本文主要是介绍内网穿透的应用-本地化部署Elasticsearch平替工具OpenObserve并实现无公网IP远程分析数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 1. 安装Docker
- 2. Docker镜像源添加方法
- 3. 创建并启动OpenObserve容器
- 4. 本地访问测试
- 5. 公网访问本地部署的OpenObserve
- 5.1 内网穿透工具安装
- 5.2 创建公网地址
- 6. 配置固定公网地址
前言
本文主要介绍如何在Linux系统使用Docker快速本地化部署OpenObserve云原生可观测平台,并结合cpolar内网穿透工具轻松实现远程访问本地搭建的平台界面管理和可视化各种可观察数据。
OpenObserve是一个基于 Rust 的云原生可观察性平台,可以处理 PB 级的数据,是一款用于日志、指标、分析和追踪,真实用户监控(RUM)的可观测工具,与需要理解和调整大量设置的Elasticsearch相比,它简单明了,易于操作。而且日志存储成本降低约 140 倍,几分钟就能快速部署并运行观察。
除此之外,OpenObserve有着全面的数据支持,如日志、指标、跟踪数据,并完全兼容 OpenTelemetry。具备高级查询功能,支持 SQL 和 PromQL 查询,提供丰富的数据可视化选项。还自带用户界面,无需单独安装,可以无缝替代Elasticsearch。
目前已经获得了11+K的star,支持多平台本地化部署,接下来就详细演示一下如何在ubuntu使用docker快速部署。
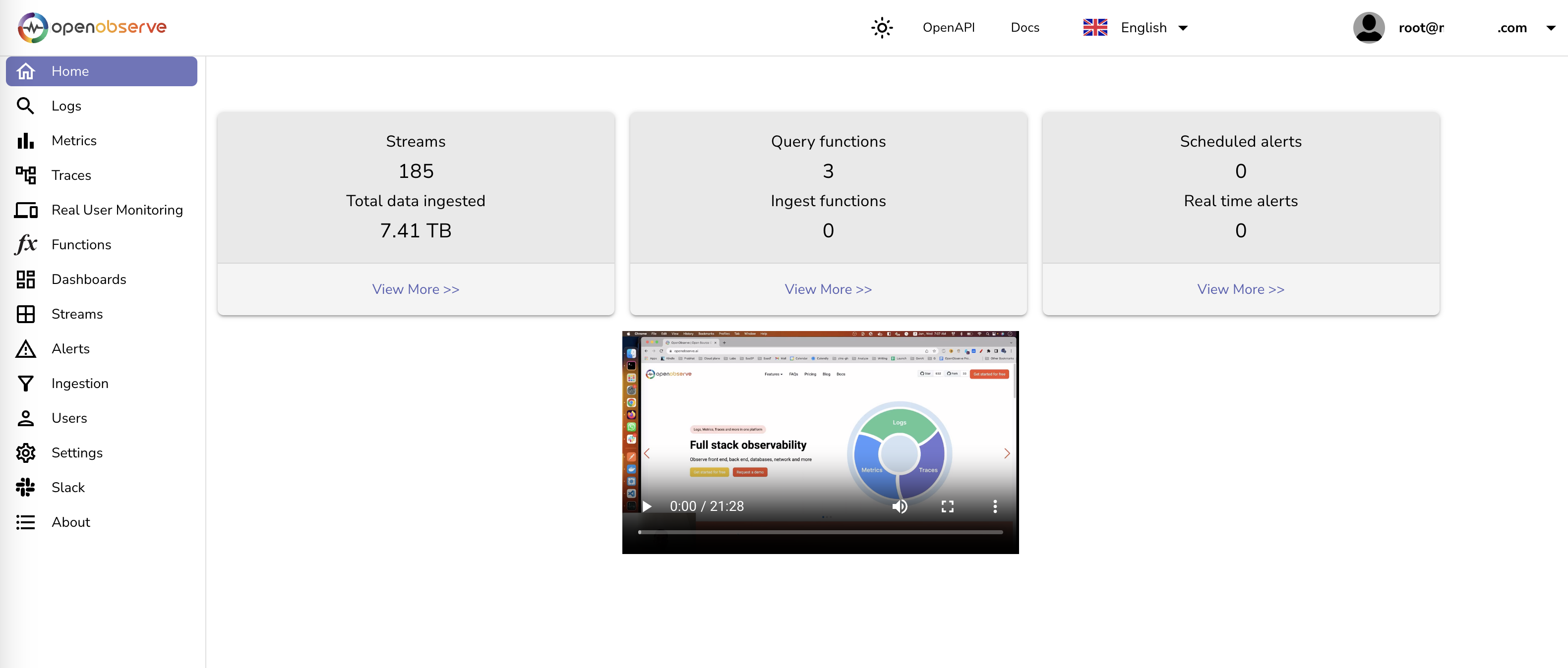
1. 安装Docker
本教程操作环境为Linux Ubuntu系统,在开始之前,我们需要先安装Docker
在终端中执行下方命令安装docker:
sudo curl -fsSL https://github.com/tech-shrimp/docker_installer/releases/download/latest/linux.sh| bash -s docker --mirror Aliyun
如果上边命令中访问不了Github,可以使用Gitee的链接安装:
sudo curl -fsSL https://gitee.com/tech-shrimp/docker_installer/releases/download/latest/linux.sh| bash -s docker --mirror Aliyun
然后启动Docker即可
sudo systemctl start docker
2. Docker镜像源添加方法
如因网络问题拉取不到镜像,
可尝试在终端执行 sudo nano /etc/docker/daemon.json
输入:
{
"registry-mirrors": [
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn"
]
}
保存退出
然后执行:
sudo systemctl restart docker
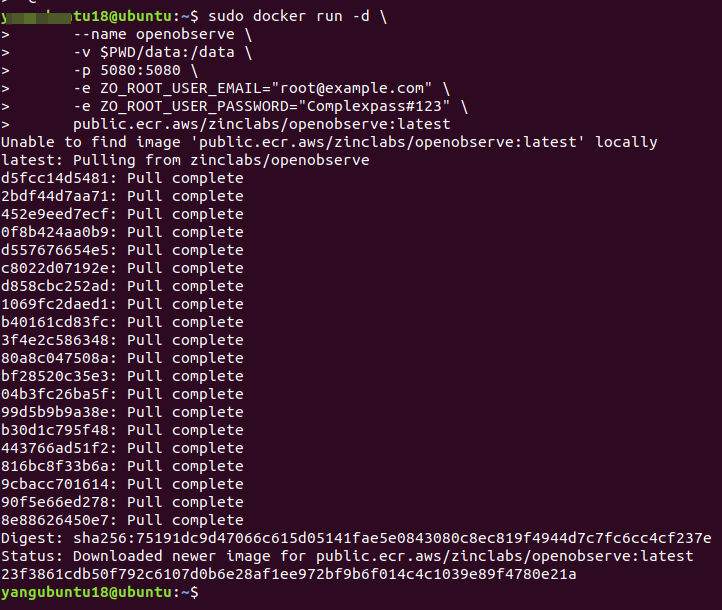
3. 创建并启动OpenObserve容器
执行下方命令:
sudo docker run -d \--name openobserve \-v $PWD/data:/data \-p 5080:5080 \-e ZO_ROOT_USER_EMAIL="root@example.com" \-e ZO_ROOT_USER_PASSWORD="Complexpass#123" \public.ecr.aws/zinclabs/openobserve:latest
4. 本地访问测试
启动OpenObserve容器后,打开浏览器输入ubuntu主机IP加端口号5080即可访问其Web UI 界面。
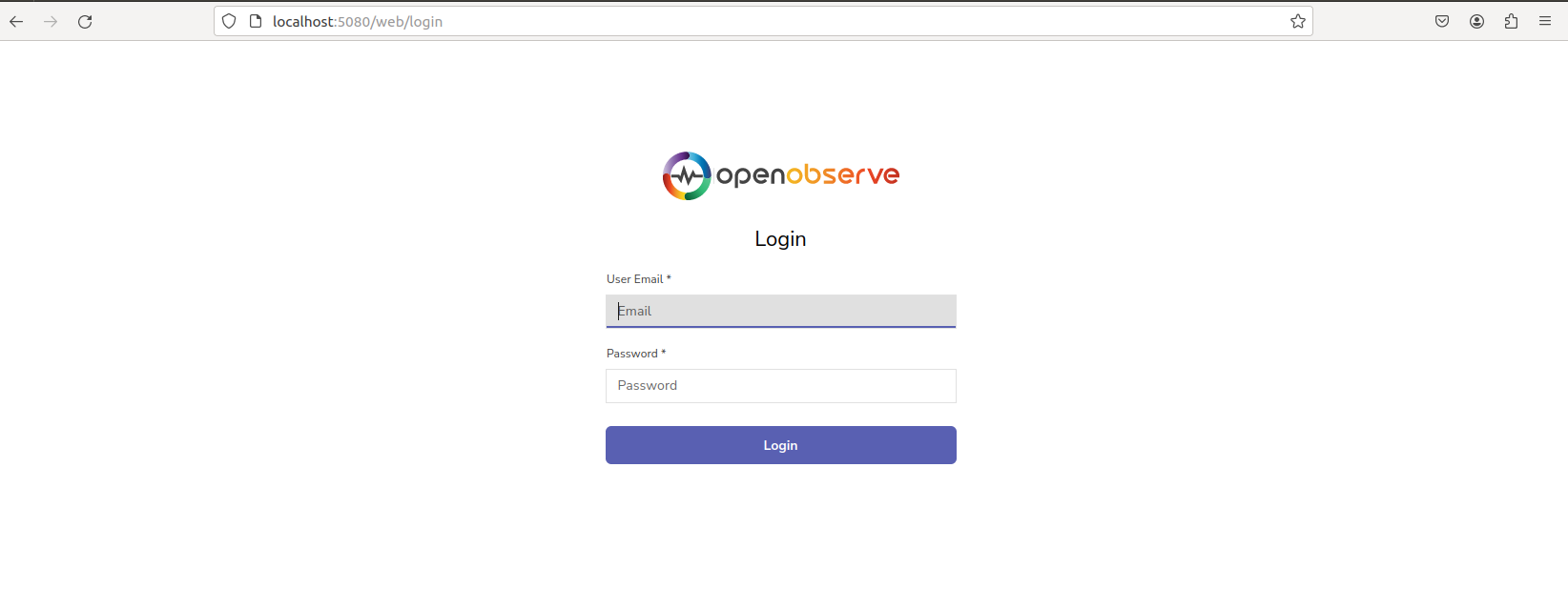
输入启动容器时,设置的登录邮箱(root@example.com)和密码(Complexpass#123)即可登录:
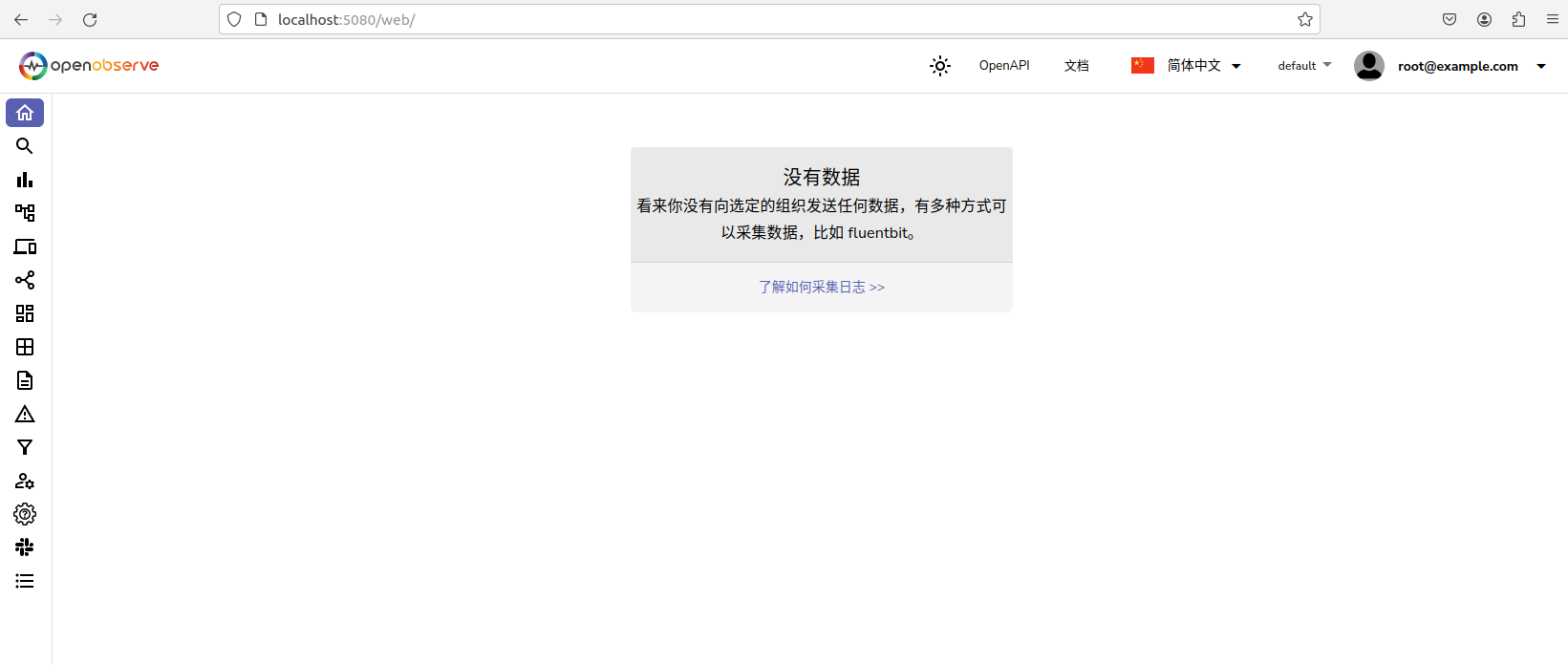
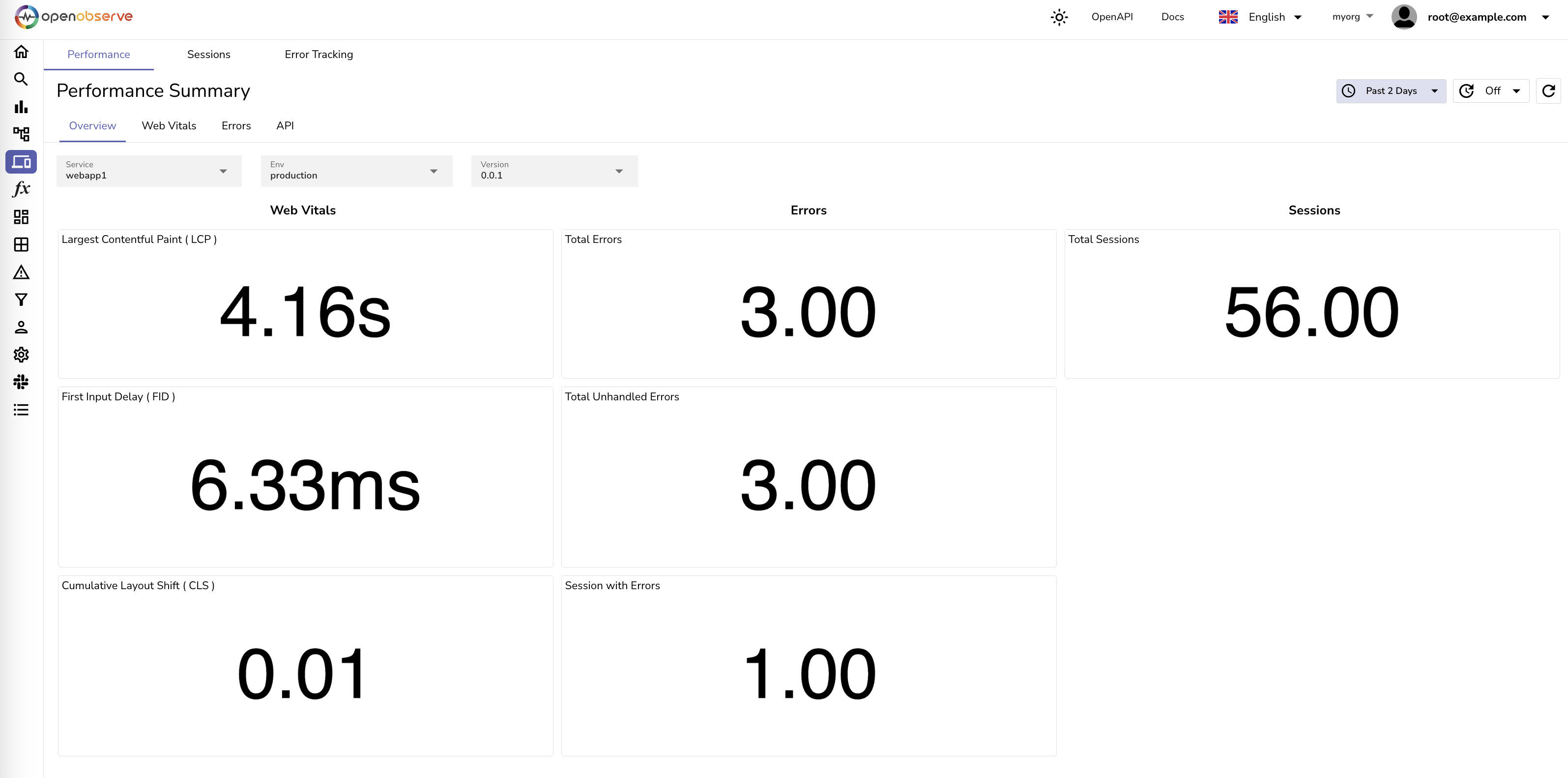
在采集页面,可以使用多种遥测数据的采集方式添加数据:
日志
可视化和仪表板
前端监控
性能分析
会话重放
警报
5. 公网访问本地部署的OpenObserve
不过我们目前只能在本地访问刚刚使用docker部署的OpenObserve平台,如果出门在外,想要随时远程访问在本地内网主机server上部署的O2查看数据,应该怎么办呢?
我们可以使用cpolar内网穿透工具来实现公网环境下的远程访问需求。
5.1 内网穿透工具安装
下面是安装cpolar步骤:
Cpolar官网地址: https://www.cpolar.com
使用一键脚本安装命令
curl https://get.cpolar.sh | sudo sh
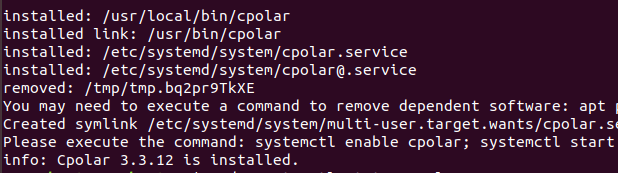
安装完成后,执行下方命令查看cpolar服务状态:(如图所示即为正常启动)
sudo systemctl status cpolar
Cpolar安装和成功启动服务后,在浏览器上输入ubuntu主机IP加9200端口即:【http://localhost:9200】访问Cpolar管理界面,使用Cpolar官网注册的账号登录,登录后即可看到cpolar web 配置界面,接下来在web 界面配置即可:
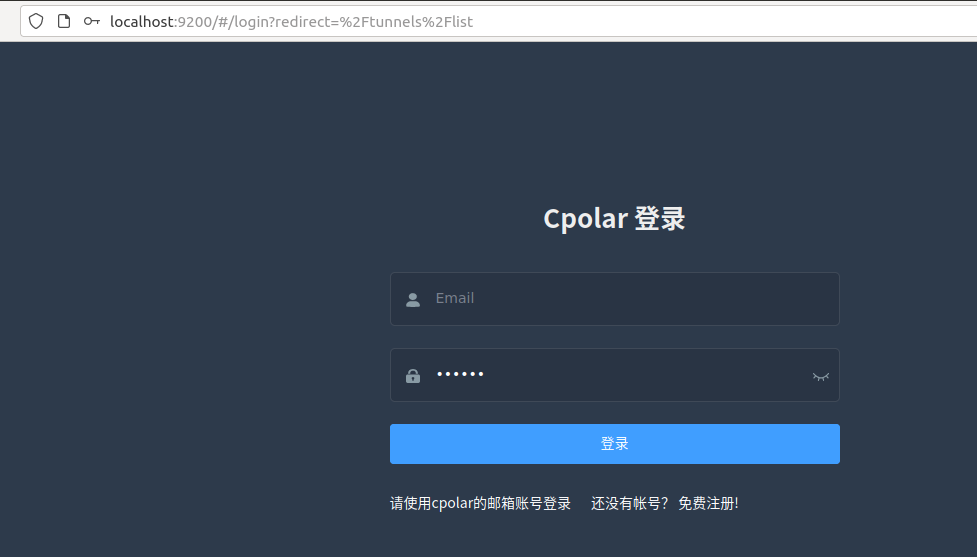
5.2 创建公网地址
登录cpolar web UI管理界面后,点击左侧仪表盘的隧道管理——创建隧道:
- 隧道名称:可自定义,本例使用了:OpenObserve 注意不要与已有的隧道名称重复
- 协议:http
- 本地地址:5080
- 域名类型:随机域名
- 地区:选择China VIP
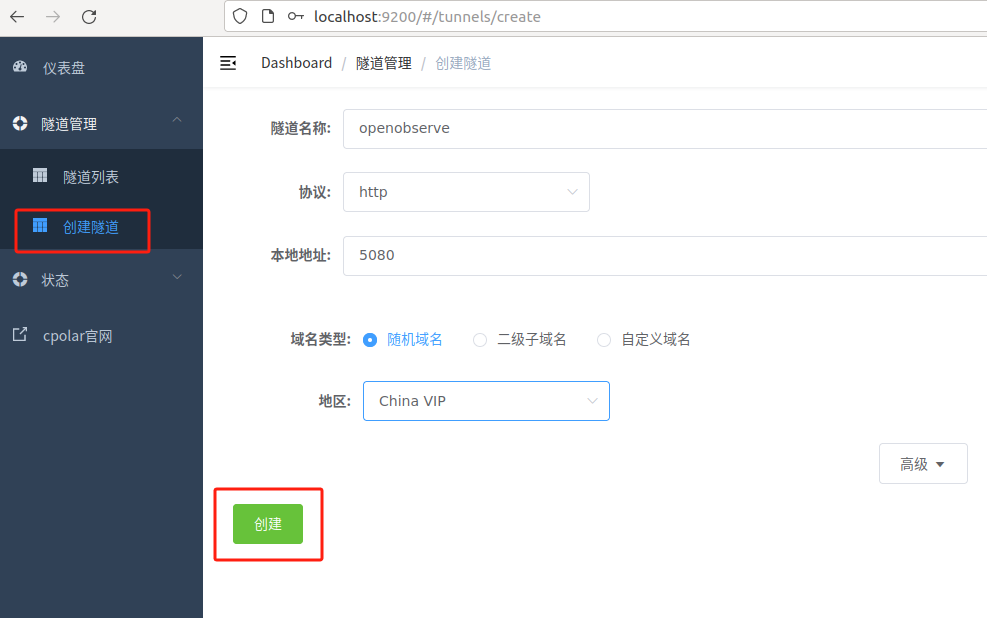
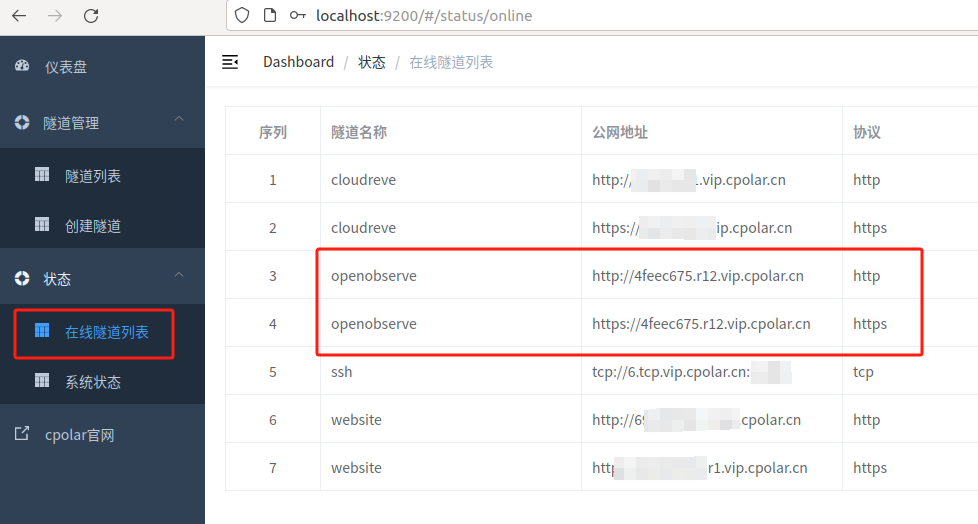
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了两个公网地址,接下来就可以在异地使用其他电脑或手机平板,使用任意一个地址打开浏览器中访问即可。
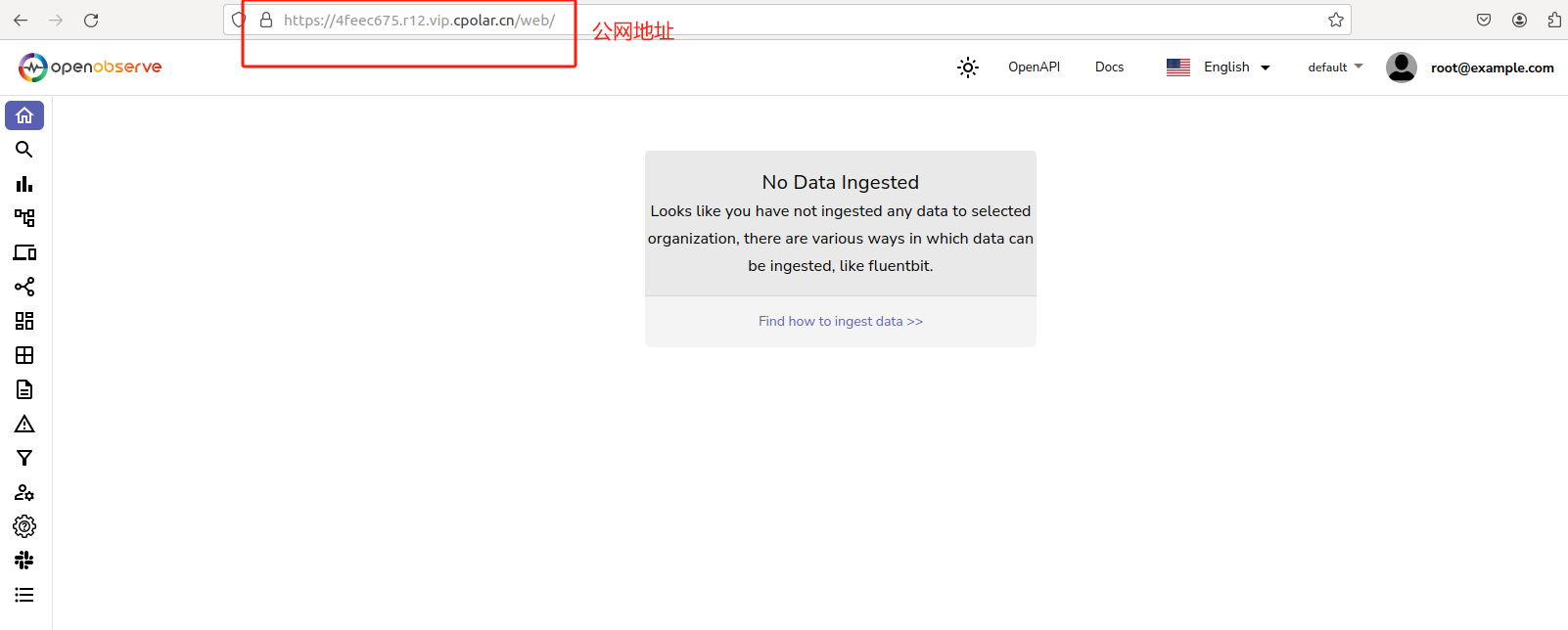
如下图所示,成功实现在异地使用公网地址远程访问本地部署的 OpenObserve平台Web UI 界面 !
小结
为了方便演示,我们在上边的操作过程中使用了cpolar生成的HTTP公网地址隧道,其公网地址是随机生成的。这种随机地址的优势在于建立速度快,可以立即使用。然而,它的缺点是网址是随机生成,这个地址在24小时内会发生随机变化,更适合于临时使用。
如果有长期远程访问本地搭建的OpenObserve或者其他本地部署的服务的需求,但又不想每天重新配置公网地址,还能获得更高的带宽和更多的功能,那我推荐大家为本地部署的服务配置一个固定的二级子域名。
6. 配置固定公网地址
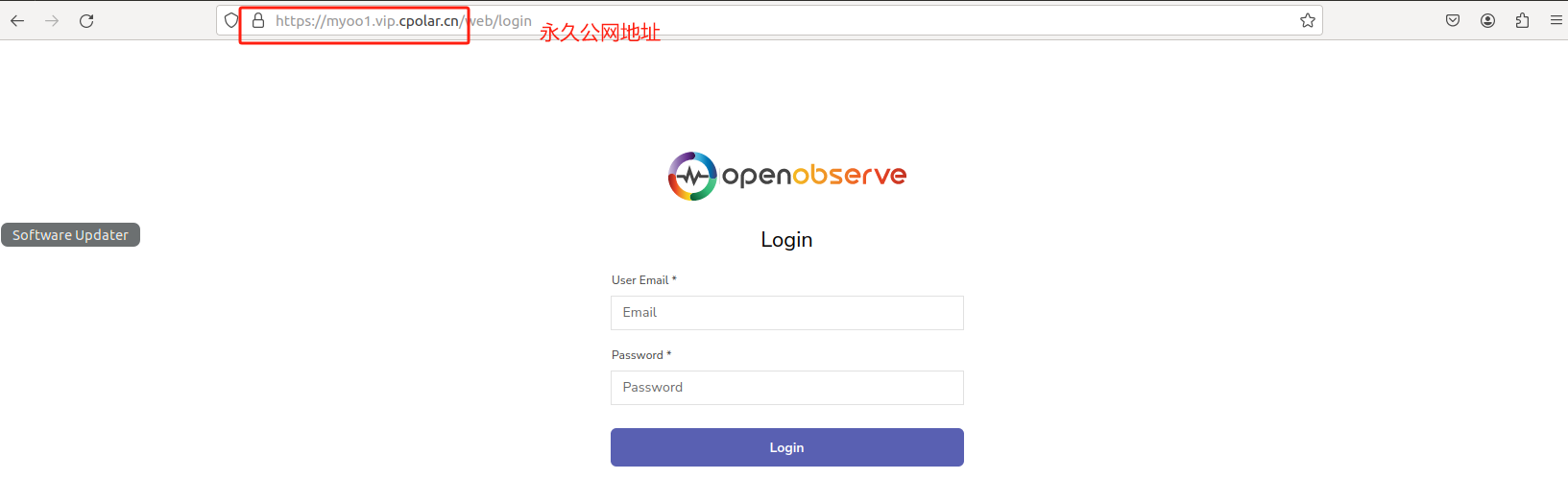
登录cpolar官网,点击左侧的预留,选择保留二级子域名,地区选择China VIP,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称,这里我填写的是myoo1,大家也可以自定义喜欢的名称。
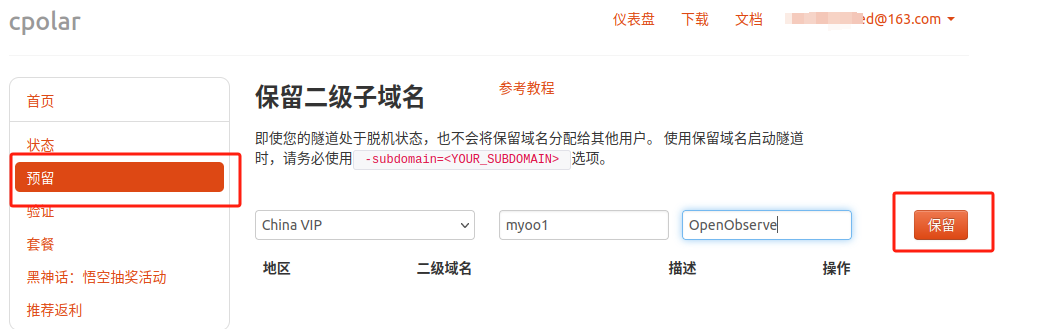
保留成功后复制保留成功的二级子域名的名称:myoo1,返回登录Cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道OpenObserve,点击右侧的编辑:
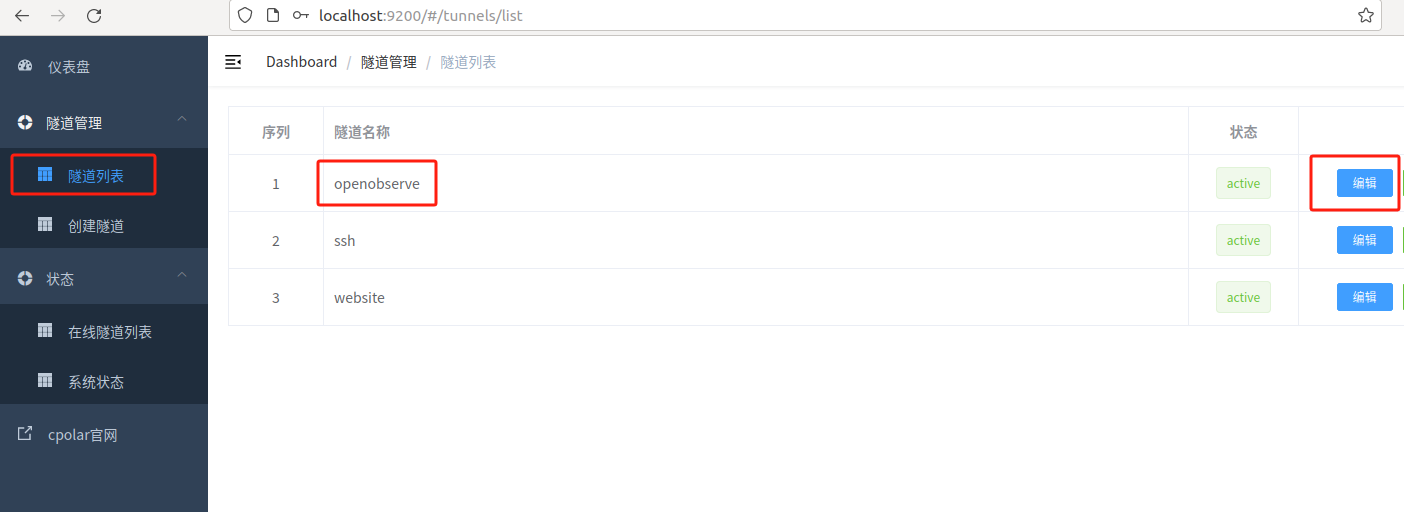
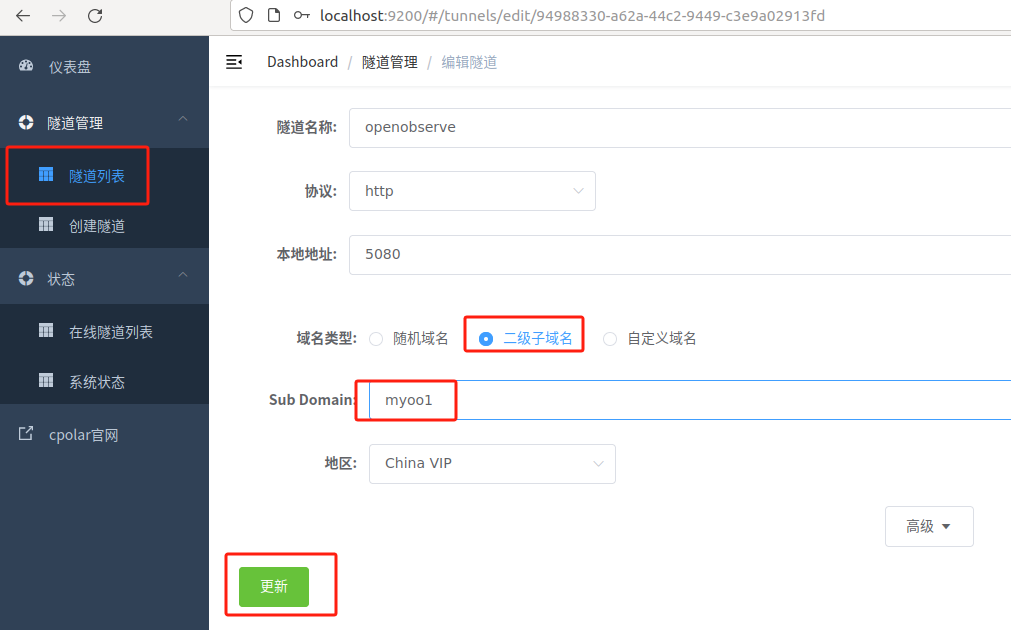
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名:myoo1
- 地区:选择China VIP
点击更新(注意,点击一次更新即可,不需要重复提交)
更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址名称也变成了固定的二级子域名名称的域名:
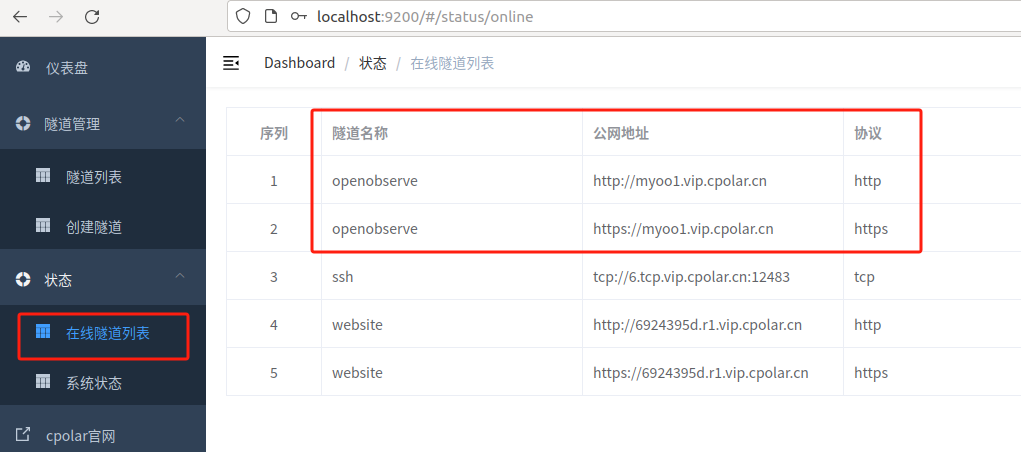
最后,我们使用任意一个固定公网地址在浏览器访问,可以看到访问成功,这样一个固定且永久不变的二级子域名公网地址就设置好了,随时随地都可以远程访问本地部署的 openobserve 平台来观测数据了。
以上就是如何在Linux Ubuntu系统使用Docker本地化部署openobserve,并结合cpolar内网穿透工具配置公网地址,实现随时随地远程访问本地搭建服务的全部流程,感谢您的观看。如果你有公开一个本地网站、远程开发调试、远程控制各种系统桌面等需求,不妨下载体验一下cpolar!
这篇关于内网穿透的应用-本地化部署Elasticsearch平替工具OpenObserve并实现无公网IP远程分析数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


