本文主要是介绍NestedFormer:Nested Modality-Aware Transformer for Brain Tumor Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NestedFormer: Nested Modality-Aware Transformer for Brain Tumor Segmentation
NestedFormer:嵌套的模态感知transformer在脑肿瘤分割中的应用
MICCAI 2022
多模态磁共振成像通过提供丰富的互补信息,在临床实践中经常被用于诊断和研究脑肿瘤。以前的多模态MRI分割方法通常是在网络的早期/中期通过串联(cat)多模态MRI来执行模态融合,这很难探索模态之间的非线性依赖关系。在这项工作中,我们提出了一种新的嵌套的模态感知transformer(NestedFormer)来显式地探索用于脑肿瘤分割的多模态磁共振成像的模态内和模态间的关系。在基于transformer的多编码器和单解码器结构的基础上,我们对不同模态的高层表示进行嵌套的多模态融合,并且在较低的尺度上应用模态敏感门控(MSG)以实现更有效的跳层连接。具体地说,多模态融合是在我们提出的嵌套的模态感知特征聚集(NMaFA)模块中进行的,该模块通过一个三维的空间注意力transformer来增强单个模态的长距离相关性,并通过跨模态注意力transformer进一步补充模态之间的关键上下文信息。在BraTS2020基准和私有的脑膜瘤分割(MeniSeg)数据集上的广泛实验表明,NestedFormer明显优于最先进的分割。
要解决的问题
- 以前的多模态MRI分割方法难以探索模态之间的非线性依赖关系,这项工作探索不同模态数据更有效的融合方案
- 常见的视觉transformer,尤其是3d的,参数量和计算量都太大
Method

1.Global Poolformer Encoder
- 参考了Poolformer,MetaFormer is Actually What You Need for Vision
- Poolformer认为用平均池化代替transformer中的计算密集型注意模块
- Global Poolformer Block(GPB),


2.Nested Modality-Aware Feature Aggregation

- spatial- attention based transformer
- 空间注意力transformer,利用自注意力来计算每个模态内不同patch间的长距离相关性
- 这里不是直接F1+F2+…+Fm=(D,W,H,C),而是先cat再map,可能是利用patch embedding layer来加一层权重来区分不同模态不同通道的重要性
- Ttsa参考了Axial Transformer和Swin Transformer,采用了MHAz、MHAxy、MHAw多头注意力方案,MHAz注重垂直方向,MHAxy注重每个切片内,MHAw注重3d窗口建模
- 最后输出为空间增强特征Fs(D,W,H,C)
- cross-modality attention based transformer
- 使用跨模态注意力机制计算不同模态之间的全局关系来实现模态间融合
- 从(M,D,W,H,C)经过Token Learner到(M,P,C),从(D,W,H)到P的原理,需要看TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?论文,该方法大大减少了计算量
- 将Fs(来自Ttsa模块)和Fc一起输入到Tcma,得到最终模态增强的特征F
- 两个transformer块不同于以往的通道、空间注意力,是以嵌套形式进行融合,而不是串联或并联融合
考虑使用axial attention来实现针对性的attention,使用在不同分支特征的融合模块中,针对各个方面进行attention,对比目前已知的融合方案aspp等等,
-
Transformer with Tri-orientated Spatial Attention
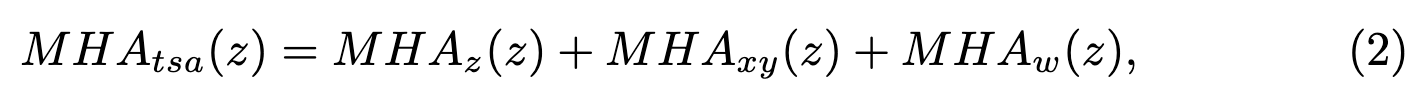
-
Transformer with Cross-Modality Attention


3.Modality-Sensitive Gating
- 将拉长的Fs还原到(d,w,h,c),定义为Fl
- 常规做法是使用3D卷积从底部上采来恢复到原始尺寸来分割,本文注意到了编码特征是多模态的,因此,本文在跳层连接中设置了模态敏感的门控策略

Experiment
- 模型参数通过Xaiver初始化,这个方法已经看到了很多次,可以使用试试,方法来自:Understanding the difficulty of training deep feedforward neural networks

总结
- 这篇论文提出了使用pool transformer作为下采样层,NMaFA模块来融合多模态数据,借鉴该思路,可以做不同分支提取的特征基于transformer的特征融合模块,目前已知的有基于CNN的多特征融合模块ASPP等等,可以尝试一下基于transformer的融合模块是否有更好的效果
- 这篇论文的融合模块主要用于网络的深层,即特征块的尺寸会比较小,transformer的参数量也小,可以考虑在高分辨率的特征层也添加融合模块,但要想办法解决参数量大的问题
- 这篇论文的模型在单张3090上可以运行,代码地址为https://github.com/920232796/NestedFormer,可以跑一下试试
- 在transformer中运用不同方向的attention头会更具特色,更具针对性,这篇论文中的MHAz和MHAxy参考了AxialTransformer,MHAw参考了SwinTransformer,即transformer用多头,每个头不同的针对点
- 这篇论文使用了Token Learner中的方法来控制输入transformer的参数量,该方法可以借鉴
- 下一步把这篇论文借鉴的论文看一看,Axial transformer和token learner
- 为什么论文名字是嵌套的(nested)transformer,因为该论文运用transformer块的方式不是串联也不是并联,而是两个transformer 结合,第一个transformer的输出也是第二个transformer 的输入,其实感觉还是串联的。但是是否可以借鉴RNN的思想,特征提取选择transformer,迭代地向后传递,类比到2d医学影像分割或者非全尺寸的3d医学影像分割,模型预测完第一张/组切片时,保留一定的特征,在输入第二张/组切片到模型时,模型并不完全纯净,叠加第一张/组切片预测时保留的特征,然后再保留一定特征,这时的保留特征就包含了第一张/组和第二张/组的特征,以此方法迭代往后,保留特征中会有由远及近的多切片特征。
- 对位置做编码应该是比较有效且省参数的方法,即position embedding
这篇关于NestedFormer:Nested Modality-Aware Transformer for Brain Tumor Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!