本文主要是介绍经典文献阅读之--U-BEV(基于高度感知的鸟瞰图分割和神经地图的重定位),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 简介
高效的重定位对于GPS信号不佳或基于传感器的定位失败的智能车辆至关重要。最近,Bird’s-Eye-View (BEV) 分割的进展使得能够准确地估计局部场景的外观,从而有利于车辆的重定位。然而,BEV方法的一个缺点是利用几何约束需要大量的计算。本文《U-BEV: Height-aware Bird’s-Eye-View Segmentation and Neural Map-based Relocalization》提出了U-BEV,一种受U-Net启发的架构,通过在拉平BEV特征之前对多个高度层进行推理,扩展了当前的最先进水平。我们证明了这种扩展可以提高U-BEV的性能高达4.11%的IoU。此外,我们将编码的神经BEV与可微分的模板匹配器相结合,在神经SD地图数据集上执行重定位。所提出的模型可以完全端到端地进行训练,并在nuScenes数据集上优于具有相似计算复杂度的基于Transformer的BEV方法1.7到2.8%的mIoU,以及基于BEV的重定位超过26%的召回率。
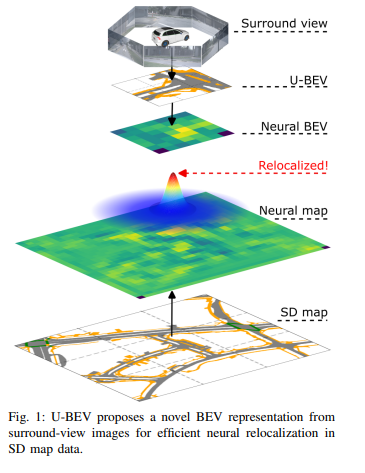
图1:U-BEV提出了一种新颖的BEV表示方法,通过环视图像实现在SD地图数据中高效的神经定位。
1. 主要贡献
在这项工作中,我们提出了一种新的方法来估计BEV(鸟瞰图),利用高度感知特征嵌入,使网络能够在深度维度上进行推理,而无需进行繁重的计算。基础架构受到了众所周知的U-Net结构的启发,并且由于整个模型中存在跳跃连接,可以保留细节。我们主张采用两步定位方法,自主代理首先在几米范围内全局估计其位置,然后依赖于局部方法获得应用所需的精度。因此,我们利用轻量级的标准定义(SD)地图数据,并旨在实现一次性重定位精度在10米以下。在这项工作中,我们将BEV表示与深度模板匹配器相结合,后者是端到端可训练的,用于实时重定位。定位架构可以通过将BEV方法和相应的地图数据编码为神经表示来处理任意BEV方法。这项工作将U-BEV与重定位模块相结合,优于nuScenes数据集上其他BEV方法和当代基于BEV的定位,其在10米处的召回准确度提高了26.4%。总之,本文提出了以下贡献:
- 一种新的轻量级U-BEV架构,其在几何上受到限制,并利用地面点的高度而不是它们相对于摄像机的深度。
- 一种端到端可训练的实时全局定位算法,用于神经BEV和神经编码的SD地图之间的定位。
- 在nuScenes数据集上改进了BEV(IoU提高了1.7到2.8)和定位性能(在10米处的召回准确度提高了26.4%)。
2. 方法
提议的完整算法在SD地图中定位一组环视图像。它从环视图像生成局部BEV表示,并从SD地图瓦片中生成神经地图编码,给定来自车载传感器(例如嘈杂的GPS信号和指南针)的粗略3D位置先验 ξ i n i t = ( x i n i t , y i n i t , ϕ i n i t ) ξ_{init} = (x_{init}, y_{init}, ϕ_{init}) ξinit=(xinit,yinit,ϕinit)。然后,深度模板匹配器将局部神经BEV滑动到全局神经地图上,生成相似度图。定位最终通过返回相似度图的Soft-Argmax完成。我们的方法概述如图2所示。
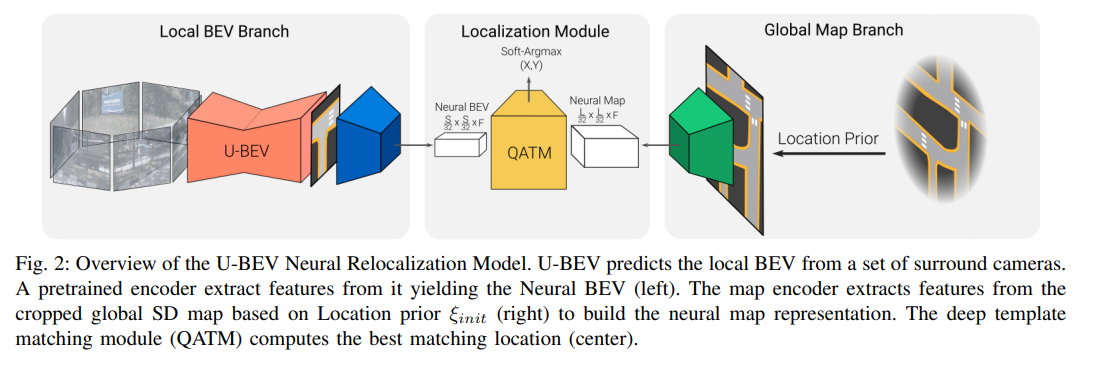
图2:U-BEV神经重定位模型概述。U-BEV从一组周围摄像头中预测局部BEV。预训练的编码器从中提取特征,生成神经BEV(左侧)。地图编码器根据位置先验 ξ i n i t ξ_{init} ξinit(右侧)从裁剪的全局SD地图中提取特征,构建神经地图表示。深度模板匹配模块(QATM)计算最佳匹配位置(中间)。
3. 鸟瞰图重建
我们提出了一种新颖的轻量级且准确的BEV架构,用于从一组环视图像中重建车辆周围的环境。我们的模型称为U-BEV,受到计算机视觉分割任务中广泛使用的U-Net [36]架构的启发。概述如图4所示。
给定一组6张图像及其内在和外在校准,我们预测一个BEV B ∈ R S × S × N B ∈ \mathbb{R}^{S×S×N} B∈RS×S×N,其中 S S S是BEV的像素大小, N N N是地图中可用标签的数量。我们使用后轮轴的中心作为原点,遵循nuScenes数据集中的惯例[37]。
…详情请参照古月居
这篇关于经典文献阅读之--U-BEV(基于高度感知的鸟瞰图分割和神经地图的重定位)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





