本文主要是介绍【Transformer-BEV编码(7)】Sparse4D源代码,在mmdet里面增加cuda的插件deformable_aggregation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 插件位置
- 在论文V3中的“地位”
- 看看具体的代码
- 1. deformable_aggregation.py
- 2. deformable_aggregation.cpp
- 3. deformable_aggregation_cuda.cu
- 3.1 双线性插值bilinear_sampling()
- 3.2 bilinear_sampling_grad() 梯度计算
- 3.3 `deformable_aggregation_grad()` 和 `deformable_aggregation_grad_kernel()`
- 3.4 deformable_aggregationl()
- 4. __init__.py
- 5 . setup.py 编译
插件位置
我们在源代码
/var/files/Sparse4D-main/projects/mmdet3d_plugin/ops/src
ops里面有新算子
今天来好好看看这个可变性聚合插件。
在官方的ops 安装方法是这样的
Compile the deformable_aggregation CUDA opcd projects/mmdet3d_plugin/ops
python3 setup.py develop
cd ../../../
编译后会有一个动态库so。
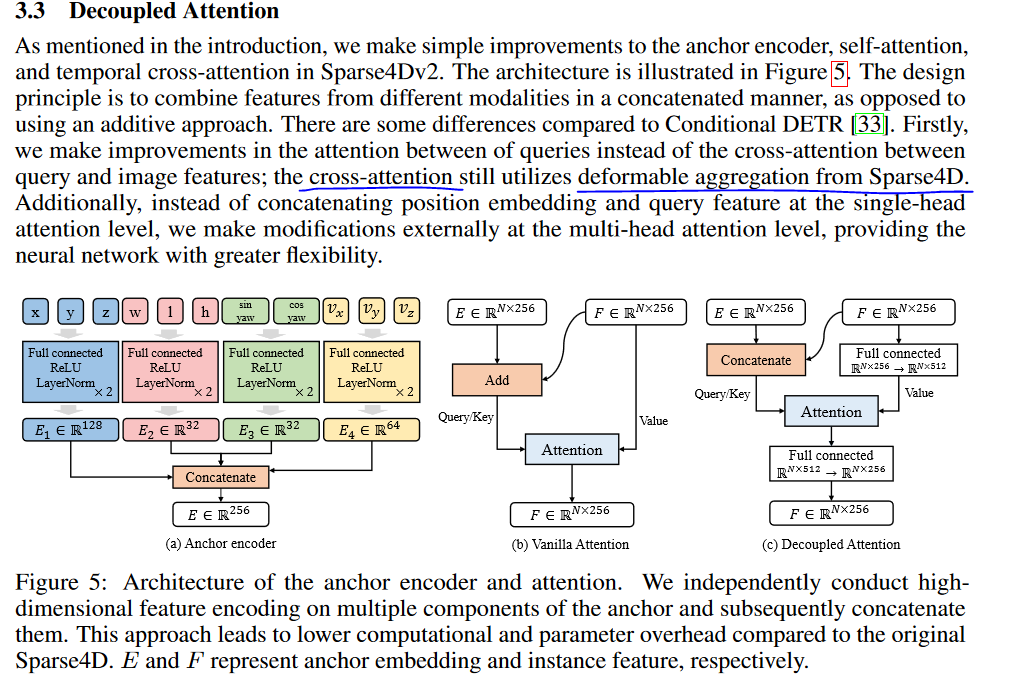
在论文V3中的“地位”
对Sparse4Dv2中的锚编码器、自注意和时间交叉注意进行了简单的改进。设计原则是以串联的方式将不同模态的特征组合起来,而不是使用加法方法。
看看具体的代码
1. deformable_aggregation.py
这个是实现一个接口,使用自定义算子。
一个自定义的PyTorch函数,用于实现可变形聚合(Deformable Aggregation)操作。可变形卷积(Deformable Convolution)是一种特殊的卷积方式,其中卷积核的采样位置可以根据输入特征进行动态调整。
@staticmethod
def forward(ctx, mc_ms_feat, spatial_shape, scale_start_index, sampling_location, weights):
这里定义了一个静态方法 forward,它描述了前向传播的计算过程。ctx 是一个上下文对象,用于保存前向传播过程中的信息,以便在反向传播时使用。mc_ms_feat、spatial_shape、scale_start_index、sampling_location 和 weights 是前向传播所需的输入参数。
output = deformable_aggregation_ext.deformable_aggregation_forward( mc_ms_feat, spatial_shape, scale_start_index, sampling_location, weights,
)
这里调用了一个名为 deformable_aggregation_ext 的外部模块(或库)中的 deformable_aggregation_forward 函数来执行实际的前向传播计算。
ctx.save_for_backward( mc_ms_feat, spatial_shape, scale_start_index, sampling_location, weights,
)
在反向传播中,通常需要访问前向传播中的某些输入或中间结果。ctx.save_for_backward 方法用于保存这些信息,以便在后续的反向传播中使用。
在反向传播中,使用了@staticmethod 和 @once_differentiable
@staticmethod表示这个方法是静态方法,不需要类的实例就可以调用,它只与类本身关联。@once_differentiable可能是一个自定义装饰器(因为这不是PyTorch的标准装饰器),用于指定这个方法只应该被分化一次。在某些复杂的autograd函数中,这有助于优化性能或避免不必要的重复计算。
def backward(ctx, grad_output):
ctx是从forward方法传递过来的上下文对象,它保存了前向传播中需要的信息。grad_output是关于output的梯度,即损失函数对output的导数。
( mc_ms_feat, spatial_shape, scale_start_index, sampling_location, weights,
) = ctx.saved_tensors
我们从 ctx 中恢复了在 forward 方法中保存的变量。这些变量在 backward 方法中用于计算梯度。
deformable_aggregation_ext.deformable_aggregation_backward( mc_ms_feat, spatial_shape, scale_start_index, sampling_location, weights, grad_output.contiguous(), grad_mc_ms_feat, grad_sampling_location, grad_weights,
)
调用外部模块(或库)中的 deformable_aggregation_backward 函数来计算梯度。该函数接收前向传播中的输入参数、输出梯度,以及用于存储计算出的梯度的张量。
return ( grad_mc_ms_feat, None, None, grad_sampling_location, grad_weights,
)
最后,我们返回计算出的梯度。注意,这里返回了 None 值对应于 spatial_shape 和 scale_start_index,这通常意味着这两个参数不需要梯度(即它们在反向传播中不被更新)。
这个 backward 方法与 forward 方法一起,使 DeformableAggregationFunction 类能够作为一个完整的、可微分的PyTorch操作,从而可以无缝地集成到神经网络中并进行训练。
2. deformable_aggregation.cpp
deformable_aggregation_forward 函数
这是一个使用 PyTorch 框架的函数,用于定义前向传播操作。
它接收 PyTorch 张量作为输入,并返回聚合后的张量作为输出。
函数首先使用 at::DeviceGuard 和 at::cuda::OptionalCUDAGuard 来确保操作在正确的设备上执行(CPU 或 GPU)。
然后,它提取输入张量的尺寸信息,并将这些张量的数据指针转换为相应的类型。
接着,它创建一个全零的张量 output,其尺寸基于输入张量的尺寸。
deformable_aggregation(output.data_ptr<float>(),mc_ms_feat, spatial_shape, scale_start_index, sampling_location, weights,batch_size, num_cams, num_feat, num_embeds, num_scale, num_anchors, num_pts, num_groups);
最后,它调用 deformable_aggregation 函数来执行实际的聚合操作,并将结果存储在 output 张量中。
还是有一个反向传播的函数。
deformable_aggregation_backward 函数
deformable_aggregation_grad(mc_ms_feat, spatial_shape, scale_start_index, sampling_location, weights,grad_output, grad_mc_ms_feat, grad_sampling_location, grad_weights,batch_size, num_cams, num_feat, num_embeds, num_scale, num_anchors, num_pts, num_groups);
最后绑定 pybind11 给python 使用
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {m.def("deformable_aggregation_forward",&deformable_aggregation_forward,"deformable_aggregation_forward");m.def("deformable_aggregation_backward",&deformable_aggregation_backward,"deformable_aggregation_backward");
}3. deformable_aggregation_cuda.cu
3.1 双线性插值bilinear_sampling()
首先定义了 双线性插值,这个常用于图像处理或深度学习中的空间变换任务,以根据浮点数坐标估算像素值。这个方案比较多,爱琢磨的可以到找找网上资料。这个bilinear_sampling函数执行的是双线性插值(Bilinear Interpolation)操作,常用于图像处理或深度学习中的空间变换任务,以根据浮点数坐标估算像素值。
以下是对该函数的详细解释:
-
参数:
bottom_data: 输入数据的指针,通常指向一个二维数组或类似结构。height和width: 输入数据的高度和宽度的尺寸。num_embeds: 每个像素的嵌入数或通道数,通常用于表示图像的颜色通道数或其他特征数。h_im和w_im: 需要插值的浮点数坐标。base_ptr: 指向bottom_data中某个起始位置的偏移量。
-
计算插值坐标:
h_low和w_low: 通过向下取整h_im和w_im得到最近的整数坐标。h_high和w_high:h_low和w_low各加1,得到另一个近邻的整数坐标。lh和lw: 分别计算h_im和w_im与对应的h_low和w_low之间的差值。hh和hw: 计算与h_high和w_high之间的差值,即1 - lh和1 - lw。
-
计算偏移量:
w_stride和h_stride: 用于从bottom_data中定位特定位置的像素值。h_low_ptr_offset、h_high_ptr_offset、w_low_ptr_offset和w_high_ptr_offset: 根据h_low、h_high、w_low和w_high计算出的偏移量。
一旦我们有了这些偏移量,我们就可以通过将它们相加并与base_ptr(一个指向bottom_data中某个起始位置的偏移量)相结合,来计算四个最近邻点的确切位置。
例如,为了计算较低行和较低列交点处的像素位置,我们会使用以下公式:
const int ptr1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
这允许我们直接从bottom_data数组中读取该位置的像素值。
这里有个知识点,多维张量在内存的存储方式影响插值的细节。这些偏移量基于输入的图像高度(height)、宽度(width)和每个像素的嵌入数或通道数(num_embeds)。 在之前的博客OpenCV读取图像时按照BGR的顺序HWC排列,PyTorch按照RGB的顺序CHW排列 中说了,在HWC格式中,最小的像素坐标是(0,0),如果像素点的坐标为(i, j),且其在第k个通道中的值需要被访问,那么其在内存中的存储位置可以表示为:
o f f s e t = i ∗ W ∗ C + j ∗ C + k offset = i * W * C + j * C + k offset=i∗W∗C+j∗C+k
也可以写成
o f f s e t = ( i ∗ W + j ) ∗ C + k offset = (i * W + j) * C + k offset=(i∗W+j)∗C+k
其中:
- i 表示像素点的高度索引(在0到H-1之间,H是图像的高度)。
- j 表示像素点的宽度索引(在0到W-1之间,W是图像的宽度)。
- k 表示通道索引(在0到C-1之间,C是通道数,对于RGB图像,C通常是3)。
- W 表示图像的宽度。
- C 表示通道数。
代码实现上采用:
const int w_stride = num_embeds;// Cconst int h_stride = width * w_stride;// W *Cconst int h_low_ptr_offset = h_low * h_stride;//i *W *Cconst int h_high_ptr_offset = h_low_ptr_offset + h_stride;// (i+1) *W *Cconst int w_low_ptr_offset = w_low * w_stride;// j *Cconst int w_high_ptr_offset = w_low_ptr_offset + w_stride;//(j+1) *C
-
读取值:
- 根据上述计算出的偏移量,从
bottom_data中读取四个最近邻点的值(v1, v2, v3, v4)。 - 在读取之前,会检查坐标是否在有效范围内,以防止数组越界。
- 根据上述计算出的偏移量,从
-
计算权重:
- 根据
lh、lw、hh和hw计算四个插值权重(w1, w2, w3, w4)。
- 根据
-
插值计算:
- 使用这四个值和对应的权重进行双线性插值计算,得到最终的插值结果
val。
- 使用这四个值和对应的权重进行双线性插值计算,得到最终的插值结果
-
返回值:
- 返回计算得到的插值结果
val。
- 返回计算得到的插值结果
这个函数主要用于在图像处理中,当需要从一个浮点坐标获取像素值时,可以通过这个函数基于其最近的四个整数坐标上的像素值进行插值计算,从而得到一个估计值。这在空间变换网络、图像缩放、旋转等任务中非常有用。
一个简化流程
[ 开始 ] | V [ 输入参数:bottom_data, height, width, num_embeds, h_im, w_im, base_ptr ] | V [ 计算 h_low, h_high, w_low, w_high, lh, lw, hh, hw ] | V [ 计算 w_stride, h_stride, h_low_ptr_offset, h_high_ptr_offset, w_low_ptr_offset, w_high_ptr_offset ] | V [ 设置 v1, v2, v3, v4 为 0 ] | V [ 如果 h_low 和 w_low 在有效范围内,则计算 ptr1 并读取 v1 = bottom_data[ptr1] ] | V [ 如果 h_low 和 w_high 在有效范围内,则计算 ptr2 并读取 v2 = bottom_data[ptr2] ] | V [ 如果 h_high 和 w_low 在有效范围内,则计算 ptr3 并读取 v3 = bottom_data[ptr3] ] | V [ 如果 h_high 和 w_high 在有效范围内,则计算 ptr4 并读取 v4 = bottom_data[ptr4] ] | V [ 计算权重 w1, w2, w3, w4 ] | V [ 计算插值结果 val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4) ] | V [ 返回插值结果 val ] | V [ 结束 ]
认真花30分钟,就可以看懂,非常简单。
这个主要是在 GPU 上并行计算,因此代码中是没有for 循环的,而是采用调用时分配GPU线程ID来实现对每一个像素点的访问,来实现并行计算。
本项目中这个算子作为一个小算子,是deformable_aggregation_kernel 核函数的一部分。
3.2 bilinear_sampling_grad() 梯度计算
接下来,我们看到一个梯度版本的插值采样核函数bilinear_sampling_grad(),bilinear_sampling 用于 推理过程中的计算,在训练过程中,需要保证这个经过双线性插值后,权重依然可以被更新,因此需要写相关的代码。
双线性插值的梯度更新原理基于链式法则,即在反向传播过程中,通过计算损失函数对插值结果的梯度,进一步求得插值过程中各参数(如输入数据、采样位置、权重等)的梯度。这些梯度随后用于更新相应的参数,以优化网络性能。
在双线性插值中,更新的对象主要包括:
- 特征图的梯度(grad_mc_ms_feat):通常是关于某个特定特征图的梯度,这个特征图可能是网络中的中间表示
const float top_grad_mc_ms_feat = grad_output * weight;
const float w1 = hh * hw;
atomicAdd(grad_mc_ms_feat + ptr1, w1 * top_grad_mc_ms_feat);
top_grad_mc_ms_feat代表了上层网络(或当前层之前的层)传递下来的梯度,具体是与当前插值操作相关的特征图的梯度。在反向传播过程中,这些梯度用于计算当前层的梯度,进而更新当前层的参数。grad_mc_ms_feat的作用是存储与某个特征图或网络层相关联的梯度信息。在深度学习的反向传播过程中,梯度信息用于更新网络的权重和参数。grad_mc_ms_feat 可能表示一个具体的特征图的梯度,而这个特征图是通过双线性插值或其他操作得到的。通过 atomicAdd 操作,我们可以将计算出的梯度贡献累加到 grad_mc_ms_feat 所指向的内存位置,从而更新相应的梯度信息。
- 采样位置 grad_sampling_location
grad_w_weight = lh * v4 +lh * v3+ hh * v2+ hh * v1;atomicAdd(grad_sampling_location, width * grad_w_weight * top_grad_mc_ms_feat);atomicAdd(grad_sampling_location + 1, height * grad_h_weight * top_grad_mc_ms_feat);
top_grad_mc_ms_feat代表了上层网络(或当前层之前的层)传递下来的梯度grad_h_weight计算相关梯度的总和
- 权重grad_weights:是关于网络权重或参数的梯度,用于在训练过程中更新这些权重。
四个点与对应权重的乘积之和,并累加到 grad_weights 上
const float val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
atomicAdd(grad_weights, grad_output * val);
- grad_output 来自上一层的梯度信息。
- val 双线性插值中的某个采样点的值。
- grad_weights 是需要累加的梯度变量,通常对应于网络中的权重或参数。
- grad_output * val 可能表示某个采样点对输出梯度的贡献
bilinear_sampling_grad() 在计算梯度,去更新某些参数吧。
3.3 deformable_aggregation_grad() 和 deformable_aggregation_grad_kernel()
接下来,我们看看两个 deformable_aggregation_grad() 和 deformable_aggregation_grad_kernel() 函数。通常表示两个不同的函数或Kernel,它们在功能上有显著的区别。从它们的名字可以推测出它们各自的作用:
-
deformable_aggregation_kernel():
- 这个函数或Kernel很可能是一个可变形聚合操作。在可变形卷积(Deformable Convolution)的上下文中,可变形聚合通常指的是根据输入特征图的局部形状变化来动态地调整卷积核的采样位置。这样可以使卷积核具有更大的灵活性,更好地适应目标物体的形状变化。因此,
deformable_aggregation()的作用可能是根据输入的变形参数,对特征图进行聚合操作,生成输出特征图。
- 这个函数或Kernel很可能是一个可变形聚合操作。在可变形卷积(Deformable Convolution)的上下文中,可变形聚合通常指的是根据输入特征图的局部形状变化来动态地调整卷积核的采样位置。这样可以使卷积核具有更大的灵活性,更好地适应目标物体的形状变化。因此,
atomicAdd(output + anchor_index * num_embeds + channel_index,bilinear_sampling(mc_ms_feat, h, w, num_embeds, h_im, w_im, value_offset) * weight);
-
deformable_aggregation_grad_kernel():
- 这个函数或Kernel很可能是
deformable_aggregation()的梯度计算版本。在深度学习训练中,经常需要计算损失函数对于模型参数的梯度,以便通过反向传播来更新模型的权重。deformable_aggregation_grad()的作用就是计算deformable_aggregation()操作中涉及到的参数(如变形参数)的梯度。这些梯度随后会用于更新模型的权重,从而优化模型的性能。
- 这个函数或Kernel很可能是
const float weight = weights[weights_ptr];float *grad_weights_ptr = grad_weights + weights_ptr;float *grad_location_ptr = grad_sampling_location + loc_offset;bilinear_sampling_grad(mc_ms_feat, weight, h, w, num_embeds, h_im, w_im,value_offset,grad,grad_mc_ms_feat, grad_location_ptr, grad_weights_ptr);总结来说,deformable_aggregation_kernel()和deformable_aggregation__kernel_grad()的区别在于:前者是可变形聚合操作本身,用于根据输入和变形参数生成输出特征图;而后者是前者操作对应的梯度计算,用于深度学习训练中的参数更新。这两个函数或Kernel通常一起使用,前者用于前向传播计算输出,后者用于反向传播计算梯度。
3.4 deformable_aggregationl()
是deformable_aggregation_kernel 核函数的一部分。deformable_aggregationl() 在调用核函数时会采用如下代码:
{const int num_kernels = batch_size * num_pts * num_embeds * num_anchors * num_cams * num_scale;deformable_aggregation_kernel<<<(int)ceil(((double)num_kernels/128)), 128>>>(num_kernels, output,mc_ms_feat, spatial_shape, scale_start_index, sample_location, weights,batch_size, num_cams, num_feat, num_embeds, num_scale, num_anchors, num_pts, num_groups);
}这段代码看起来是用于GPU编程的,特别是在使用CUDA框架时。CUDA允许开发者编写并行计算的程序,通常用于图形处理和科学计算。
我会逐步解释这段代码:
- 常量定义:
const int num_kernels = batch_size * num_pts * num_embeds * num_anchors * num_cams * num_scale;
这行代码定义了一个常量num_kernels,它是多个变量的乘积。这些变量可能是与某种计算或任务相关的参数,如批量大小、点数、嵌入数、锚点数、相机数和尺度数。
- CUDA Kernel调用:
deformable_aggregation_kernel<<<(int)ceil(((double)num_kernels/128)), 128>>>(num_kernels, output,mc_ms_feat, spatial_shape, scale_start_index, sample_location, weights,batch_size, num_cams, num_feat, num_embeds, num_scale, num_anchors, num_pts, num_groups
);
这是CUDA Kernel的调用。CUDA Kernel是GPU上执行的并行代码块。
-
<<< ... >>>是CUDA中的执行配置语法。它定义了Kernel的线程网格和线程块的大小。(int)ceil(((double)num_kernels/128)):这部分代码计算了线程网格的大小。它将num_kernels除以128,并向上取整。这意味着每个线程块将处理最多128个kernels。128:这定义了线程块中的线程数。即每个线程块有128个线程。
-
deformable_aggregation_kernel:这是CUDA Kernel的名字。它的具体实现没有在这段代码中给出,但可以推测它执行某种可变形聚合操作。 -
括号中的参数是传递给Kernel的数据和配置参数。它们可能包括:
num_kernels:前面计算得到的内核数量。output:可能是存储Kernel结果的数组或缓冲区。mc_ms_feat、spatial_shape、scale_start_index、sample_location、weights:这些都是传递给Kernel的其他数据或参数,可能用于计算或查找。batch_size、num_cams、num_feat、num_embeds、num_scale、num_anchors、num_pts、num_groups:这些是与任务相关的配置参数。
总的来说,这段代码是在GPU上设置一个并行计算任务,特别是调用一个名为deformable_aggregation_kernel的Kernel,并传递给它相关的数据和参数。这种并行计算在处理大量数据或进行复杂计算时非常有用,因为GPU可以同时处理多个任务,从而显著提高计算速度。
4. init.py
这个声明了deformable_aggregation_function的调用。
然后写了一个新函数def feature_maps_format(feature_maps, inverse=False):
它的作用是对输入的 feature_maps 进行格式转换。具体地说,它似乎是为了处理某种具有多相机(multi-camera)和多尺度(multi-scale)特性的特征图(feature maps)。
从代码的结构和命名来看,这个函数可能是用于处理某种特定类型的3D数据或视频流数据,这些数据可能来自多个摄像头或多个尺度的观测。通过将特征图进行拆分和重新格式化,该函数可能有助于后续的处理或分析任务。
需要注意的是,这段代码使用了PyTorch的张量操作(如 unflatten 和 split),因此它可能是深度学习或计算机视觉应用的一部分。
代码提取每个格式化结果中的 col_feats、spatial_shape 和 scale_start_index,并将它们分别沿指定维度连接(concatenate)起来。
最后,返回一个包含连接后的 col_feats、spatial_shape 和 scale_start_index 的列表。
5 . setup.py 编译
在官方的ops 安装方法是这样的
Compile the deformable_aggregation CUDA opcd projects/mmdet3d_plugin/ops
python3 setup.py develop
cd ../../../
setup.py 里面是比较简单的
if __name__ == "__main__":setup(name="deformable_aggregation_ext",ext_modules=[make_cuda_ext("deformable_aggregation_ext",module=".",sources=[f"src/deformable_aggregation.cpp",f"src/deformable_aggregation_cuda.cu",],),],cmdclass={"build_ext": BuildExtension},)
( 正文完)
这个主要对deformable_aggregation 算子的一个插件的实现。
这篇关于【Transformer-BEV编码(7)】Sparse4D源代码,在mmdet里面增加cuda的插件deformable_aggregation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






