elasticsearch专题

Elasticsearch 在 Java 中的使用教程
《Elasticsearch在Java中的使用教程》Elasticsearch是一个分布式搜索和分析引擎,基于ApacheLucene构建,能够实现实时数据的存储、搜索、和分析,它广泛应用于全文... 目录1. Elasticsearch 简介2. 环境准备2.1 安装 Elasticsearch2.2 J

ElasticSearch+Kibana通过Docker部署到Linux服务器中操作方法
《ElasticSearch+Kibana通过Docker部署到Linux服务器中操作方法》本文介绍了Elasticsearch的基本概念,包括文档和字段、索引和映射,还详细描述了如何通过Docker... 目录1、ElasticSearch概念2、ElasticSearch、Kibana和IK分词器部署

Java实现Elasticsearch查询当前索引全部数据的完整代码
《Java实现Elasticsearch查询当前索引全部数据的完整代码》:本文主要介绍如何在Java中实现查询Elasticsearch索引中指定条件下的全部数据,通过设置滚动查询参数(scrol... 目录需求背景通常情况Java 实现查询 Elasticsearch 全部数据写在最后需求背景通常情况下

Java操作ElasticSearch的实例详解
《Java操作ElasticSearch的实例详解》Elasticsearch是一个分布式的搜索和分析引擎,广泛用于全文搜索、日志分析等场景,本文将介绍如何在Java应用中使用Elastics... 目录简介环境准备1. 安装 Elasticsearch2. 添加依赖连接 Elasticsearch1. 创

基于MySQL Binlog的Elasticsearch数据同步实践
一、为什么要做 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品、订单等数据的多维度检索。 使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。而数据进行异构存储后,随之而来的就是数据同步的问题。 二、现有方法及问题 对于数据同步,我们目前的解决方案是建立数据中间表。把需要检索的业务数据,统一放到一张M

ElasticSearch的DSL查询⑤(ES数据聚合、DSL语法数据聚合、RestClient数据聚合)
目录 一、数据聚合 1.1 DSL实现聚合 1.1.1 Bucket聚合 1.1.2 带条件聚合 1.1.3 Metric聚合 1.1.4 总结 2.1 RestClient实现聚合 2.1.1 Bucket聚合 2.1.2 带条件聚合 2.2.3 Metric聚合 一、数据聚合 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:

【docker】基于docker-compose 安装elasticsearch + kibana + ik分词器(8.10.4版本)
记录下,使用 docker-compose 安装 Elasticsearch 和 Kibana,并配置 IK 分词器,你可以按照以下步骤进行。此过程适用于 Elasticsearch 和 Kibana 8.10.4 版本。 安装 首先,在你的工作目录下创建一个 docker-compose.yml 文件,用于配置 Elasticsearch 和 Kibana 的服务。 version:
ElasticSearch底层原理简析
1.ElasticSearch简述 ElastiaSearch(以下简称ES)是一个基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎,支持RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。ES设计用于云计算中,能够进行实时搜索,支持PB级搜索,具有稳定,可靠,快速,安装使用方便等
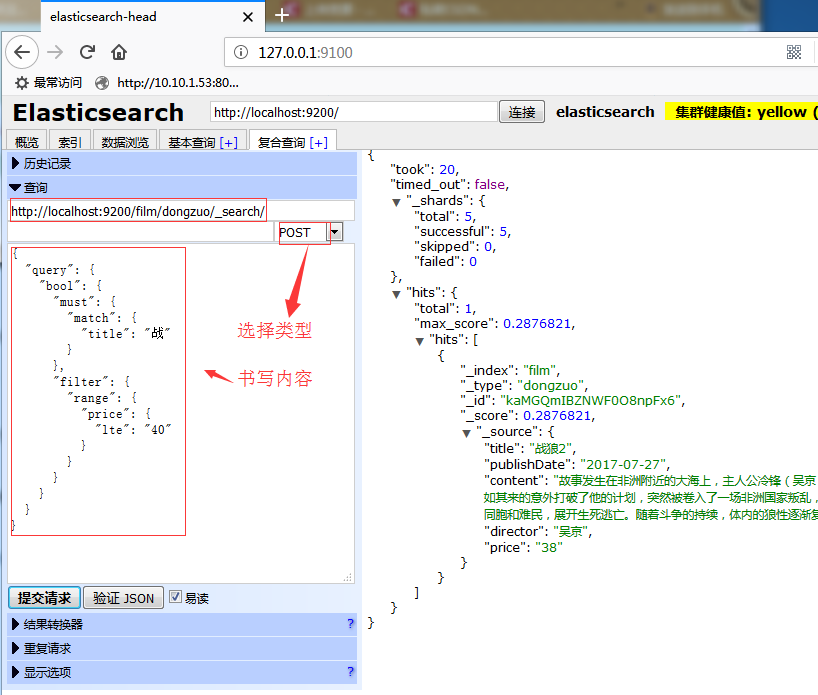
ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询数据
ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询; 一、首先启动相关服务: 二、新建一个film索引: 三、建立映射: 1、通过Head插件: POST http://192.168.1.111:9200/film/_mapping/dongzuo/ {"properties": {"title": {"type":
ElasticSearch 6.1.1运用代码添加索引及其添加,修改,删除文档
1、新建一个MAVEN项目:ElasticSearchTest 2、修改pom.xml文件内容: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.or

Windows下安装Elasticsearch,启动报错,解决方法,访问
对于Windows用户,我们推荐使用MSI安装包进行安装。这个安装包使用图形用户界面来引导你进行安装。 首先,从这里https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.1.1.msi下载Elasticsearch 6.1.1的MSI安装包。 然后双击下载好的安装包文件启动图形化安装程序,在第一个界面,选

Elasticsearch:无状态世界中的数据安全
作者:来自 Elastic Henning Andersen 在最近的博客文章中,我们宣布了支持 Elastic Cloud Serverless 产品的无状态架构。通过将持久性保证和复制卸载到对象存储(例如 Amazon S3),我们获得了许多优势和简化。 从历史上看,Elasticsearch 依靠本地磁盘持久性来确保数据安全并处理陈旧或孤立的节点。在本博客中,我们将讨论无状态的数据持

ElasticSearch的DSL查询④(DSL查询、RestClient的DSL查询)
目录 一、DSL查询 1.1 快熟入门 1.2 叶子查询 1.2.1 全文检索查询 1)match查询 2)multi_match查询 1.2.2 精确查询 1)term查询 2)range查询 3)ids查询 1.3 复合查询 1.3.1 bool查询 1.3.2 算分函数查询 1)基本语法: 2)运行流程: 3)示例: 4)执行结果: 1.4 排序 1.5

Mac使用Elasticsearch
下载 Past Releases of Elastic Stack Software | Elastic 解压tar -xzvf elasticsearch-8.15.1-darwin-x86_64.tar.gz 修改配置文件config/elasticsearch.yml xpack.security.enabled: false xpack.security.http.
PHP使用elasticsearch搜索安装及分词方法
一、背景 为什么会用到这个ES搜索?是因为我在看乌云的漏洞案例库时候,搜索即为不方便。 比如说说我要搜索一个 SQL注入 那mysql匹配的时候是like模糊匹配,搜索必须要有SQL注入这四个字,连续的才能查找到那这样会不太方便。 然后我就想着做一个分词,搜索起来会方便不少,第一个想到的就是ES搜索了。 怎么去用ES呢? 二、安装ES搜索 我们只需要一个JAVA环境并且把Java的环

一文俯瞰Elasticsearch核心原理
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多惊喜 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! Lucene 介绍 Lucene是一种高性能、可伸缩的信息搜索(IR)库,在2000年开源,最初由鼎鼎大名的Doug Cutting开发,是基于Java实现的高性能的开源项目。Lucene采用了基于倒排表的设计原理,可以非常高
MySQL和Lucene(Elasticsearch)索引对比分析
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 大数据真好玩 点击右侧关注,大数据真好玩! 本文是来自略速互联网笔记的分享。 你可以在这里查看原文:http://www.lvesu.com/?uri=/blog/main/cms-611.html 前言 相比于大多数人熟悉的 MySQL 数据库的索引,Elasti

触类旁通Elasticsearch之吊打同行系列:分析篇
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 大数据真好玩 点击右侧关注,大数据真好玩! 目录 一、什么是分析 二、分析文 三、分析API 四、分析器、分词器、分词过滤器 内置分析器分词器分词过滤器 五、N元语法、侧边N元语法、滑动窗口 六、IK中文分词插件 一、什么是分析 分析(analysis)是在文档被
触类旁通Elasticsearch之吊打同行系列:搜索篇
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 大数据真好玩 点击右侧关注,大数据真好玩! 目录 一、搜索请求的结构 1. 确定搜索范围 2. 搜索请求的基本模块 3. 基于请求主体的搜索请求 4. 回复的结构 二、查询和过滤器 1. match 2. term 3. query_string 三、复合查询 1.

ElasticSearch 双数据中心建设在新网银行的实践
本文公众号读者飞熊的投稿,本文主要讲述了ElasticSearch 双数据中心建设在新网银行的实践。 作者简介: 飞熊,目前就职于新网银行大数据中心,主要从事大数据实时计算和平台开发相关工作,对Flink ,Spark 以及ElasticSearch等大数据技术有浓厚兴趣和较深入的理解。 引言 新网银行是作为西部首家互联网银行,一直践行依靠数据和技术驱动业务的发展理念。自开业以来,已经积累了

内网穿透的应用-本地化部署Elasticsearch平替工具OpenObserve并实现无公网IP远程分析数据
文章目录 前言1. 安装Docker2. Docker镜像源添加方法3. 创建并启动OpenObserve容器4. 本地访问测试5. 公网访问本地部署的OpenObserve5.1 内网穿透工具安装5.2 创建公网地址 6. 配置固定公网地址 前言 本文主要介绍如何在Linux系统使用Docker快速本地化部署OpenObserve云原生可观测平台,并结合cpolar内网穿透工
docker 启动ElasticSearch
拉取es镜像 docker pull docker.elastic.co/elasticsearch/elasticsearch:7.15.0 运行 Elasticsearch 容器 docker run -d \--name elasticsearch \-p 9200:9200 \-p 9300:9300 \-e "discovery.type=single-node" \-e "E

Elasticsearch func_score
场景介绍 衰减函数 总结 官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/query-dsl-function-score-query.html 作者公众号: 1.场景介绍 在全文检索中,排序是一个很讲究的事。关键字命中,是全文检索中一个很关键的因素。然而,某些时候,我们关键字的命中可能非常低,或者来两个

ElasticSearch topHits 多文档索引
ElasticSearch termsAggregation、topHits 多文档索引 欢迎添加作者公众号,有什么问题可以留言 demo下载地址:http://www.demodashi.com/demo/16913.html 1.应用场景 我们需要在五种不同的文档中检索数据。比如 商品(goods)、案例(cases)、日记(diaries)、帖子(posts)、商家(shops)。

Java操作Elasticsearch的实用指南
Java操作Elasticsearch的实用指南 一、创建索引二、增删改查 一、创建索引 在ElasticSearch中索引相当于mysql中的表,mapping相当于表结构,所以第一步我们要先创建索引。 假设我们有一张文章表的数据需要同步到ElasticSearch,首先需要根据数据库表创建ES的索引结构。 -- 文章表create table if not exists