deformable专题

5.关于Deformable Detr
5.关于Deformable Detr 模型架构 举例源码中使用multi-scale都是四层 Detr缺点 在进行self-attention时,如果序列过长的话,在进行q和v计算过大,对于过大输入图像计算时间太长Detr对于小目标检测的效果不好。 Deformable Detr Deformable Detr 使用的(self-attention) 注意力机制与传
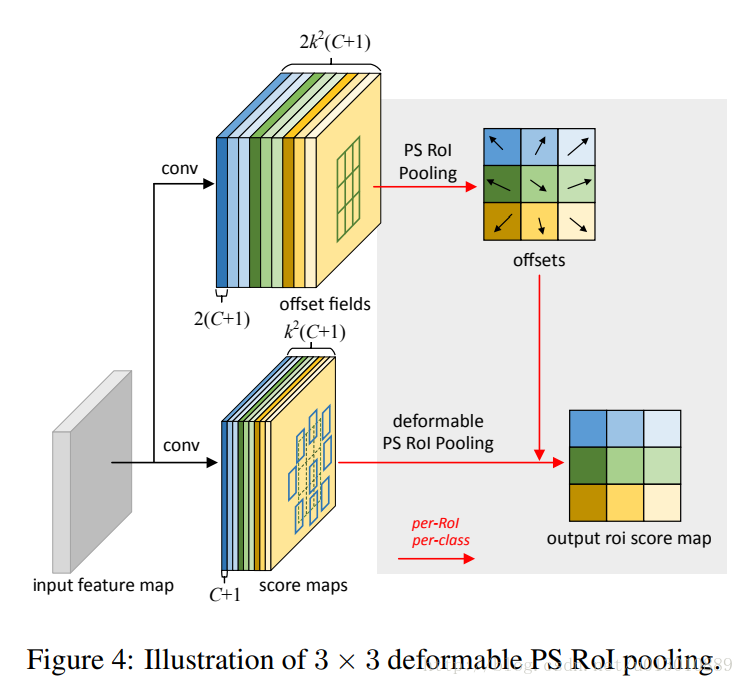
Deformable Convolutional Networks解读
这篇论文是daijifeng老师又一篇好文,一贯的好想法,而且实现的很漂亮,arxiv link Motivation 现实图片中的物体变化很多,之前只能通过数据增强来使网络“记住”这些变种如n object scale, pose, viewpoint, and part deformation,但是这种数据增强只能依赖一些先验知识比如反转后物体类别不变等,但是有些变化是未知而且手动设

Deformable Convolutional可变形卷积回顾
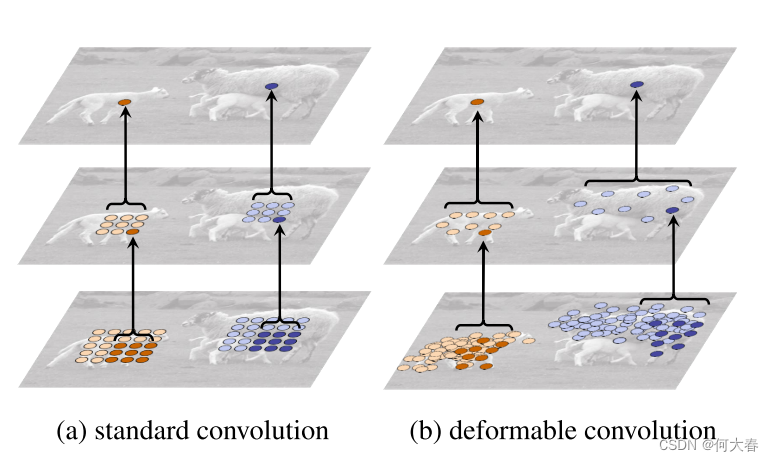
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Sik-Ho Tsang 编译:ronghuaiyang 导读 使用可变形卷积,可以提升Faster R-CNN和R-FCN在物体检测和分割上的性能。只要增加很少的计算量,就可以得到性能的提升,非常好的文章,值的一看。 (a) Conventional Convolution, (b) Deformable Convol

论文阅读笔记之Deformable Convolutional Networks
论文地址:https://arxiv.org/abs/1703.06211 摘要:卷积神经网络的固定几何结构限制了模型对物体形变的建模能力,在本工作中,我们引入了两个新的模块来增强CNNs的形变建模能力,即可变形卷积和可变形RoI池。通过额外的偏移量参数增强空间位置采样能力,并从目标任务中学习偏移量,不需要附加偏移量监督。新模块可以很容易的在现有网络中进行替换,通过标准反向传播很容易进行端到端的
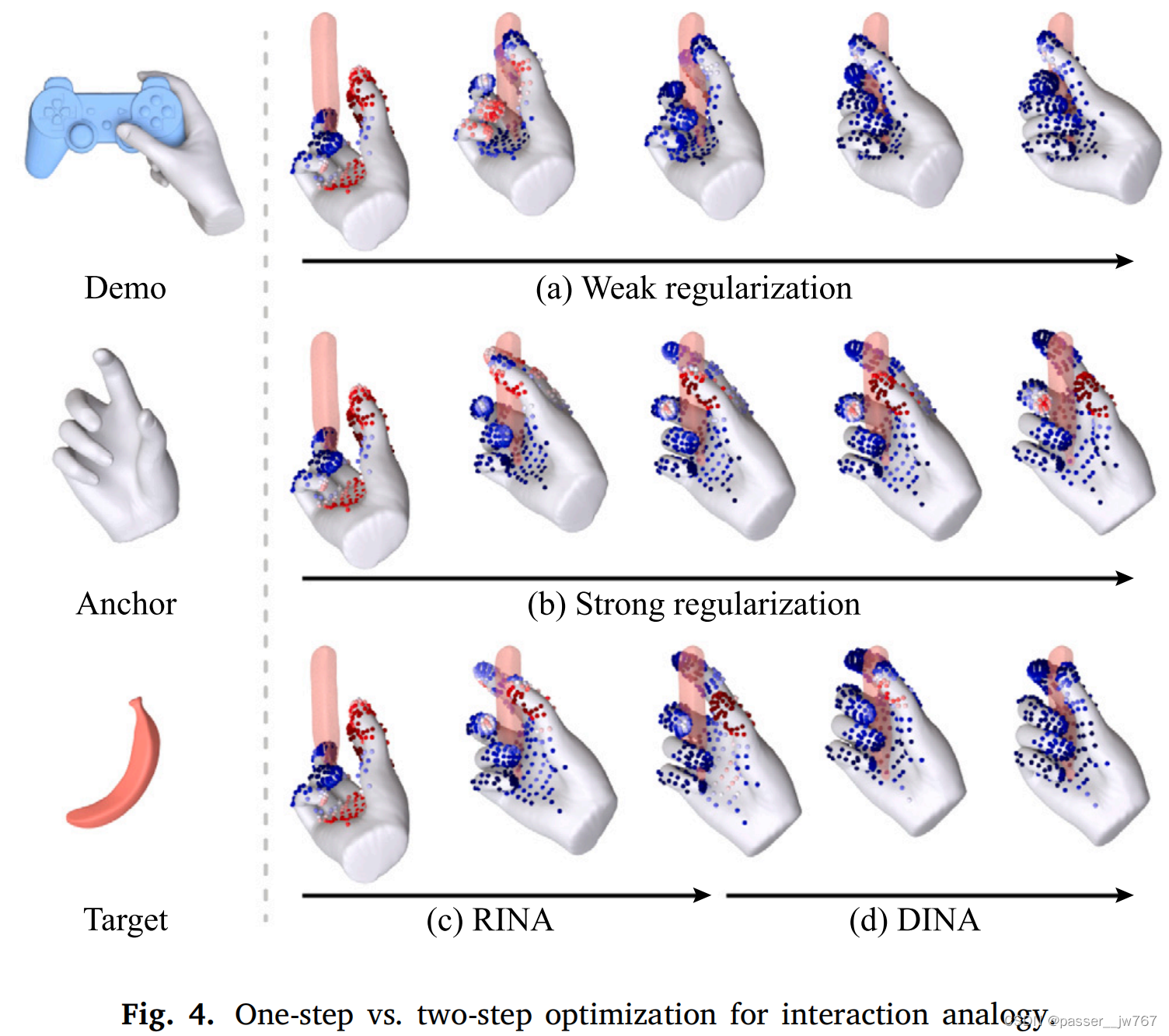
【计算机图形学】DINA: Deformable INteraction Analogy
文章目录 1. 做的事2. 为什么做3. 介绍4. 方法4.1 问题定义4.2 交互表示4.3 交互类比4.4 从刚性到可变形的优化 5. 讨论,限制与未来工作 1. 做的事 引入“可变形交互模仿”的定义,该定义为:在两个3D物体之间生成相近的交互。给定一个锚定物体(如手)和源物体(如被手握着的马克杯)的交互示例,我们的目标是在相同的锚定物体和多样化的新目标物体(如玩具飞机)之间

从固定到可变:利用Deformable Attention提升模型能力
1. 引言 本文将深入探讨注意力机制的内部细节,这是了解机器如何选择和处理信息的基础。但这还不是全部,我们还将探讨可变形注意力的创新理念,这是一种将适应性放在首位的动态方法。 闲话少说,我们直接开始吧! 2. 注意力机制 想象一下,在阅读一个长句子时,大家的注意力并不是平均分配到每个单词上的。相反,你会更专注于对理解至关重要的关键词。同样,神经网络中的注意力机制也是通过为输入序列的不同片段

【视频超分】《Understanding Deformable Alignment in Video Super-Resolution》 2020
摘要: 形变卷积,最开始被用来匹配物体的几何变形,最近在对齐多帧图像上表现出优良的性能,逐渐被用在视频超分任务里面。尽管展现出优良的性能,形变卷积做对齐的内在机制依然不明确。在本文中,我们仔细探究了形变对齐和经典的基于光流对齐的联系。我们展示了形变对齐可以被分解为空间warping和卷积的组合。这种分解显示了形变对齐和光流对齐在公式上的共性,但是在偏移多样性上有关键差异。我们进一步通过实验证明在形
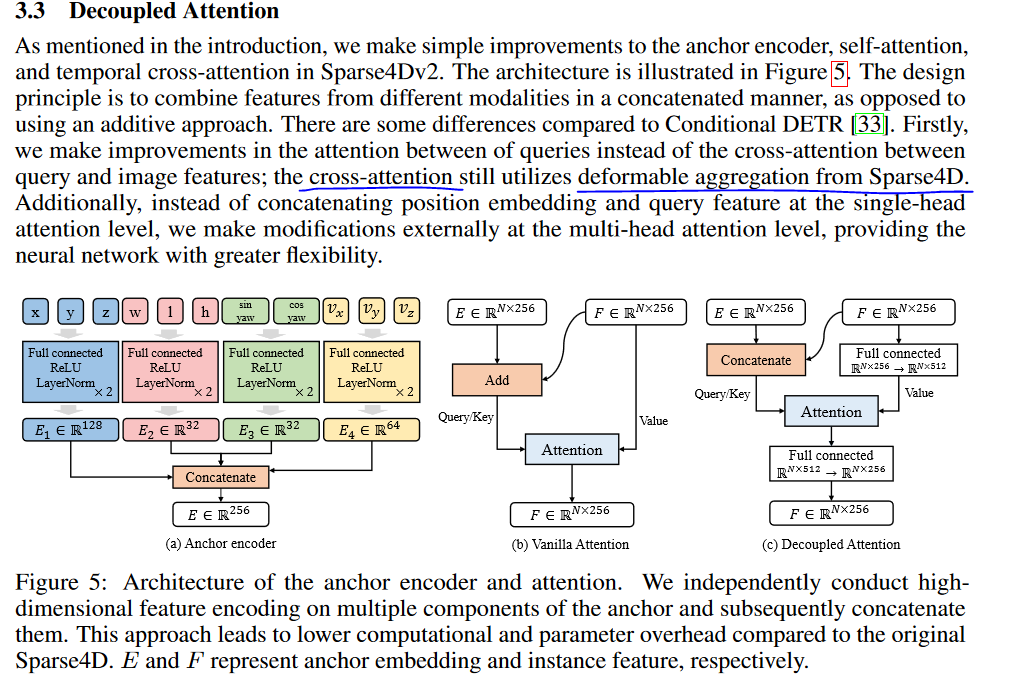
【Transformer-BEV编码(7)】Sparse4D源代码,在mmdet里面增加cuda的插件deformable_aggregation
文章目录 插件位置在论文V3中的“地位”看看具体的代码1. deformable_aggregation.py2. deformable_aggregation.cpp3. deformable_aggregation_cuda.cu3.1 双线性插值bilinear_sampling()3.2 bilinear_sampling_grad() 梯度计算3.3 `deformable_agg

小白的论文学习笔记《Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild》
这篇论文用百度翻译出来中文题目就是:从野外图像中无监督学习可能对称的可变形三维物体。 我本科是学机械的,然后现在研一转成了视觉方向,这也算是我第一次读三维视觉的文章,现在基础知识非常薄弱,所以有许多地方可能会有问题还希望各位能批评指正。 这篇文章主要写的是:从一幅图像中重建可变形物体实例的3D姿态、形状、反照率和光照,具有极佳的保真度。 文章提出了一种在没有外部监督的情况下,从原始单视角图像中学
Deformable Convolutional Networks论文阅读
Deformable Convolutional Networks论文阅读 Abstract1. Introduction2. Deformable Convolutional Networks2.1. Deformable Convolution2.2. Deformable RoI Pooling 总结 文章信息: 原文链接:https://arxiv.org/abs/1

Windows下运行Discriminatively Trained Deformable Part Models代码 Version 4
Windows下运行Discriminatively Trained Deformable Part Models代码 Version 4 Felzenszwalb的Discriminatively Trained Deformable Part Models URL:http://www.cs.brown.edu/~pff/latent/ 这是目前最好的object detect

目标检测--LatentSVM和(Deformable Part Model,DPM)
一、综述 Deformable Part Model和LatentSVM结合用于目标检测由大牛P.Felzenszwalb提出,代表作是以下3篇paper: [1] P. Felzenszwalb, D. McAllester, D.Ramaman. A Discriminatively Trained, Multiscale, Deformable Part Model. Proceed

【动态三维重建】Deformable 3D Gaussians 可变形3D GS用于单目动态场景重建(CVPR 2024)
主页:https://ingra14m.github.io/Deformable-Gaussians/ 代码:https://github.com/ingra14m/Deformable-3D-Gaussians 论文:https://arxiv.org/abs/2309.13101 文章目录 摘要一、前言二、相关工作2.1 动态场景的神经渲染2.2 神经渲染加速 三、方法3.1
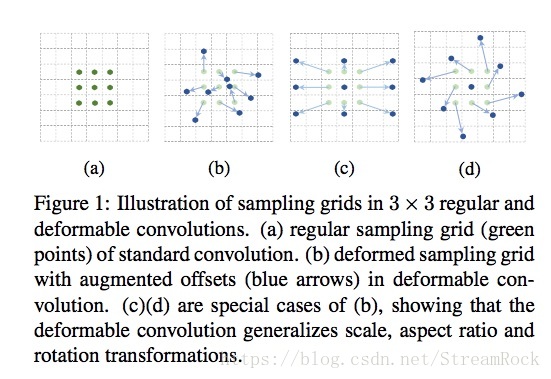
Deformable Convolutional Network的原理与实现
Deformable Convolutional Network的原理与实现 Deformable Convolutional Network(简称Deform-conv)是微软亚洲研究院(MSRA)2017年的作品,它赋予了CNN位置变换的能力,它与STN(Spatial Transform Network)颇有渊源,或者说是灵感来自于此,但它们有着巨大的差别: STN得到的是全局(glob

Object detection with location-aware deformable convolution and backward attention filtering
CVPR19 动机:对multi-scale目标检测来说, context information和high-resolution的特征是很重要的。但是context information一般是不规则分布的,高分辨率特征也往往包含一些干扰的low-level信息。 为了解决这两个问题, 文章提出两个模块: location-aware deformable convolution 和 back

视频超分:Understanding Deformable Alignment in Video Super-Resolution
论文:理解视频超分辨率中的可变形对齐 摘要 可变形卷积最近在对齐多个帧方面表现出了令人信服的性能,并且越来越多地被用于视频超分辨率。尽管它有着显著的表现,但其潜在的对齐机制仍不清楚。本文仔细研究了变形对齐和经典的基于流的对齐之间的关系。贡献如下: 1.第一次正式研究与确立变形对齐与基于流的对齐这两个重要概念之间的关系。 2.系统地研究了偏移多样性。结果表明,偏移多样性是提高对齐精度和SR

优化改进YOLOv5算法之Deformable Attention,效果秒杀CBAM和CA等
目录 1 Deformable Attention模块原理 2 YOLOv5中加入Deformable Attention模块 2.1 common.py文件配置 2.2 yolo.py配置
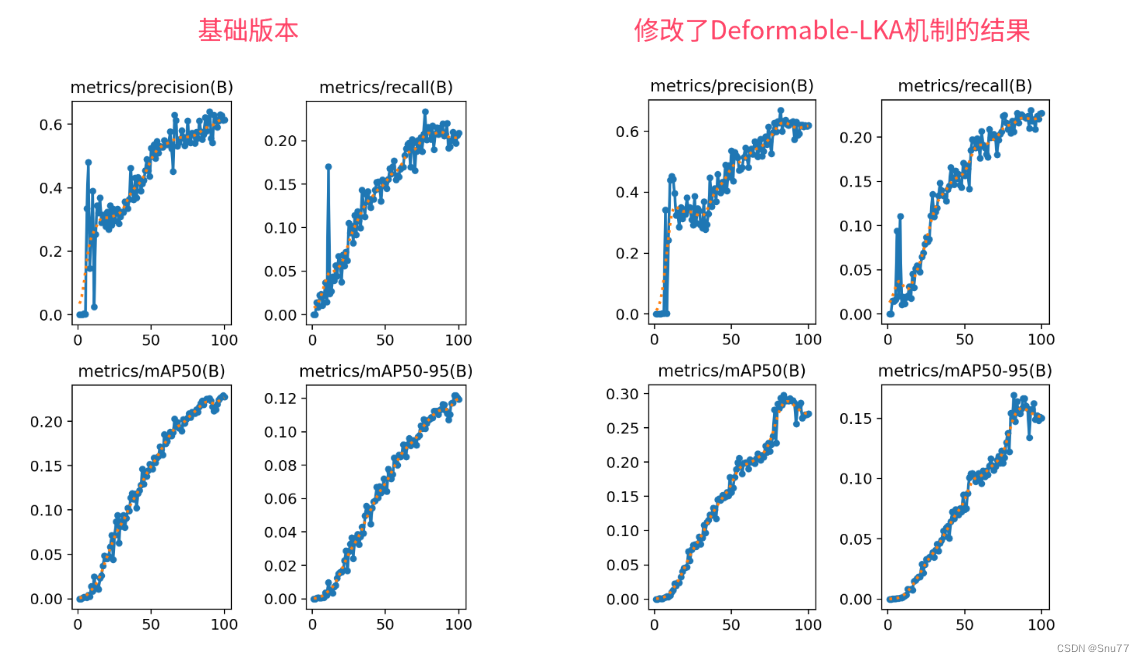
YOLOv5改进 | 注意力篇 | Deformable-LKA(DLKA)可变形的大核注意力(附多个位置添加教程)
一、本文介绍 本文给大家带来的改进内容是Deformable-LKA(可变形大核注意力)。Deformable-LKA结合了大卷积核的广阔感受野和可变形卷积的灵活性,有效地处理复杂的视觉信息。这一机制通过动态调整卷积核的形状和大小来适应不同的图像特征,提高了模型对目标形状和尺寸的适应性。在YOLOv5中,Deformable-LKA可以被用于提升对小目标和不规则形状目标的检测能力,特别是在复杂背
![[CVPR-23] PointAvatar: Deformable Point-based Head Avatars from Videos](https://img-blog.csdnimg.cn/direct/e7733eed2c3b442d8833c5b6f5529209.png)
[CVPR-23] PointAvatar: Deformable Point-based Head Avatars from Videos
[paper | code | proj] 本文的形变方法被成为:Forward DeformationPointAvatar基于点云表征动态场景。目标是根据给定的一段单目相机视频,重建目标的数字人,并且数字人可驱动;通过标定空间(canonical space)和形变空间(deformation space)表征场景。其中,标定空间中的任意点坐标,首先映射至FLAME空间,通过对应FL
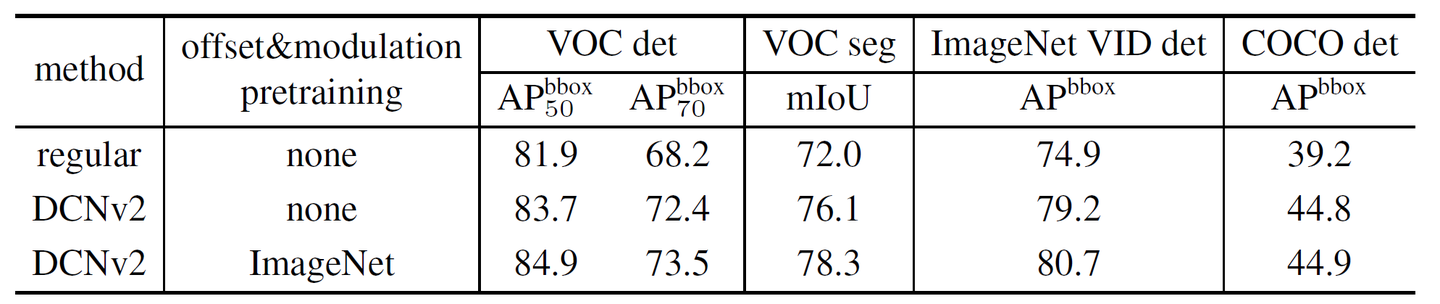
论文阅读——Deformable ConvNets v2
论文:https://arxiv.org/pdf/1811.11168.pdf 代码:https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch 1. 介绍 可变形卷积能够很好地学习到发生形变的物体,但是论文观察到当尽管比普通卷积网络能够更适应物体形变,可变形卷积网络却可能扩展到感兴趣区域之外从而使得不相关的区域影响网
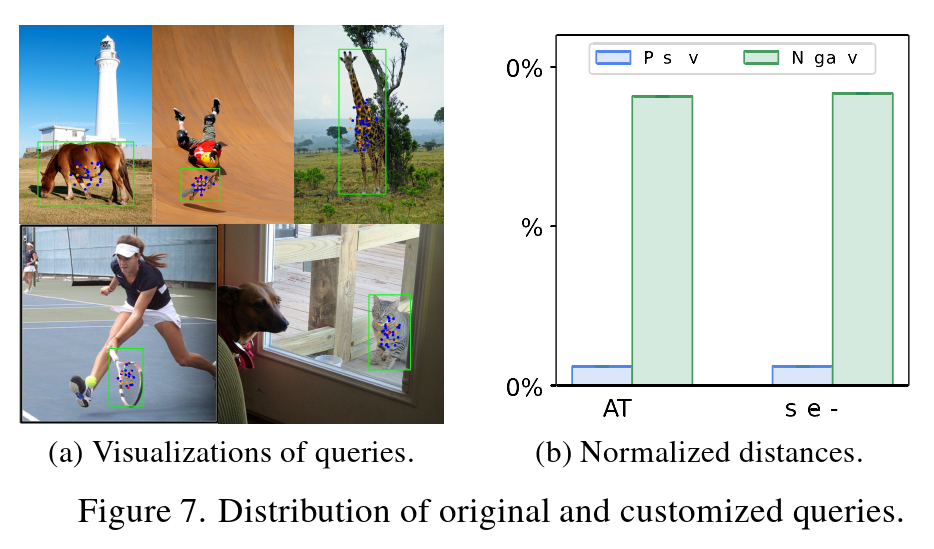
论文精读 Co-DETR(Co-DINO、Co-Deformable-DETR)
DETRs with Collaborative Hybrid Assignments Training 基于协作混合分配训练的DETRs 论文链接:2211.12860.pdf (arxiv.org) 源码链接:https://github.com/Sense-X/Co-DETR 总结: Co-DETR基于DAB-DETR、Deformable-DETR和DINO网络进行了实验。Co-
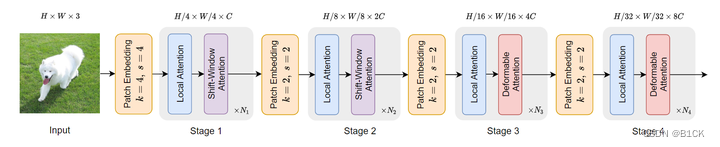
两种Deformable Attention的区别
先分别写一下流程 Deformable DETR(2020)的Deformable Attention 解释: Deformable Attention如下图所示K=3, M=3K是指每个zq会和K个offset算attention,M是指M个head, z q z_q zq有N=HW个: 参考点:reference points,各个特征层上的点,(0.5,0.5)x 4,(0.5,
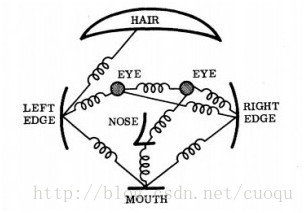
DPM(Deformable Parts Model)
目标检测方法 (1)基于cascade的目标检测 cascade的级联思想可以快速抛弃没有目标的平滑窗(sliding window),因而大大提高了检测效率,但也不是没缺点,缺点就是它仅仅使用了很弱的特征,用它做分类的检测器也是弱分类器,仅仅比随机猜的要好一些,它的精度靠的是多个弱分类器来实行一票否决式推举(就是大家都检测是对的)来提高命中率,确定分类器的个数也是经验问题。这节就来说说改进的
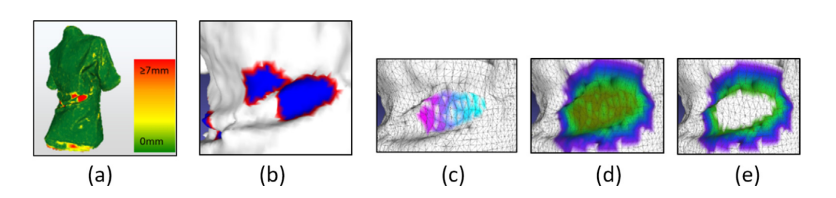
【Literature Notes】Reconstruction of Colored Soft Deformable Objects Based on Self-Generated Template
基于自生成模板的彩色柔性可变形物体重建 论文原文:Jituo Li, Xinqi Liu, Haijing Deng, Tianwei Wang, Guodong Lu, and Jin Wang. 2022. Reconstruction of Colored Soft Deformable Objects Based on Self-Generated Template. Comput. A

搭建Deformable Part Models源码+学习分析
1. 跑通代码: 代码地址: http://people.cs.uchicago.edu.sixxs.org/~rbg/latent/ Version 5 (Sept. 5, 2012) 别忘 mex -setup !!! 1) 在windows下运行Felzenszwalb的Discriminatively Trained Deformable Part Models matlab代码