bev专题

BEV学习---LSS-1:论文原理及代码串讲
目前在自动驾驶领域,比较火的一类研究方向是基于采集到的环视图像信息,去构建BEV视角下的特征完成自动驾驶感知的相关任务。所以如何准确的完成从相机视角向BEV视角下的转变就变得由为重要。目前感觉比较主流的方法可以大体分为两种: 1、显式估计图像的深度信息,完成BEV视角的构建,在某些文章中也被称为自下而上的构建方式; 2、利用transformer中的query查询机制,利用BEV Query

BEV 中 multi-frame fusion 多侦融合(一)
文章目录 参数设置align_dynamic_thing:为了将动态物体的点云数据从上一帧对齐到当前帧流程 旋转函数平移公式filter_points_in_ego:筛选出属于特定实例的点get_intermediate_frame_info: 函数用于获取中间帧的信息,包括点云数据、传感器校准信息、自车姿态、边界框及其对应的实例标识等intermediate_keyframe_align

【自动驾驶】浅学一下BEV目标检测记录
现在BEV与OCC占用网络非常火,在日常工作中,如果没有接触到,可能会忽略相应的知识储备。本人还未看大量文献,所以只能算浅学下记录,这里主要从互联网上学习到的,还是就是跟专业的同事请教之后,自己总结的。 1.BEV视角 BEV视觉其实是全局俯视图,更好的得到其他障碍物到自车的横纵向距离。在2D检测的时候,对于深度(其他障碍物离自车的纵向距离)估计不是很准。 2.BEV数据标签
Bev算法在J5平台的部署
文章目录 1. 介绍1. 1 Bev的优势1. 2 视角转换13 Bev 感知总体框架 2 IPM 方案2.1 性能指标2.2 Backbone2.3 视角转换2.3 坐标系转换2.4 grid sample采样原理2.5 IPM空间融合2.6 IPM-Neck2.7 多任务头2.7.1 分割头2.7.2 检测头

自动驾驶---Perception之IPM图和BEV图
1 前言 IPM(Inverse Perspective Mapping,逆透视变换)图的历史可以追溯到计算机视觉和图像处理领域的发展。逆透视变换是一种用于消除图像中透视效应的技术,使得原本由于透视产生的形变得以纠正,进而更准确地描述和理解图像中的场景。比如在行车中的车道线检测,泊车中的常见障碍物检测,自动驾驶感知最开始的方案基本都离不开IPM图。 早期,自动驾驶
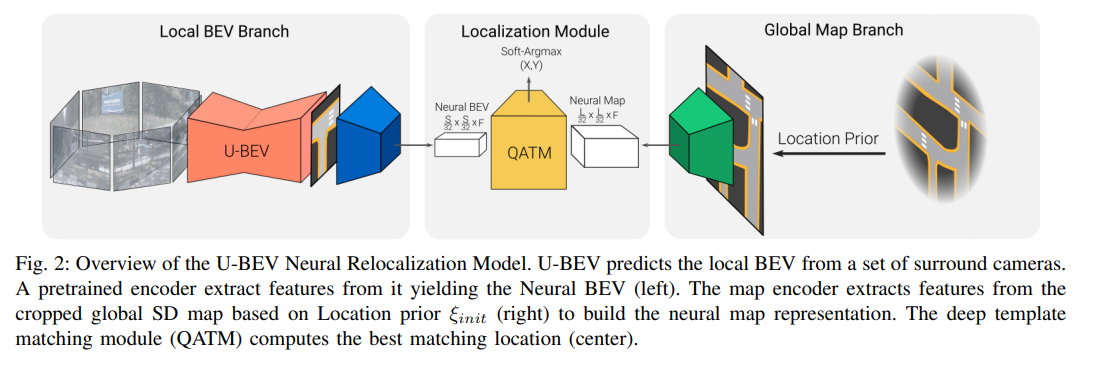
经典文献阅读之--U-BEV(基于高度感知的鸟瞰图分割和神经地图的重定位)
0. 简介 高效的重定位对于GPS信号不佳或基于传感器的定位失败的智能车辆至关重要。最近,Bird’s-Eye-View (BEV) 分割的进展使得能够准确地估计局部场景的外观,从而有利于车辆的重定位。然而,BEV方法的一个缺点是利用几何约束需要大量的计算。本文《U-BEV: Height-aware Bird’s-Eye-View Segmentation and Neural Map-bas
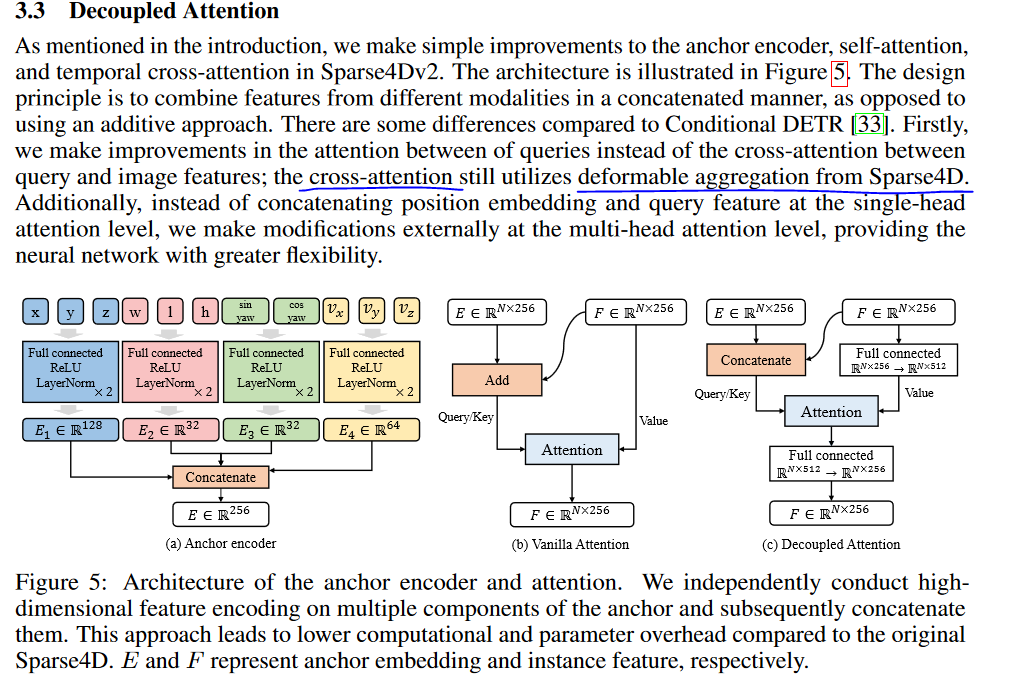
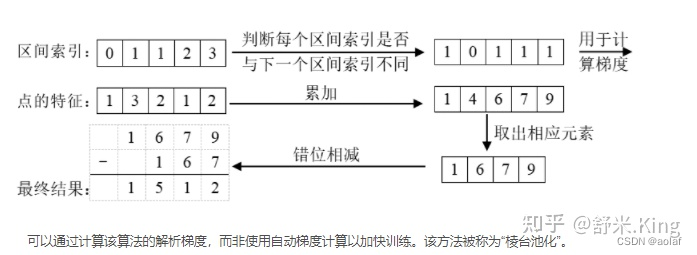
【Transformer-BEV编码(7)】Sparse4D源代码,在mmdet里面增加cuda的插件deformable_aggregation
文章目录 插件位置在论文V3中的“地位”看看具体的代码1. deformable_aggregation.py2. deformable_aggregation.cpp3. deformable_aggregation_cuda.cu3.1 双线性插值bilinear_sampling()3.2 bilinear_sampling_grad() 梯度计算3.3 `deformable_agg
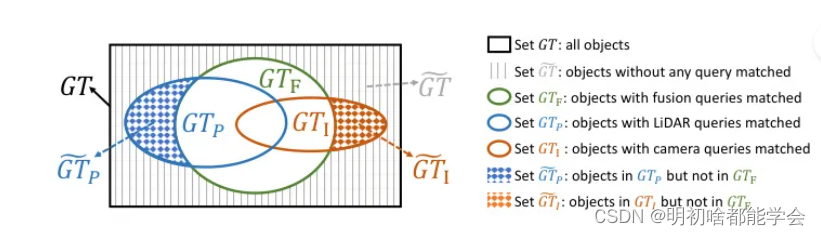
消除 BEV 空间中的跨模态冲突,实现 LiDAR 相机 3D 目标检测
Eliminating Cross-modal Conflicts in BEV Space for LiDAR-Camera 3D Object Detection 消除 BEV 空间中的跨模态冲突,实现 LiDAR 相机 3D 目标检测 摘要Introduction本文方法Single-Modal BEV Feature ExtractionSemantic-guided Flow-ba
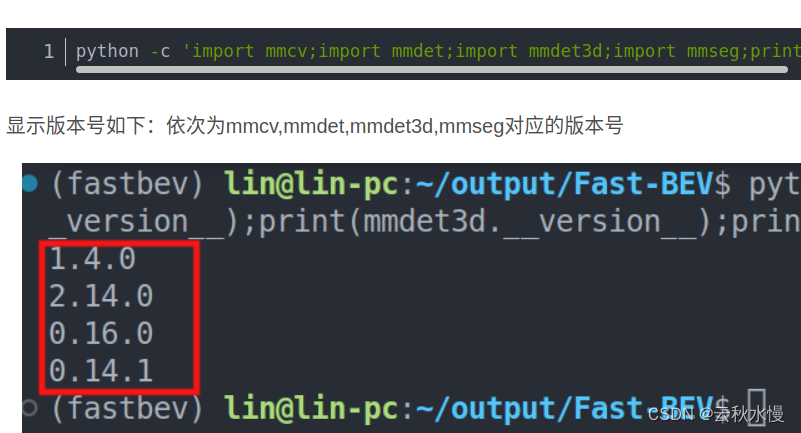
fast_bev 学习笔记
目录 一. 简述二. 输入输出三. github资源四. 复现推理过程4.1 cuda tensorrt 版 训练修改图像数 一. 简述 原文:Fast-BEV: A Fast and Strong Bird’s-Eye View Perception Baseline FAST BEV是一种高性能、快速推理和部署友好的解决方案,专为自动驾驶车载芯片设计。该框架主要包括以下五个部

【多模态融合】MetaBEV 解决传感器故障 3D检测、BEV分割任务
前言 本文介绍多模态融合中,如何解决传感器故障问题;基于激光雷达和相机,融合为BEV特征,实现3D检测和BEV分割,提高系统容错性和稳定性。 会讲解论文整体思路、模型框架、论文核心点、损失函数、实验与测试效果等。 论文地址:MetaBEV: Solving Sensor Failures for BEV Detection and Map Segmentation 代码地址:https:/

谈一谈BEV和Transformer在自动驾驶中的应用
谈一谈BEV和Transformer在自动驾驶中的应用 BEV和Transformer都这么火,这次就聊一聊。 结尾有资料连接 一 BEV有什么用 首先,鸟瞰图并不能带来新的功能,对规控也没有什么额外的好处。 从鸟瞰图这个名词就可以看出来,本来摄像头等感知到的物体都是3D空间里的的,投影到2D空间,只是信息的损失,也很简单(乘一个矩阵)。甚至是变换到ST图上所需的,中间过程的必备一步。
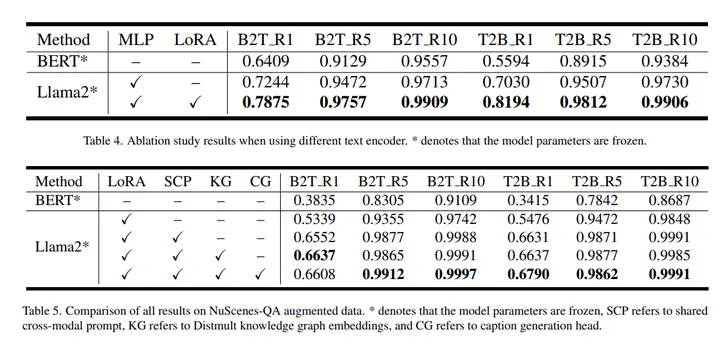
解决长尾问题,BEV-CLIP:自动驾驶中复杂场景的多模态BEV检索方法
解决长尾问题,BEV-CLIP:自动驾驶中复杂场景的多模态BEV检索方法 理想汽车的工作,原文,BEV-CLIP: Multi-modal BEV Retrieval Methodology for Complex Scene in Autonomous Driving 链接:https://arxiv.org/pdf/2401.01065.pdf 自动驾驶中对复杂场景数据的检索需求正在

自动驾驶感知新范式——BEV感知经典论文总结和对比(一)
自动驾驶感知新范式——BEV感知经典论文总结和对比(一) 博主之前的博客大多围绕自动驾驶视觉感知中的视觉深度估计(depth estimation)展开,包括单目针孔、单目鱼眼、环视针孔、环视鱼眼等,目标是只依赖于视觉环视摄像头,在车身周围产生伪激光雷达点云(Pseudo lidar),可以模拟激光雷达的测距功能,辅助3D目标检测等视觉定位任务,而且比激光雷达更加稠密。这是自动驾驶视觉感知的一个

DA-BEV: 3D检测新 SOTA!一种强大的深度信息挖掘方法(CVPR 2023)
作者 | 派派星 编辑 | 极市平台 点击下方卡片,关注“自动驾驶之心”公众号 ADAS巨卷干货,即可获取 点击进入→自动驾驶之心【3D目标检测】技术交流群 后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述! 导读 本文针对之前 DETR-based 的 3D 检测器中忽略了空间交叉注意力中的深度信息,并在检测物体时产生了严重的模糊问题进行了研究。为了解决这个问题,
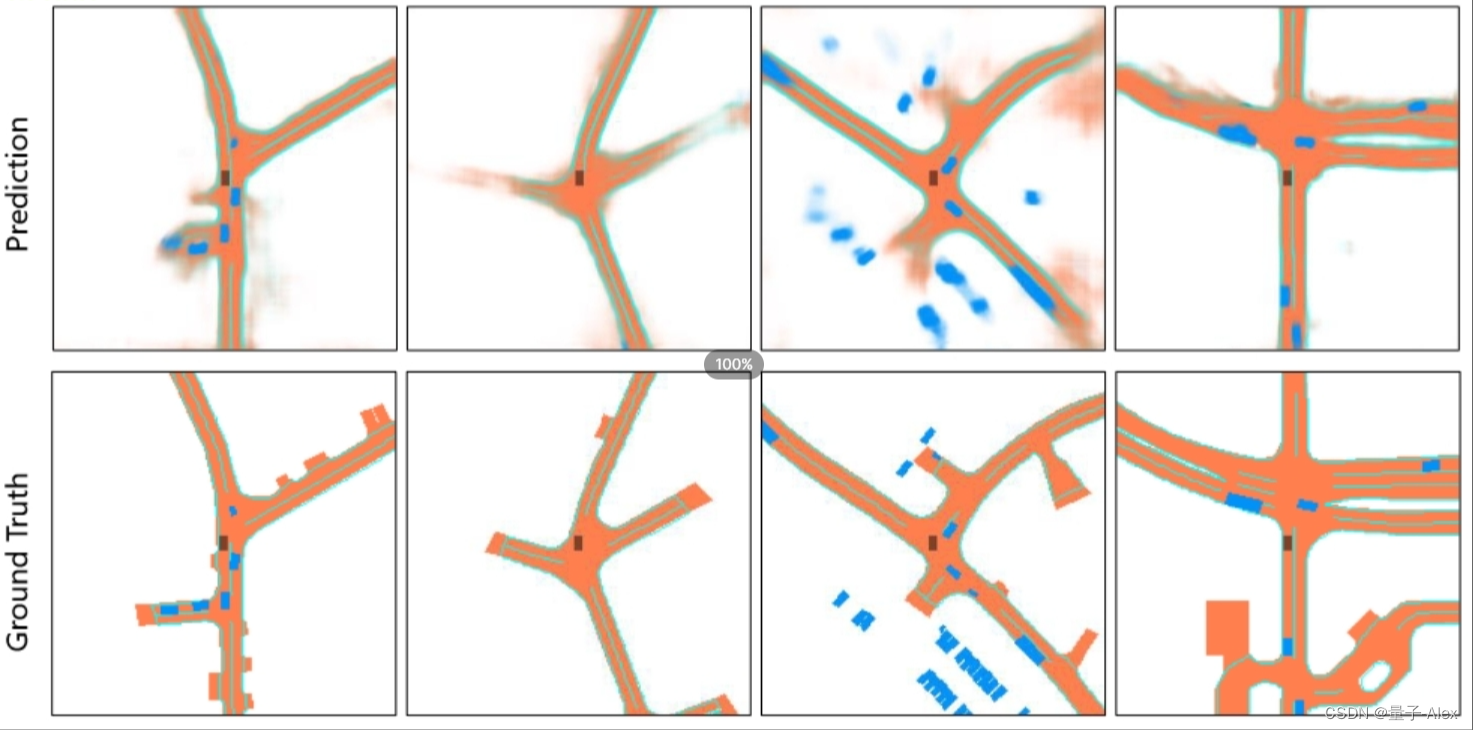
【CV论文精读】【BEV感知】BEVFormer:通过时空Transformer学习多摄像机图像的鸟瞰图表示
【CV论文精读】BEVFormer Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers BEVFormer:通过时空Transformer学习多摄像机图像的鸟瞰图表示 图1:我们提出了BEVFormer,这是一种自动驾驶的范式,它应用Transforme

SOTA!纯视觉多视图BEV下的地图生成和障碍物感知(CVPR2022)
作者 | 冯偲 编辑 | 汽车人 原文链接:https://zhuanlan.zhihu.com/p/511477453 点击下方卡片,关注“自动驾驶之心”公众号 ADAS巨卷干货,即可获取 点击进入→自动驾驶之心技术交流群 后台回复【领域综述】获取自动驾驶全栈近80篇综述论文! 论文名:Cross-view Transformers for real-time Map-view Sema
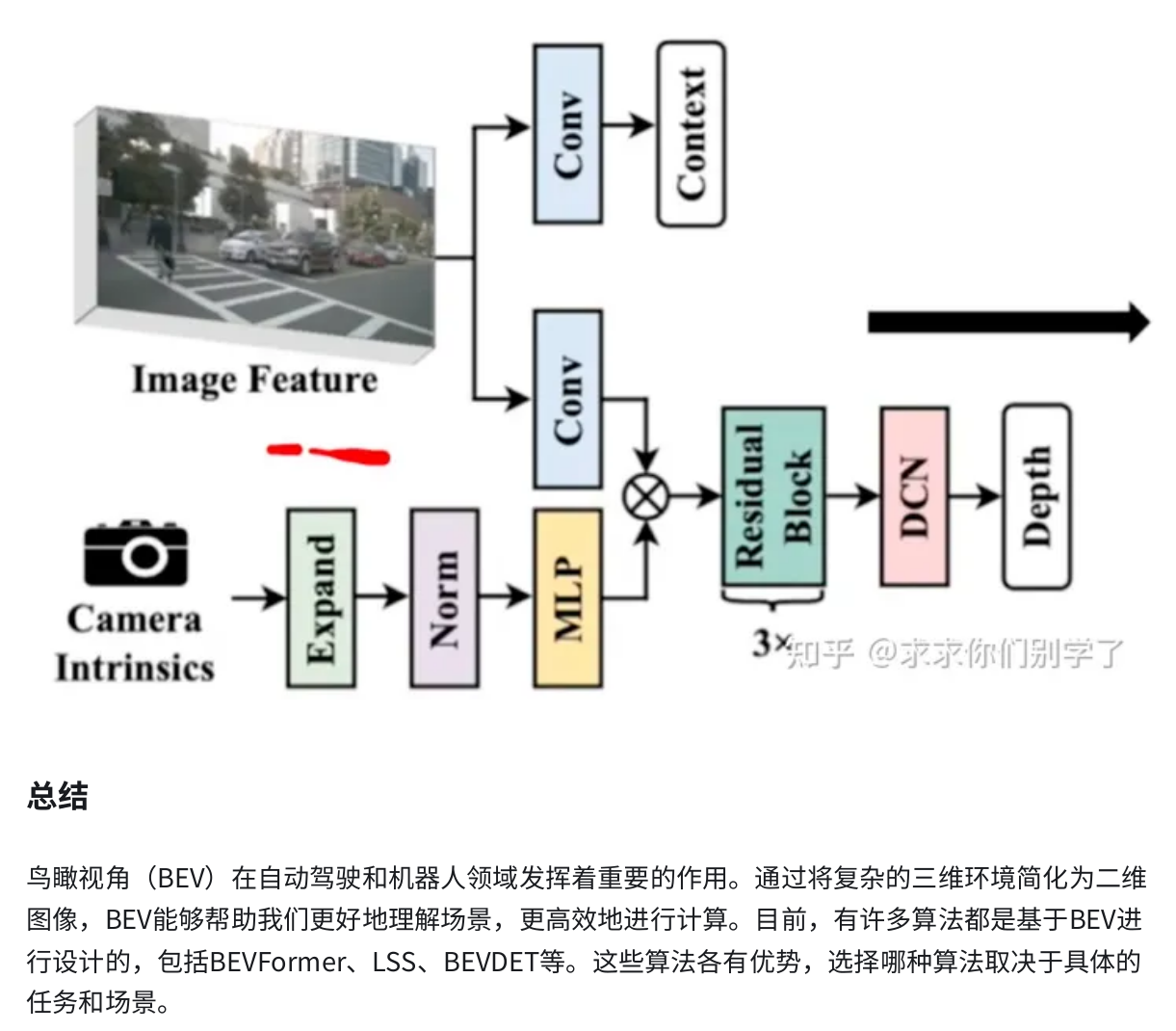
BEV(1)---lift splat shoot
1. 算法简介 1.1 2D坐标与3D坐标的关系 如图,已知世界坐标系上的某点P(Xc, Yc, Zc)经过相机的内参矩阵可以获得唯一的图像坐标p(x, y),但是反过来已知图像上某点p(x, y),无法获得唯一的世界坐标(只能知道P在Ocp这一射线上),只有当深度坐标Zc已知时,我们才可求得唯一的世界坐标P,因此2D坐标往3D坐标的转换多围绕Zc的获取展开。 1.2 LSS原理 LSS
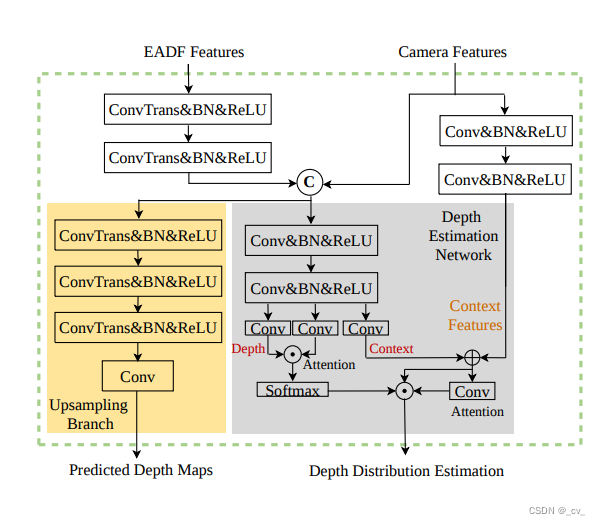
【nuScenes SOTA】EA-LSS:Edge-aware Lift-splat-shot Framework for 3D BEV Object Detection个人解析
文章目录 重点Fine-grained Depth ModuleEdge-aware Depth Fusion Module 重点 这篇文章最主要就是提出来两个模块,如上图所示,一个是FGD Module(Fine-grained Depth Module),另一个是EADF Module(Edge-aware Depth Fusion Module) Fine-g

Lift, Splat, Shoot图像BEV安装与模型代码详解
左侧6帧图像为不同的相机帧,右侧为BEV视角下的分割与路径规划结果 由于本人才疏学浅,解析中难免会出现不足之处,欢迎指正、讨论,有好的建议或意见都可以在评论区留言。谢谢大家! 专栏地址:https://blog.csdn.net/qq_41366026/category_11640689.html?spm=1001.2014.3001.5482 1 前言 计算机视觉算


万字长文谈自动驾驶bev感知(一)
文章目录 prologuepaper listcamera bev :1. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D2. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with

【三维目标检测】【自动驾驶】IA-BEV:基于结构先验和自增强学习的实例感知三维目标检测(AAAI 2024)
系列文章目录 论文:Instance-aware Multi-Camera 3D Object Detection with Structural Priors Mining and Self-Boosting Learning 地址:https://arxiv.org/pdf/2312.08004.pdf 来源:复旦大学 英特尔Shanghai Key Lab /美团 文章目录 系

中国智驾2023的关键词:融资、千元级和BEV算法
作者 |张祥威 编辑 |德新 电影《志愿军:雄兵出击》中,彭老总有一句台词让人热血沸腾:「你我生在这个时代,牺牲是我们一定要付出的代价,你不付,儿子付,孙子付。我们这辈人,一身血,两脚泥,还是我们付吧。」 作为汽车行业的观察者,发现「一身血、两脚泥」用来形容这一波智驾公司也非常准确。 想打入汽车产业链的它们,表面上写着代码就能指挥汽车的各种操作,但实际上,这是一群拎着脑袋跟在车企后面,

四. 基于环视Camera的BEV感知算法-BEVDepth
目录 前言0. 简述1. 算法动机&开创性思路2. 主体结构3. 损失函数4. 性能对比总结下载链接参考 前言 自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考 本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 BEVDepth 感知算法 课程大纲可以看下面的思维导图 0. 简述

四. 基于环视Camera的BEV感知算法-BEVDet
目录 前言0. 简述1. 算法动机&开创性思路2. 主体结构3. 损失函数4. 性能对比总结下载链接参考 前言 自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考 本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 BEVDet 感知算法 课程大纲可以看下面的思维导图 0. 简述 本次