本文主要是介绍[CVPR-23] PointAvatar: Deformable Point-based Head Avatars from Videos,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

[paper | code | proj]
- 本文的形变方法被成为:Forward Deformation
- PointAvatar基于点云表征动态场景。目标是根据给定的一段单目相机视频,重建目标的数字人,并且数字人可驱动;
- 通过标定空间(canonical space)和形变空间(deformation space)表征场景。
- 其中,标定空间中的任意点坐标,首先映射至FLAME空间,通过对应FLAME的相关系数(表情、位姿和LBS)从FLAME空间映射至形变空间。
- 该点的颜色,被拆解为与姿态无关的反射率(albedo)和与姿态相关的阴影(shading)。其中前者根据点在标定空间中的坐标预测得到,后者根据点在形变空间的法向量预测得到。
- 点在标定空间中的法向量通过拟合SDF对坐标求导得到,在形变空间中的法向量通过点的逆雅可比矩阵求得。
方法
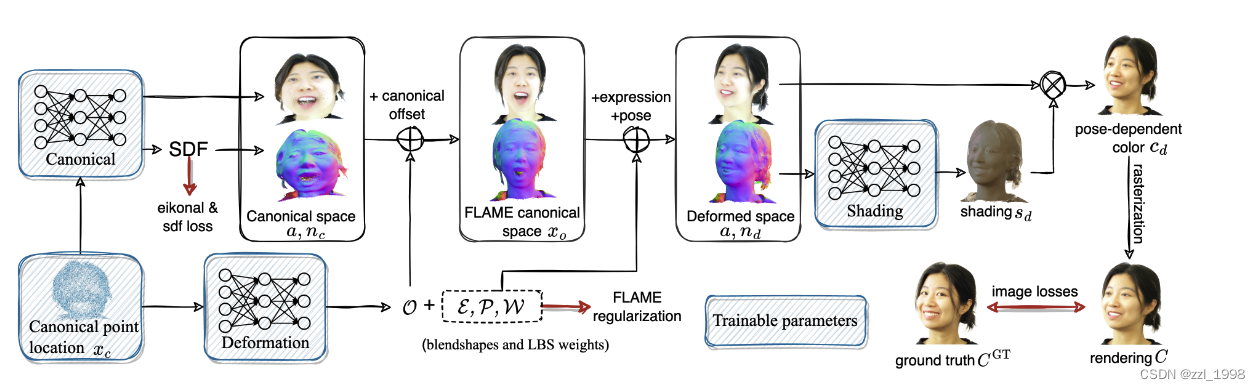
基于点的标定表征
- 包括点和颜色
- 点。N个可学习的点。初始化时,从一个球体中采样点;后续训练中,增加点的数量同时减少点的半径。在训练过程中,对下面两种点会删除掉:不能投影至任何像素的点、可见度高于某个阈值的点。

- 颜色。将点颜色解耦为与位姿(pose)无关的反射率(albedo)和与pose相关的阴影(shading);
- 阴影部分:通过点在形变空间的法向量(normal)估计;
- 因此,本文的重点在于:
- 1)如何估计点在标定空间中的反射率和法向量;
- 2)如何估计点在形变空间中的位置和法向量;
标定空间下的法向量
- 训练中,根据当前标定空间下的点,估计SDF:
和
。其中,后者是Eikonal正则项,
包含了点和扰动点;
- 通过SDF对该点位置求导,得到该点的法向量:
标定空间下的反射率
- 通过一个MLP将点位置
映射为反射率颜色(albedo colors)
。为了节省计算开销,本文用一个MLP同时计算标定空间下的法向量和反射率:
![]()
点的形变
- 将标定点
,映射为FLAME标定点
;
- 将FLAME标定点
。
- 通过MLP,输入为标定点,输出为标定差
、表情系数残差
、姿态系数残差
和LBS系数
。具体公式如下:

法向量的形变
- 求得标定点

点的颜色
标定点,在形变空间中的坐标是
,对应的形变颜色是
:
![]()
其中,可通过形变点的法向量求得:
![]()
可导的点渲染
基于PyTorch3D实现,和3DGS的Splatting渲染方法类似。
训练目标
![]()
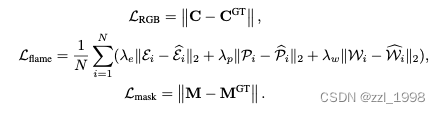
其中,M是头部掩码(head mash),表情系数,位姿系数和LBS系数的伪标签定义为最近邻FLAME顶点。最终损失为:
![]()
实验
- 数据集包含:
- IMavatar中的1个目标;
- NerFace中的2个目标;
- 本文在互联网收集的1个目标、基于智能手机拍摄的4个目标和笔记本摄像头拍摄的1个目标
- 基线方法:NerFace、neural head avatar (NHA)和IMavatar
SOTA方法的比较


重光照(光照解耦)

训练和渲染开销

消融实验
- 相较于直接在预定义FLAME模型中学习,在标准空间中任意学习,再映射到FLAME空间,表现更佳。

这篇关于[CVPR-23] PointAvatar: Deformable Point-based Head Avatars from Videos的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!