本文主要是介绍ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询;
一、首先启动相关服务:
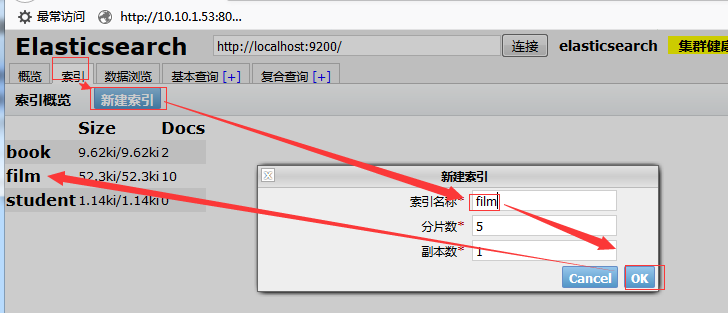
二、新建一个film索引:
三、建立映射:
1、通过Head插件:
POST http://192.168.1.111:9200/film/_mapping/dongzuo/
{"properties": {"title": {"type": "text"},"publishDate": {"type": "date"},"content": {"type": "text"},"director": {"type": "keyword"},"price": {"type": "float"}}}添加文档,数据准备:
public class TestFilm {private static String host = "127.0.0.1";private static int port = 9300;public TransportClient client = null;@SuppressWarnings({ "resource", "unchecked" })@Beforepublic void getClient() throws Exception {client = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName(host),port));}@Afterpublic void close() {if(client!=null) {client.close();}}/*** 添加文档* @throws Exception*/@Testpublic void testIndex() throws Exception {JsonArray jsonArray = new JsonArray();JsonObject jsonObject = new JsonObject();jsonObject.addProperty("title", "前任3:再见前任");jsonObject.addProperty("publishDate", "2017-12-29");jsonObject.addProperty("content", "一对好基友孟云(韩庚 饰)和余飞(郑恺 饰)跟女友都因为一点小事宣告分手,并且“拒绝挽回,死不认错”。两人在夜店、派对与交友软件上放飞人生第二春,大肆庆祝“黄金单身期”,从而引发了一系列好笑的故事。孟云与女友同甘共苦却难逃“五年之痒”,余飞与女友则棋逢敌手相爱相杀无绝期。然而现实的“打脸”却来得猝不及防:一对推拉纠结零往来,一对纠缠互怼全交代。两对恋人都将面对最终的选择:是再次相见?还是再也不见?");jsonObject.addProperty("director", "田羽生");jsonObject.addProperty("price", "35");jsonArray.add(jsonObject);JsonObject jsonObject2=new JsonObject();jsonObject2.addProperty("title", "机器之血");jsonObject2.addProperty("publishDate", "2017-12-29");jsonObject2.addProperty("content", "2007年,Dr.James在半岛军火商的支持下研究生化人。研究过程中,生化人安德烈发生基因突变大开杀戒,将半岛军火商杀害,并控制其组织,接管生化人的研究。Dr.James侥幸逃生,只好寻求警方的保护。特工林东(成龙 饰)不得以离开生命垂危的小女儿西西,接受证人保护任务...十三年后,一本科幻小说《机器之血》的出版引出了黑衣生化人组织,神秘骇客李森(罗志祥 饰)(被杀害的半岛军火商的儿子),以及隐姓埋名的林东,三股力量都开始接近一个“普通”女孩Nancy(欧阳娜娜 饰)的生活,想要得到她身上的秘密。而黑衣人幕后受伤隐藏多年的安德烈也再次出手,在多次缠斗之后终于抓走Nancy。林东和李森,不得不以身犯险一同前去解救,关键时刻却发现李森竟然是被杀害的半岛军火商的儿子,生化人的实验记录也落入了李森之手......");jsonObject2.addProperty("director", "张立嘉");jsonObject2.addProperty("price", "45");jsonArray.add(jsonObject2);JsonObject jsonObject3=new JsonObject();jsonObject3.addProperty("title", "星球大战8:最后的绝地武士");jsonObject3.addProperty("publishDate", "2018-01-05");jsonObject3.addProperty("content", "《星球大战:最后的绝地武士》承接前作《星球大战:原力觉醒》的剧情,讲述第一军团全面侵袭之下,蕾伊(黛西·雷德利 Daisy Ridley 饰)、芬恩(约翰·博耶加 John Boyega 饰)、波·达默龙(奥斯卡·伊萨克 Oscar Isaac 饰)三位年轻主角各自的抉 择和冒险故事。前作中觉醒强大原力的蕾伊独自寻访隐居的绝地大师卢克·天行者(马克·哈米尔 Mark Hamill 饰),在后者的指导下接受原力训练。芬恩接受了一项几乎不可能完成的任务,为此他不得不勇闯敌营,面对自己的过去。波·达默龙则要适应从战士向领袖的角色转换,这一过程中他也将接受一些血的教训。");jsonObject3.addProperty("director", "莱恩·约翰逊");jsonObject3.addProperty("price", "55");jsonArray.add(jsonObject3);JsonObject jsonObject4=new JsonObject();jsonObject4.addProperty("title", "羞羞的铁拳");jsonObject4.addProperty("publishDate", "2017-12-29");jsonObject4.addProperty("content", "靠打假拳混日子的艾迪生(艾伦 饰),本来和正义感十足的体育记者马小(马丽 饰)是一对冤家,没想到因为一场意外的电击,男女身体互换。性别错乱后,两人互坑互害,引发了拳坛的大地震,也揭开了假拳界的秘密,惹来一堆麻烦,最终两人在“卷莲门”副掌门张茱萸(沈腾 饰)的指点下,向恶势力挥起了羞羞的铁拳。");jsonObject4.addProperty("director", "宋阳 / 张吃鱼");jsonObject4.addProperty("price", "35");jsonArray.add(jsonObject4);JsonObject jsonObject5=new JsonObject();jsonObject5.addProperty("title", "战狼2");jsonObject5.addProperty("publishDate", "2017-07-27");jsonObject5.addProperty("content", "故事发生在非洲附近的大海上,主人公冷锋(吴京 饰)遭遇人生滑铁卢,被“开除军籍”,本想漂泊一生的他,正当他打算这么做的时候,一场突如其来的意外打破了他的计划,突然被卷入了一场非洲国家叛乱,本可以安全撤离,却因无法忘记曾经为军人的使命,孤身犯险冲回沦陷区,带领身陷屠杀中的同胞和难民,展开生死逃亡。随着斗争的持续,体内的狼性逐渐复苏,最终孤身闯入战乱区域,为同胞而战斗。");jsonObject5.addProperty("director", "吴京");jsonObject5.addProperty("price", "38");jsonArray.add(jsonObject5);for (int i = 0; i < jsonArray.size(); i++) {JsonObject jo = jsonArray.get(i).getAsJsonObject();IndexResponse response = client.prepareIndex("film", "dongzuo").setSource(jo.toString(),XContentType.JSON).get();System.out.println("索引名称:"+response.getIndex());System.out.println("类型:"+response.getType());System.out.println("文档ID:"+response.getId());System.out.println("当前实例状态:"+response.status());}}
}
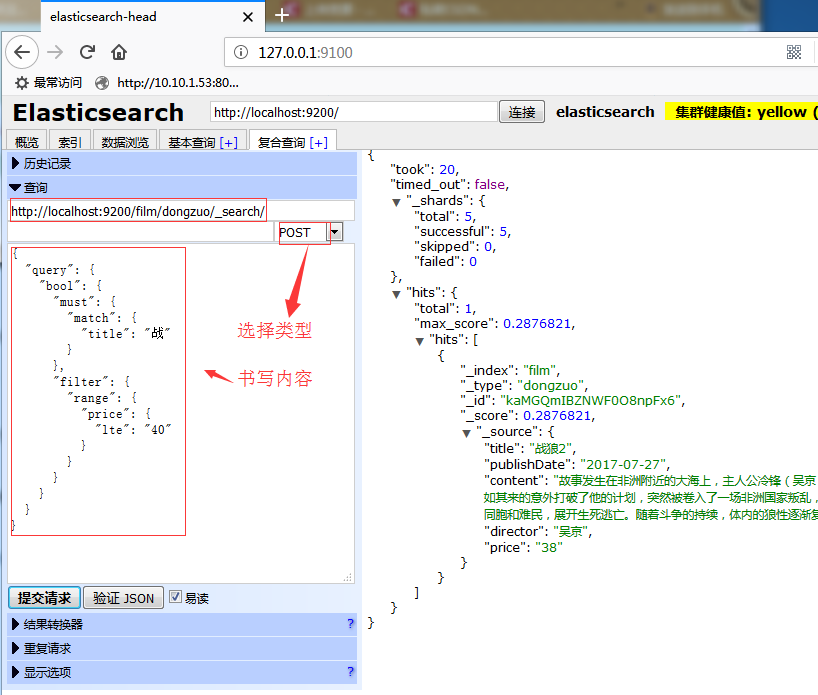
四、通过Head插件查询数据及其Java代码实现
GET http://192.168.1.111:9200/film/dongzuo/_search/ 图片略;
代码实现如下:
/*** 查询所有文档* @throws Exception*/@Testpublic void searchAll() throws Exception {SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");SearchResponse sr = srb.setQuery(QueryBuilders.matchAllQuery()).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}
五、通过Head插件分页查询数据及其Java代码实现
POST http://192.168.1.111:9200/film/dongzuo/_search/
{"from": 0,"size": 2
}java代码如下:
/** 分页查询*/@Testpublic void searchPaging() throws Exception {SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");SearchResponse sr = srb.setQuery(QueryBuilders.matchAllQuery()).setFrom(1).setSize(2).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}六、通过Head插件排序查询数据及其Java代码实现
POST:http://192.168.1.111:9200/film/dongzuo/_search/
{"sort":[{"publishDate":{"order":"desc"}}]
}根据发布日期降序排列;
Java代码如下:
/*** 查询排序*/@Testpublic void searchOrderBy() throws Exception {SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");SearchResponse sr = srb.setQuery(QueryBuilders.matchAllQuery()).addSort("publishDate",SortOrder.DESC).execute().actionGet(); //分页排序所有SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}七、通过Head插件实现数据列过滤及其Java代码实现
POST http://192.168.1.111:9200/film/dongzuo/_search/
{"from": 0,"size": 2,"_source":{"include":["title","price"]}
}Java代码如下:
/*** 过滤查询,显示指定列*/@Testpublic void searchInclude() throws Exception {SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");SearchResponse sr = srb.setQuery(QueryBuilders.matchAllQuery()).setFetchSource(new String[]{"title","price"},null).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}八、通过Head插件实现简单条件查询及其Java代码实现
POST:http://192.168.1.111:9200/film/dongzuo/_search/
{"query":{"match":{"title":"战"}}
}Java代码如下:
/*** 条件查询:模糊查询*/@Testpublic void searchByCondition() throws Exception {SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");SearchResponse sr = srb.setQuery(QueryBuilders.matchQuery("title","战")).setFetchSource(new String[]{"title","price"},null).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}九、通过Head插件根据条件查询高亮实现及其Java代码实现
POST:http://192.168.1.111:9200/film/dongzuo/_search/
{"query":{"match":{"title":"战"}},"_source":{"include":["title","price"]},"highlight":{"fields":{"title":{}}}
}Java代码如下:
/*** 条件查询高亮实现*/@Testpublic void searchHighlight() throws Exception{SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.preTags("<h2>");highlightBuilder.postTags("</h2>");highlightBuilder.field("title");SearchResponse sr = srb.setQuery(QueryBuilders.matchQuery("title", "战")).highlighter(highlightBuilder).setFetchSource(new String[]{"title","price"},null).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());System.out.println(searchHit.getHighlightFields());System.out.println("-------结束---------");}}十、通过Head插件实现组合多条件查询及其Java代码实现
实际项目开发中,基本上都是组合多条件查询。
ElasticSearch提供bool来实现这种需求;
主要参数:
must:文档 必须 匹配这些条件才能被包含进来。
must_not:文档 必须不 匹配这些条件才能被包含进来。
should:如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter:必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
最简单的 模糊查询标题含有“战”:
post:http://192.168.1.111:9200/film/dongzuo/_search/
{"query": {"bool": {"must":{"match":{"title":"战"}}}}
}多条件的话:
{"query": {"bool": {"must":[{"match":{"title":"战"}},{"match":{"content":"星球"}}]}}
}运行结果略;
Java代码实现如下:
/*** 多条件查询1*/@Testpublic void searchMutil() throws Exception{SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");QueryBuilder queryBuilder = QueryBuilders.matchPhraseQuery("title", "战");QueryBuilder queryBuilder2 = QueryBuilders.matchPhraseQuery("content", "星球");SearchResponse sr = srb.setQuery(QueryBuilders.boolQuery().must(queryBuilder).must(queryBuilder2)).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}must_not使用
内容里不含有“武士”
{"query": {"bool": {"must":{"match":{"title":"战"}},"must_not":{"match":{"content":"武士"}}}}
}Java代码实现如下:
/*** 多条件查询2*/@Testpublic void searchMutil2() throws Exception{SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");QueryBuilder queryBuilder = QueryBuilders.matchPhraseQuery("title", "战");QueryBuilder queryBuilder2 = QueryBuilders.matchPhraseQuery("content", "武士");SearchResponse sr = srb.setQuery(QueryBuilders.boolQuery().must(queryBuilder).mustNot(queryBuilder2)).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}
{"query": {"bool": {"must":[{"match":{"title":"战"}}]}}
}should的使用:
{"query": {"bool": {"must":{"match":{"title":"战"}},"should":[{"match":{"content":"星球"}},{"range":{"publishDate":{"gte":"2018-01-01"}}}]}}
}
/*** 多条件查询3*/@Testpublic void searchMutil3() throws Exception{SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");QueryBuilder queryBuilder = QueryBuilders.matchPhraseQuery("title", "战");QueryBuilder queryBuilder2 = QueryBuilders.matchPhraseQuery("content", "星球");QueryBuilder queryBuilder3 = QueryBuilders.rangeQuery("publishDate").gt("2018-01-01");SearchResponse sr = srb.setQuery(QueryBuilders.boolQuery().must(queryBuilder).should(queryBuilder2).should(queryBuilder3)).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}filter过滤;
票价必须少于40
{"query": {"bool": {"must": {"match": {"title": "战"}},"filter": {"range": {"price": {"lte":"40"}}}}}
}
/*** 多条件查询4*/@Testpublic void searchMutil4() throws Exception{SearchRequestBuilder srb = client.prepareSearch("film").setTypes("dongzuo");QueryBuilder queryBuilder = QueryBuilders.matchPhraseQuery("title", "战");QueryBuilder queryBuilder2 = QueryBuilders.rangeQuery("price").lte(40);SearchResponse sr = srb.setQuery(QueryBuilders.boolQuery().must(queryBuilder).filter(queryBuilder2)).execute().actionGet();SearchHits hits = sr.getHits();for (SearchHit searchHit : hits) {System.out.println(searchHit.getSourceAsString());}}这篇关于ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






