head专题

跟我一起玩《linux内核设计的艺术》第1章(四)——from setup.s to head.s,这回一定让main滚出来!(已解封)
看到书上1.3的大标题,以为马上就要见着main了,其实啊,还早着呢,光看setup.s和head.s的代码量就知道,跟bootsect.s没有可比性,真多……这确实需要包括我在内的大家多一些耐心,相信见着main后,大家的信心和干劲会上一个台阶,加油! 既然上篇已经玩转gdb,接下来的讲解肯定是边调试边分析书上的内容,纯理论讲解其实我并不在行。 setup.s: 目标:争取把setup.
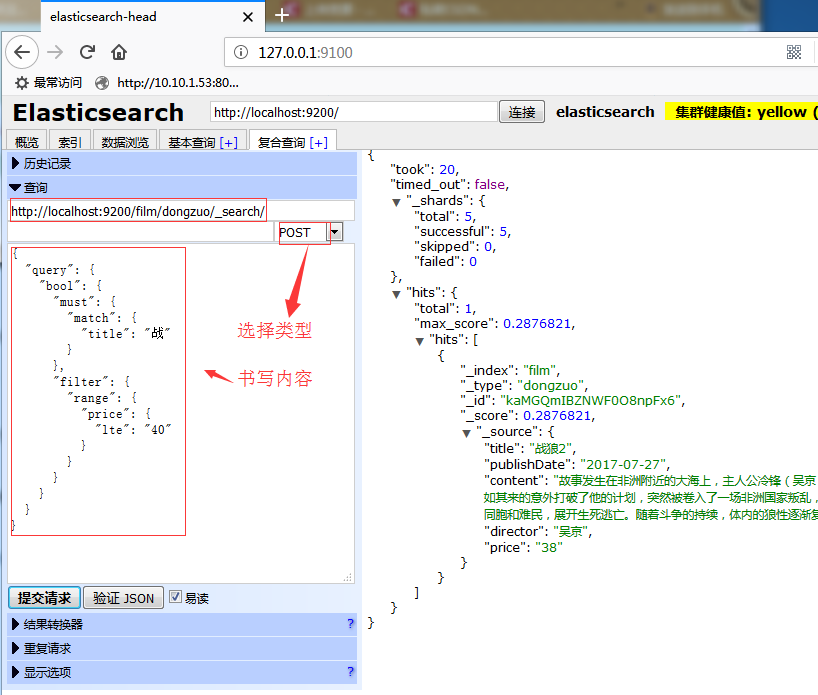
ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询数据
ElasticSearch 6.1.1 通过Head插件,新建索引,添加文档,及其查询; 一、首先启动相关服务: 二、新建一个film索引: 三、建立映射: 1、通过Head插件: POST http://192.168.1.111:9200/film/_mapping/dongzuo/ {"properties": {"title": {"type":
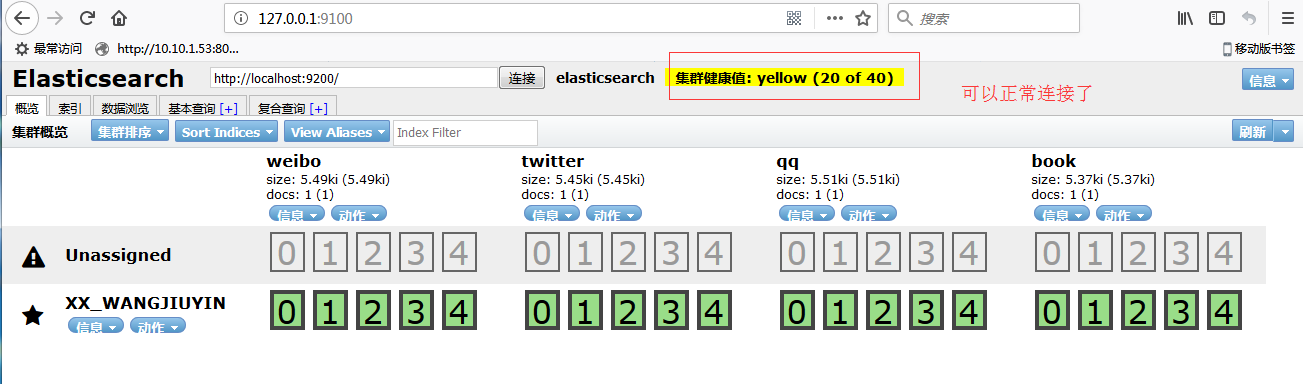
Windows环境下ElasticSearch6.1.1版本安装Head插件
安装Head插件步骤如下: 1、下载node.js ,网址:https://nodejs.org/en/ 安装node到D盘。如D:\nodejs。 把NODE_HOME设置到环境变量里(安装包也可以自动加入PATH环境变量)。测试一下node是否生效: 2、安装grunt grunt是一个很方便的构建工具,可以进行打包压缩、测试、执行等等的工作,5.0里的head插件就是通过grunt

Linux中head和tail方法的使用
head -5 1.txt 从第五行开始到末尾 head –n 5 1.txt 同上 head –n +5 1.txt 同上 head –n -5 1.txt 除了最后五行的所有内容 少后五行 tail -5 1.txt 最后五行内容 tail –n 5 1.txt 同上 tail –n -5 1.txt 同上 tail –n +5 1.txt 从正数第五行到结尾的所有内容

less、more、head、tail命令解析集合
一、整体认识 命令使用优点常见使用方式less可以浏览文件内容,它可以用于查看大型文件,而不需要将整个文件加载到内存中。按下空格键向下翻页,按下b键向上翻页,按下q键退出浏览more类似于less,也是用于浏览文件内容的命令,但它不支持向上翻页。 按下空格键向下翻页,按下q键退出浏览。 head用于查看文件的前几行。head [选项] [文件名]。常用选项有-n,指定显示前几行,默认为显示前10

《Head First设计模式》之命令模式
命令模式就是将方法调用(Method invocation)封装起来。通过封装方法调用,我们可以把运算块包装成形,所以调用此运算的对象不需要关心事情是如何进行的,只要知道如何使用包装成形的方法来完成它就可以了。通过封装方法调用,可以用在以下场景:记录日志或者重复使用这些封装来实现撤销(undo)。 我对于命令模式的理解是:当我需要做一件事的时候,我只需要给出一个命令,这个命令中的
git中的head到底是怎么工作的,十分钟就够了
git中的head到底是怎么工作的,十分钟就够了 背景HEAD 实际上是一些不同的东西文件 .git/HEADHEAD如同git show HEAD下一步:所有输出格式git status:“在主分支上”或“HEAD 分离”分离 HEAD 状态git log:(HEAD -> main)合并冲突:<<<<<<< HEAD很令人困惑 关于术语一致性的一些想法就这样! 背景 一般上讲

在head的style标签中直接添加css样式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>内嵌样式示例</title> <style> /* 全局样式 */

brew update 报错 “fatal: Could not resolve HEAD to a revision“
参考 https://www.jianshu.com/p/b2de788c3c6d
Linux命令学习笔记(4)----head命令、tail命令
写在前面 只是记录一下自己学过的命令,毕竟这些命令太多,每一个的用法也很多,所以只记录自己学过的 head命令 介绍:该命令只会显示文件的前几行内容, 语法:head[选项] 文件名 选项: -n:显示头部n行内容,默认为10 -v:显示内容的时候,将文件名显示在顶部 示例: 查看1.tx
O'Reilly之深入浅出Head First系列的中文版与英文版合集
来源url:http://blog.csdn.net/torchfire/article/details/12320479 Head First系列是O’Reilly出版社最成功的系列图书,自问世以来受到了无数读者的喜爱,并屡获大奖。其图文并茂,讲述编程技术由浅到深,也被称为“深入浅出”系列,是不可多得的各阶段程序员的参考学习资料。 收藏的中文版: 深入浅出数据分析(美

Linux基础1-基本指令5(more,less,head,tail, | ,find)
本章继续整理其他linux基本指令 一.本章重点 1.more和less命令查看大文本 2.head和tail命令查看小文本和日志 3.使用管道多次处理信息 4.find指令 二.more和less more命令和less命令常用来查看大文本,其中less可以使用上下键快速浏览文本
Elasticsearch的基本操作CURL/PUT/POST/GET/DSL/MGET/HEAD/更新/删除/批量操作bulk/版本控制等等
CURL命令 简单认为是可以在命令行下访问url的一个工具 curl是利用URL语法在命令行方式下工作的开源文件传输工具,使用curl可以简单实现常见的get/post请求。 curl -X 指定http请求的方法 HEAD GET POST PUT DELETE -d 指定要传输的数据 比如:curl -XHEAD 'https://www.baidu.com' CURL建立索引库 c

Light-Head R-CNN解读
最近对检测很有兴趣哎,这些天写了好几个相关博客了,下一步准备写SSD和YOLO了,近段时间要把检测吃透 Light-Head R-CNN: In Defense of Two-Stage Object Detector,名字很有趣,守护two stage检测器的尊严。 Motivation region-free的方法如YOLO,SSD,速度是很快,但是总体来说精度上还是不如两段的re

head查看文件前n行
3.12 head查看文件前n行 3.12.1 语法 用法:head [选项]… [文件]… 注意:head查看文件的前n行,默认n=10 3.12.2 常用参数 【-c [-]#】 显示文件前#个字节的内容,如果#前面加上-表示除了每个文件最后#个字节外,其余全部显示。【-n [-]#】显示文件前#行,如果#前面加上-表示,除了每个文件最后#行外其余全部显示 3.12.3 简单示
《Head First Java》笔记(2)
2.1 面向过程与面向对象之间的战争 面向过程与面向对象之间的战争是由下面一则小故事引起的。 从前,有一个软件小铺,该小铺的老板娘(同时也是项目经历)手下有两个小兵:阿朱和阿娇。有一天,老板娘故意刁难两个兵,并且让她两进行比赛,看谁的程序写的好。要求:在图形接口画出正方形、圆形与三角形。当用户点选某个图形时,图形要顺时针旋转360度,并且根据形状的不同而播放不同的AIF音效的音乐文件。 最终赢

《Head First Java》笔记(1)
1.1 Java的工作方式: 源代码(.java文件)——>javac程序来编译这个源代码——->编译成.class文件(这个文件是由字节码组成的)——->启动java虚拟机来运行.class文件 1.2 Java的程序结构 什么是源文件? –>源文件(扩展名为.java)带有类的定义。类用来表示程序的一个组件,小程序或许只会有一个类。类的内容必须包在花括号内。 什么是类? –>类

从head of line到http3/quic
1.head of line 队头阻塞 什么是队头阻塞呢?就是第一个人的问题影响了后面的人.一堆人排队过桥,第一个卡住了,那么后面的人谁也别想过去. tcp: tcp协议为了保证帧的顺序行,每个帧都有编号.接受者会按照编号对数据进行处理. 1.如果2,3,4都传输过去了,但是1没有传输过去,那么2,3,4还是不可读的.同时1234也不能从写缓存中滑走. 2
多头注意力机制(Multi-Head Attention)
文章目录 多头注意力机制的作用多头注意力机制的工作原理为什么使用多头注意力机制?代码示例 多头注意力机制(Multi-Head Attention)是Transformer架构中的一个核心组件。它在机器翻译、自然语言处理(NLP)等领域取得了显著的成功。多头注意力机制的引入是为了增强模型的能力,使其能够从不同的角度关注输入序列的不同部分,从而捕捉更多层次的信息。 多头注意力机
html5元素标签基础 head 部分
<!doctype html><!--html5声明--> <html> <head> <meta charset="utf-8"/> <!-- 设置当前页面支持的字符集 html5--> <title>所有的html基本标签</title> <!-- 当前页面的标题--> <!--已下几个meta 的属性 都是对搜索引擎进行优化(描述以及关
内核学习——1、list_head
双向循环链表:list_head 头节点head是不使用的: struct list_head { struct list_head *next, *prev; }; 结构体中没有数据域,所以一般把list_head嵌入到其他结构中使用 struct file_node { char c; struct list_head node; }; 此时,list_head就作为它父结构体中的一个成员了,
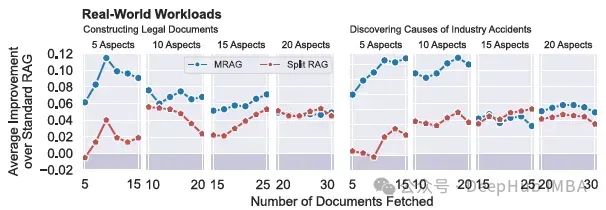
Multi-Head RAG:多头注意力的激活层作为嵌入进行文档检索
现有的RAG解决方案可能因为最相关的文档的嵌入可能在嵌入空间中相距很远,这样会导致检索过程变得复杂并且无效。为了解决这个问题,论文引入了多头RAG (MRAG),这是一种利用Transformer的多头注意层的激活而不是解码器层作为获取多方面文档的新方案。 MRAG 不是利用最后一个前馈解码器层为最后一个令牌生成的单个激活向量,而是利用最后一个注意力层为最后一个令牌生成的H个单独的激活向量,然
linux 0.11 内核学习 -- head.s
# # 这段代码被连接到system模块的最前面,这也是它为什么称之为head.s的原因。 # 从这里开始内核完全运行在保护模式下。head.s采用的是at&t格式的 # 汇编。注意的是代码中的赋值方向是从左到右。 # # 这段程序实际上是出于内存的绝对地址0开始处。首先是加载各个数据段寄存器。 # 重新设置全局描述符表gdt --> 检测a20地址线是否真的开启,没有开启,loo

Transformer中的Self-Attention和Multi-Head Attention
2017 Google 在Computation and Language发表 当时主要针对于自然语言处理(之前的RNN模型记忆长度有限且无法并行化,只有计算完ti时刻后的数据才能计算ti+1时刻的数据,但Transformer都可以做到) 文章提出Self-Attention概念,在此基础上提出Multi-Head Atterntion 下面借鉴霹雳吧啦博主的视频进行学习: Se
Fontconfig head is null, check your fonts or fonts configuration问题解决
报错信息: Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [R equest processing failed: com.alibaba.excel.exception.ExcelGenerateException: java.lang.InternalError
汇总|目标检测中的数据增强、backbone、head、neck、损失函数
一、数据增强方式 random eraseCutOutMixUpCutMix色彩、对比度增强旋转、裁剪 解决数据不均衡: Focal losshard negative example miningOHEMS-OHEMGHM(较大关注easy和正常hard样本,较少关注outliners)PISA 二、常用backbone VGGResNet(ResNet18,50,100)Re