lk = {L1,…。 。 。 ,Lnk}。
给定每个位置的随机图模型,我们计算每个位置Ln生成观察图的概率。
意思就是说,给定一个位置的随即图模型,需要根据这个随机图模型,计算这个地点是地图中各个位置的概率

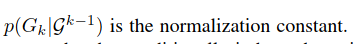
归一化常数。
假定观测值是条件独立的给定位置,那么有近似的

由地点的观察生成图有两方面因素:

使用Chow-Liu近似[6]等式8扩展视觉外观似然项。此扩展通过最近的树结构贝叶斯网络近似离散的关节分布p(z1,z2,…,z | v |) 根据Kullback-Leiber(KL)散度标准。 在这里,zr是树的根,zpq是Chow-Liu树中zq的父级。 这些因素可以进一步用先验概率,距离检测器模型和训练数据中的条件表示(在[7],[9]中有详细说明)。
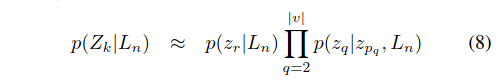
这里展开有点不明白,需要具体看一下chow-Liu中的方法

如果已有一条边两端点的观察,可以认为图中的这个成对单词构成的距离边与其他的边无关。

距离的概率有以下部分因素:
从直方图中获得的先验概率
给定观察模型下观察到这个距离的概率。
B. Evaluating the Normalization Term
归一化项p(Gk | Gk-1)是观测值Gk的总似然。 观测值可以来自机器人地图中当前的位置集(M),也可以来自所有先前未知的位置(M非)。 因此,p(Gk | Gk-1)可以表示为和:
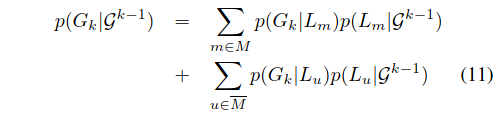
第二项涉及所有未映射位置的求和,无法直接计算。
构建平均位置模型Lavg =(Eavg,Havg),可以通过平均位置模型[15]来近似求和。
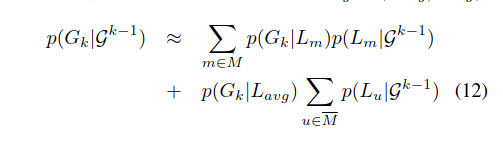
如[9]中所述,平均场近似的一种更好的替代方法是基于采样的近似。 当前的实现方式使用均值域方法,这是因为缺少构建采样集所需的具有可视性和范围数据的大型代表性数据集。
计划收集更大的数据集,作为未来工作的一部分。
通过从训练数据中分配ei变量其边际概率来构造平均位置Eavg的视觉外观部分。 同样,平均位置的空间外观Havg是每个单词对的一组边际直方图,其中每个直方图都是从训练数据中观察到的所有成对距离样本中学到的密度估计值。
这种表述还解决了感知混叠问题:环境的不同部分对于机器人的传感器而言看起来是相同的。 例如,在户外航行时,通常会出现外观相似的树叶和砖墙。 普通地方的外观模型可以了解环境中共有哪些特征,例如出现在树叶上的单词具有较高的边际概率。
此外,平均位置的空间外观模型可了解单词通常出现的距离。
因此,可以得知在砖墙上检测到的特征通常以重复的距离出现。 总体而言,仅当视觉和空间外观都与众不同时,系统才会将观察结果与位置匹配。
c Updating Location Model
使用平均位置模型初始化拓扑图中的新位置,
1 word generators exist with
marginal probability, p(ei = 1|Lnew) = p(ei = 1)
2 word pair histograms are initialized to marginal histograms,
p(hij = br|Lnew) = p(hij = br).

一个新地点是以上面的方式进行初始化的
1单词出现
2单词对的距离分布为原始分布,原始分布br是通过哪种方式得来的呢?从训练数据中的直方图中获得。
当观察到的图形与地图中的某个位置相关时,该位置的随机图形模型将根据当前的信念和传感器模型进行更新。
1 更新 单词的出现概率

2 更新单词对的分布

此步骤假定对单词的观察或单词对之间的观察距离不会传达有关其他单词的存在或成对距离的信息。 观测值和位置的数据关联决策基于最大似然准则。
仅当闭环概率超过用户定义的阈值paccept = 0.999时,闭环才被接受。
VI. ACCELERATING GRAPH LIKELIHOOD COMPUTATION
在给定场景中,令Nf为检测到的视觉单词的总数。 在计算空间似然项p(Dk | Zk,Ln)时,我们计算成对距离Nf(N2f-1)≈O(Nf2)的各个距离似然。 本质上,考虑的是3D图形的所有距离边缘,并根据等式13更新了O(Nf2)直方图。
这个复杂度比较高
但是,在工作空间中检测到的特征源自通常具有较高局部空间相关性的对象,例如在窗口上检测到的特征。 同样,相隔较大距离的要素在空间上的相关性较低。 使用这种直觉,我们只考虑到相邻点的距离,其中相邻意味着我们在Voronoi细分中的单元共享边的一对点。
形式上,我们计算3D图的Delaunay细分,从而将图划分为四面体(单纯形),从而在单纯形的任何周界中均不包含数据点[12]。
>
周围环境的条件可防止镶嵌细分返回倾斜的四面体,从而有效地将点连接到本地邻居。
我们将图似然性计算仅限制在棋盘形图的边缘,该图的缩放比例将O(Nf)与完整图的O(Nf2)进行比较。
>其实是说复杂度降低了
我们使用基于Qhull6(一种标准的计算几何包)的实现来计算镶嵌[2]。 3D Delaunay细分算法具有O(Nf logNf)复杂度[2]。 在某些情况下,由于数字问题或重合点而导致不存在有效的细分。 在这种情况下,我们可以使用最近邻准则来选择相关的边。
在[18]中出现了对3D Delaunay镶嵌的几种实现的实验评估。
VII. EVALUATION
A. Platform and dataset
测试了拓扑映射算法,对来自移动机器人的图像和激光数据进行了测试,如图4所示。
从Point Grey Ladybug 2相机以3Hz的频率捕获图像,并从SICK LMS291激光器获得激光数据,并以0.5°的分辨率在75Hz的条件下扫描90°。 激光器的安装位置使其可以在垂直于车辆前进方向的垂直平面内进行扫描。 相机和激光器经过实验交叉校准。 数据集收集在牛津大学新学院的一个中世纪建筑环境中,其中包括椭圆形的草坪和弯曲的柏油碎石地面[25]。 该网站具有重复性的建筑功能,会引起感知混淆,并且也会被人们遍历,从而测试了系统对场景变化的鲁棒性。
这里不重要
B. Processing pipeline
首先提取SURF特征[3],然后将其相对于固定的词汇量进行量化,以获取图像的视觉单词,从而将每个图像转换为单词袋表示形式,从而得出Zk。通过聚类从训练图像获得的SURF特征来生成词汇,聚类中心对应于词汇视觉单词。 词汇量为10K个单词。 SURF描述符还确定检测到特征的比例,因此近似图像空间中的特征尺寸。
下一个任务是确定场景的单词间距离。 在图像捕获时间附近的16秒窗口中获得的激光扫描被反投影到相机视图中。对于在图像中检测到的每个视觉单词,确定在等于特征尺寸的半径内的近激光点(来自SURF描述符)。 通过获取搜索半径内所有附近激光点的3D坐标的反径向加权平均值,为视觉单词分配3D坐标。 因此,我们现在知道了视觉单词在3D空间中的位置,并且可以确定形成集合Dk的成对距离。 然后将所得的观察图Gk = {Zk,Dk}传递到推理引擎。
下一步是通过[9]中概述的过程构建Chow-Liu树来构建词汇模型。 它包括使用训练集中的单词共现数据构造互信息图,然后计算最大权重生成树。 边际成对距离直方图是从400个图像的训练集中确定的。 尽管所有成对距离直方图的集合都很大(10K×10K),但观察到的同时出现的数量相对较少,即557491个单词对。 对于其他对,假定范围上有统一的先验。 由于单词共现矩阵非常稀疏,因此推理所需的直方图数量很容易处理。 为了提高空间效率,仅保留边际词对直方图的单个全局副本。 在初始化新的地点模型时,只有修改后的距离直方图会在本地保留。
 最后的要素是探测器模型。 对于视觉检测器,p(zi = 1 | ei = 0)= 0,p(zi = 0 | ei = 1)= 0.39。 范围检测器的方差σrange设置为1.5m。 尽管如[17]所述,LMS激光扫描仪的距离不确定度(对于近距离)约为3cm,但距离检测器模型还包含(i)由于车辆里程误差引起的不确定性,这些误差会影响激光扫描投射到所拍摄的图像空间中 在成像时间之前或之后几秒钟,以及(ii)交叉校准激光测距仪和照相机时出现轻微错误。
最后的要素是探测器模型。 对于视觉检测器,p(zi = 1 | ei = 0)= 0,p(zi = 0 | ei = 1)= 0.39。 范围检测器的方差σrange设置为1.5m。 尽管如[17]所述,LMS激光扫描仪的距离不确定度(对于近距离)约为3cm,但距离检测器模型还包含(i)由于车辆里程误差引起的不确定性,这些误差会影响激光扫描投射到所拍摄的图像空间中 在成像时间之前或之后几秒钟,以及(ii)交叉校准激光测距仪和照相机时出现轻微错误。
C results
这里是一些分析的结果讲解
VIII. CONCLUSIONS
本文介绍了基于外观的拓扑映射的概率框架。 在这种表述中,位置被表示为随机图,并且根据单词出现及其空间分布来学习生成模型。 与现有的FAB-MAP系统相比,此方法在精确调用性能方面提供了显着且令人信服的改进。 通过捕获空间信息,该算法减少了误报的数量,并显着降低了误报率,特别是在具有大量常用词的场景中,其中闭环决策取决于空间信息。
该框架显示了对感知混叠以及场景变化的鲁棒性。 系统随着地图上的地点数量线性缩放。 我们还提出了一种基于观察到的图的Delaunay细分来加速图推理的方法,该方法可以随着场景复杂度线性对数缩放。
个人总结
这个方法不仅仅考虑了视觉特征,还考虑了视觉特征的距离,
根据训练数据建立视觉特征和3D距离的先验分布,然后根据这个分布进行重定位或闭环检测。
问题
地点是如何确定呢? 每一个图像帧都是一个地点么?还是根据各个显著不同确定一个新地点?
这里的方法只是一个框架,而具体一个地点如何确定应该是一个SLAM系统中确定的。
FABmap 相关
https://github.com/arrenglover/openfabmap
在不同的视觉定位方法中,位置识别通常是一个关键阶段,因为它提供了关于所穿越环境的态势感知的有价值的信息。此外,在视觉导航系统中,为了纠正累积的定位误差,它通常用于检测环路闭合和识别重访位置。如williams等人所述。(2009)将求解视觉定位中环路闭合问题的算法分为三组:映射到映射(metric)(Clementeetal.2007)、图像到映射(topometric)(Williams等人,2008)和图像到图像(topotopic)(Cumminsand Newman 2008)。
FAB-MAP (Cummins and Newman 2008)的提出使得视觉定位的拓扑方法得到了普及。FAB-MAP只利用视觉外观的空间来识别位置。然而, FAB-MAP需要一个预先的训练阶段,并且采用了一种计算开销很大的方法,这种方法需要特征提取,然后进行概率推理,这使得该建议不适合实时应用。此外,视觉定位是复杂的,在长期的操作周期,由于强烈的外观变化,一个地方遭受动态因素,照明,天气或季节,可以观察到的例子,图1所示。因此,终身视觉拓扑定位是近年来机器人学中最具挑战性的课题之一,提出的解决方案不仅要解决与环境变化相关的问题,而且要应用低计算量的高效算法。在实际情况下有效的成本。根据所描述的要求,图1描绘了我们的方案的总图,称为able(能够进行二进制外观环路闭合评估)
————————————————
版权声明:本文为CSDN博主「Orange Wu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44470443/article/details/100652654
虽然fab-map可以看作是视觉拓扑定位研究中的一个里程碑,但这类技术的初步研究早在几年前就开始了(ulrich和nourbakhsh 2000)。此外,根据Fab-Map的研究路线,已经提出了大量新的方法,如Garcia Fidalgo和Ortiz(2015)或Lowry等人的调查所研究的。(2016年)。事实上,fab-map的作者在最近的论文(cum-mins和newman 2010a,b)中也对他们的算法进行了1000公里的测试,这可能是文献中第一个鲁棒的终身视觉拓扑定位方法。此外,fab-map(paul和newman 2010)的3d实现也有助于合并几何信息,但在这种情况下,它只在短期本地化中进行了测试。
————————————————
版权声明:本文为CSDN博主「Orange Wu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44470443/article/details/100652654
这篇关于论文阅读 FAB-MAP 3D: Topological Mapping with Spatial and Visual Appearance的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




