本文主要是介绍论文阅读——Deformable ConvNets v2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文:https://arxiv.org/pdf/1811.11168.pdf
代码:https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch
1. 介绍
可变形卷积能够很好地学习到发生形变的物体,但是论文观察到当尽管比普通卷积网络能够更适应物体形变,可变形卷积网络却可能扩展到感兴趣区域之外从而使得不相关的区域影响网络的性能,由此论文提出v2版本的可变形卷积神经网络(DCNv2),通过更有效的建模能力和训练使网络关注更恰当的图像区域。
其中建模能力的增强得益于两方面:
- 更多的可变形卷积层
- 调节能力,即学习偏移的同时还会加入每一个采样点的权重
当然网络也需要更强大的训练方式,借鉴知识蒸馏的思想,使用一个R-CNN作为Teacher指导网络的训练,因为这个网络可以预测有效的提议框的类别即只受到框里面内容的影响而不会受到框外区域的干扰,DCNv2在ROI层之后的特征趋向于模仿R-CNN的特征,如此一来,DCNv2就增强了自己可变形采样的能力。
2.对可变形卷积的表现进行分析
为了更好地理解可变形卷积的工作机制,论文对以下三个环节进行了可视化分析,这个三部分为理解潜在目标区域对网络节点的贡献提供了详尽的视角。
- 有效感受野:感受野内的像素点对网络的影响是不相同的,这种影响程度的不同可以使用有效感受野来表示,有效感受野的值用每一个像素点对节点梯度的扰动来表示,利用有效感受野可以评价单个的像素点对网络节点的影响但是并不反映整个图像区域的结构性信息。
- 有效的采样位置:用采样区域对网络节点梯度的影响表示有效采样区域来理解不同采样的位置对网络的共享。
- 显著性区域边界错误:网络节点计算的结果不会因为移除图像不想管区域而发生变化,基于此,论文可以将有效的区域缩到最小,和全图相比误差很小,这个称为边界定位有偏差的显著性区域,可以通过不断遮挡图像来计算节点的结果。
可视化结果如下图所示:

能够观察到
- 标准卷积也具有一定程度的对物体的几何形变进行建模的能力
- 通过引入可变形卷积,这种能力显著增强,空间上网络接收了更大的区域,覆盖整个目标的同时也包含了更多的不相关的背景信息
- 第三种类型很明显采样区域更加有效
通过上面的可视化及其分析,很明显可变形卷积能够更好的提升网络对几何形变进行建模的能力,对潜在区域的采样区域更大,因此论文提出需要对这个更大的区域进行进一步的分析,得到一个介于原区域与更大区域二者之间的采样区域以提升精度。
3. 更强大的可变形建模能力
为了提升网络对几何形变进行建模的能力,论文提出了一些变化。
3.1 加入更多的可变形卷积层
因为可变形卷积的特殊能力,论文大胆地(╮(︶﹏︶")╭)提出使用更多的可变形卷积层进一步增强整个网络对于几何形变的建模能力。
该论文将ResNet50的conv3,conv4和conv5阶段中的3x3卷积都替换为可变形卷积也就是一共12层可变形卷积(v1版本只有conv5阶段的三层),在较为简单的Pascal VOC数据集上观察到更多可变形卷积层的表现更为优秀。
3.2 可调节的变形模块
论文引入一种调节机制,不但能够调整接收输入的特征的位置,还能调节不同输入特征的振幅(重要性),极端情况下,一个模块可以通过将重要性设置为0来表示不接收该特征,结果对应采样区域的图像像素点显著减少同时不影响模块的输出,因此这种调节机制能够给网络模块新维度上的能力去调节支持区域。





3.3 R-CNN特征融合
可以从上面三图中看到,deformable RoIPooling使得采样区域增大,但是包含了过多的无关区域甚至可能降低其精度,而可调节的deformable RoIPooling使得区域更加合理。
此外,作者发现这种无关的图像语义信息可能是Faster R-CNN的误差来源,结合一些其他的动机(比如分类分支和边界框回归分支共享一些特征),作者提出将Faster R-CNN和R-CNN的分类分数结合从而获得最终的检测分数,这是由于R-CNN分类分数只专注于输入RoI内的图像内容,这会有助于解决重复语义信息的问题从而提升准确性。然而简单的结合Faster R-CNN和R-CNN会使训练和推断都很慢,论文提出使用R-CNN作为一个教师网络,让DCNV2的RoI池化之后的feature去模拟R-CNN的特征,如下图所示,除了Faster R-CNN外加一个R-CNN分支用于特征模仿,
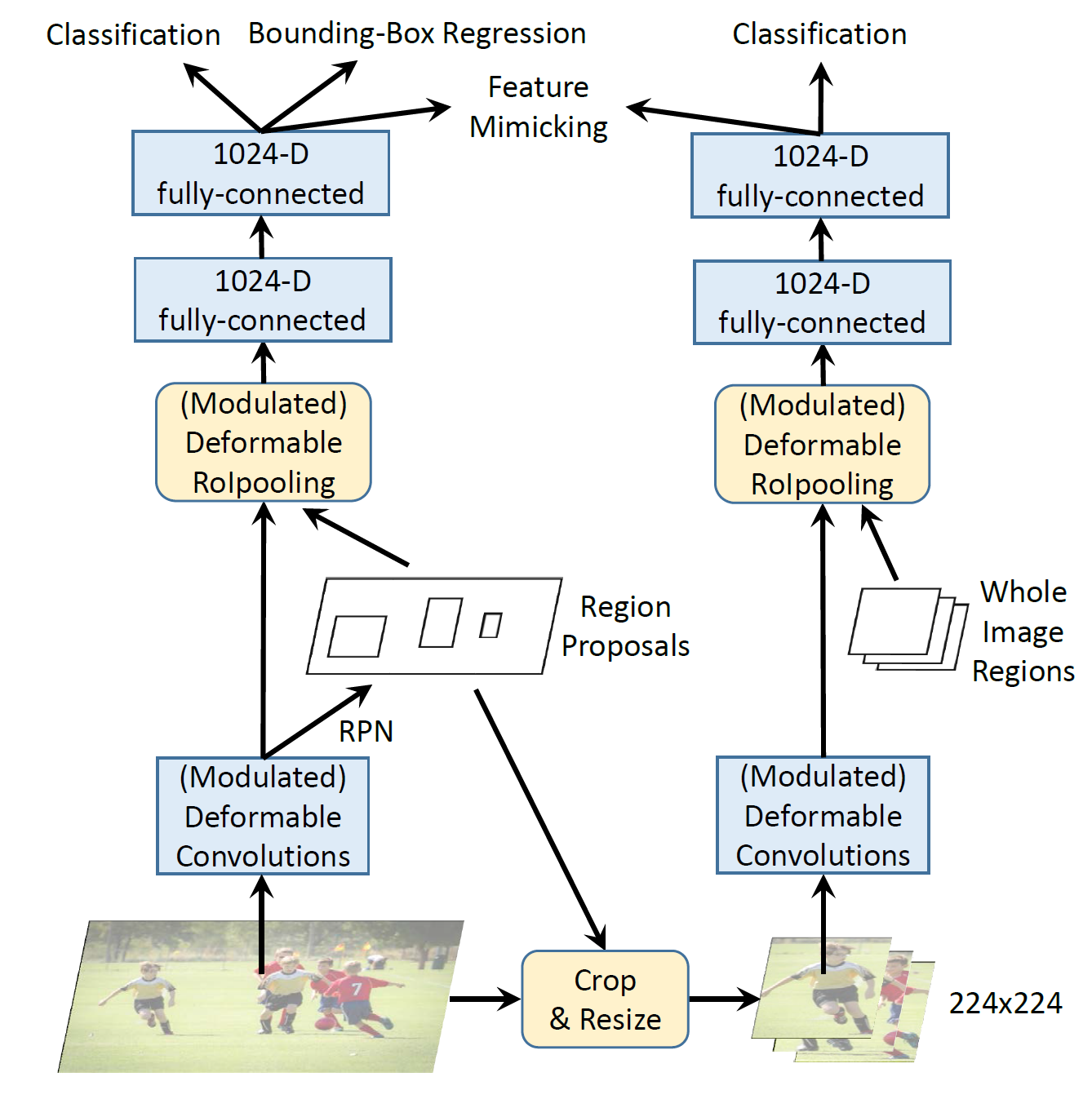



4. 实验
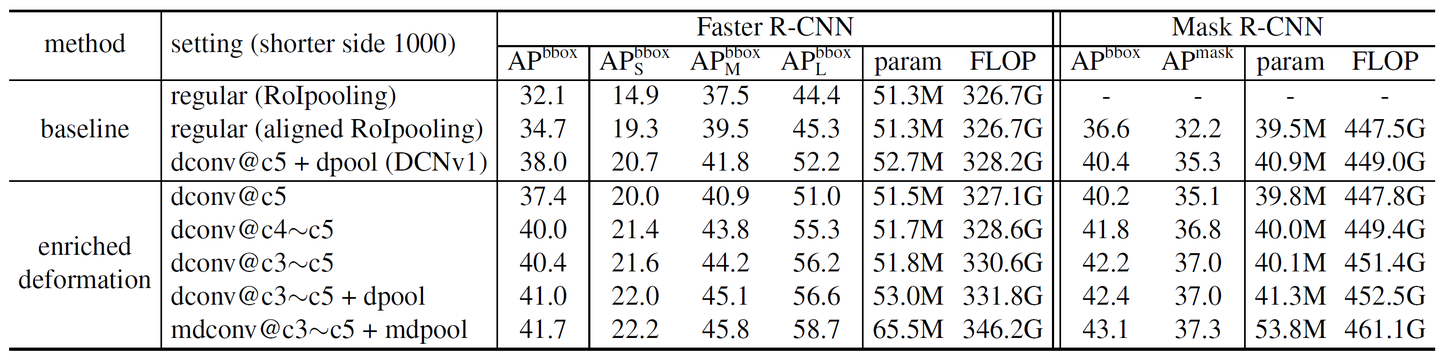
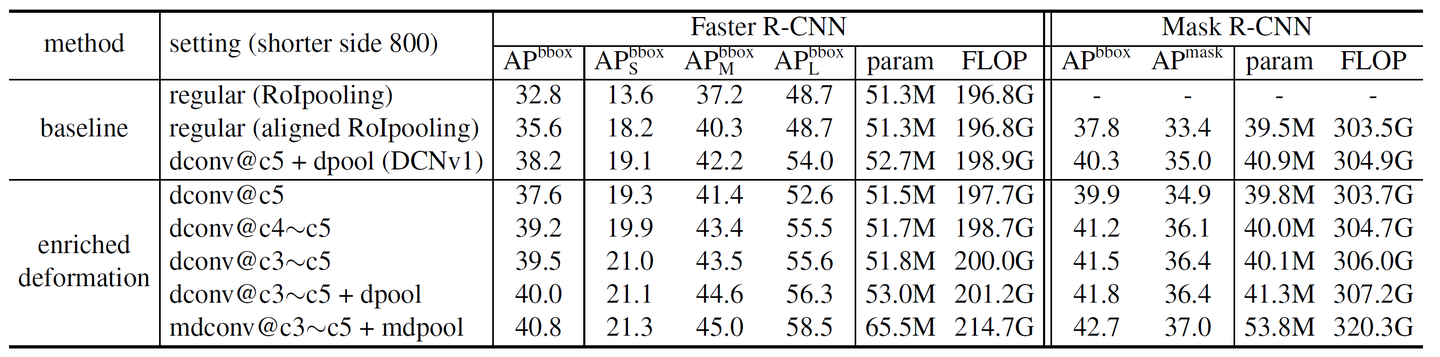
有无可变形卷积/RoI池化和多层可变形卷积(输入图像的短边1000和800)
从哪个阶段开始R-CNN特征模仿的影响

主干网络的影响

不同尺度的目标
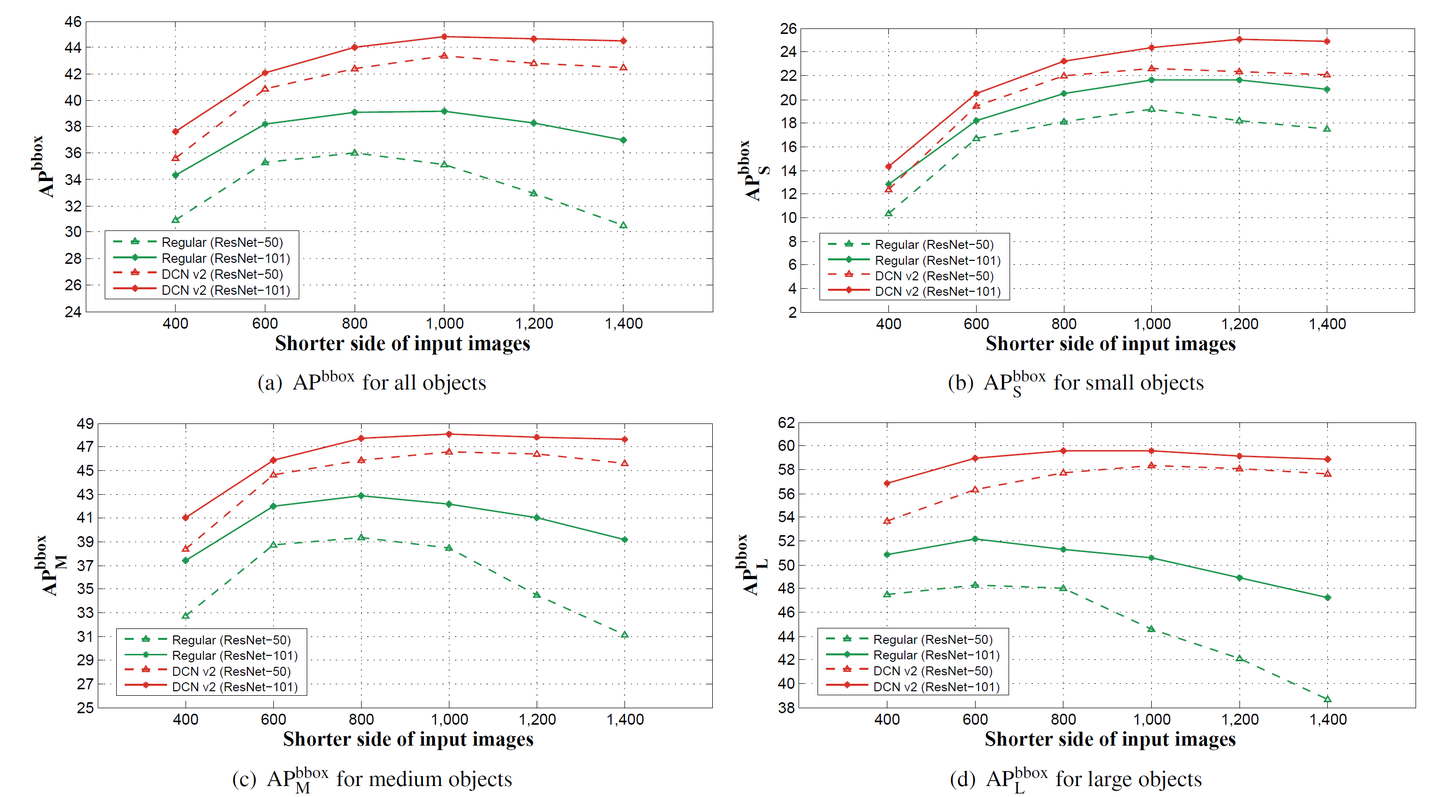
不同大小的输入短边

输入图像的分辨率

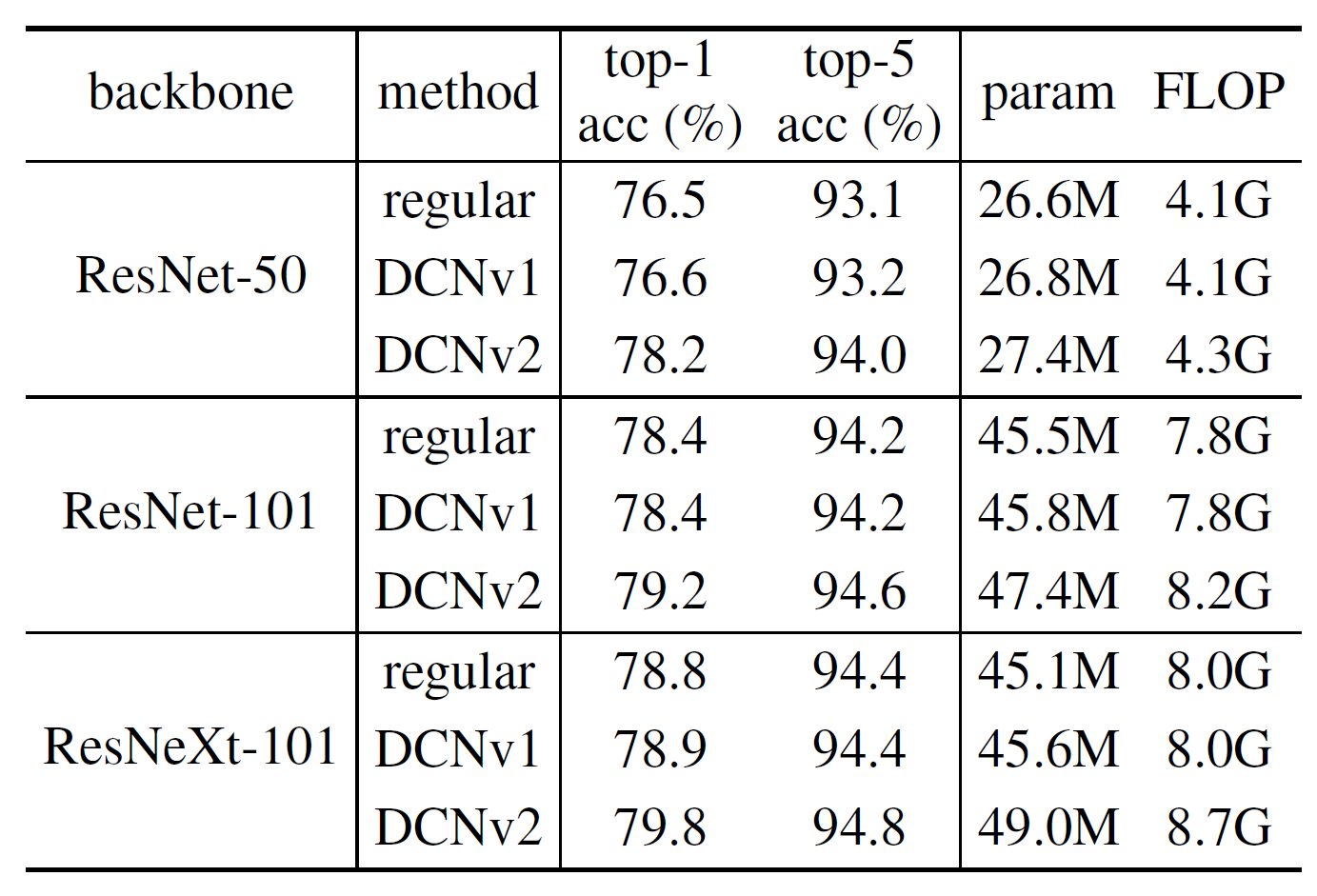
不同主干网络的分类精度不同
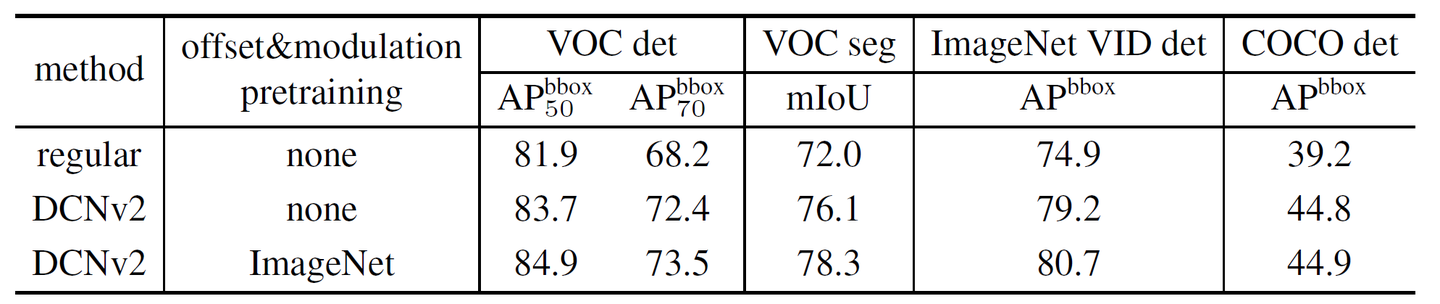
是否ImageNet预训练?
这篇关于论文阅读——Deformable ConvNets v2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
