本文主要是介绍SOTA!纯视觉多视图BEV下的地图生成和障碍物感知(CVPR2022),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者 | 冯偲 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/511477453
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
论文名:Cross-view Transformers for real-time Map-view Semantic Segmentation
1引言
本文 提出cross-view transformers的方法,针对纯视觉多视角下的地图生成和障碍物感知任务,设计一个有效的注意力机制网络。直白点就是用于BEV地图生成和障碍物感知的注意力机制网络。目前代码已经开源,从论文公布的结果看,无论在精度还是速度上都达到SOTA。优秀的工作。
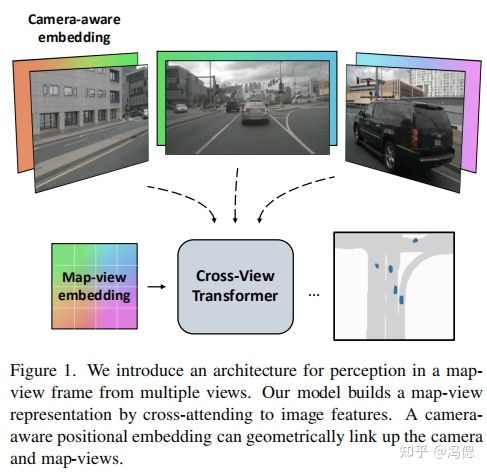
2显式表达和隐式表达
无论是否使用注意力机制进行BEV的感知,都存在一个问题--在对特征空间位置进行编码,简单点来说就是需要深度的信息用于辅助多视角相机的特征编码。之前的工作诸如lift,fiery等都是显式的使用深度估计编码图像特征,但是由于单目深度估计很难形成有效的深度,所以在作者提出了利用attention机制进行隐式编码。关于这一点,我有不同的看法,无论是lift还fiery都不是使用真的深度进行特征编码,而是使用深度估计的概率值进行特征编码。
3网络结构
设计了一个简单有效的encoder-decoder网络架构用于BEV视图下的障碍物和行车环境的分割。
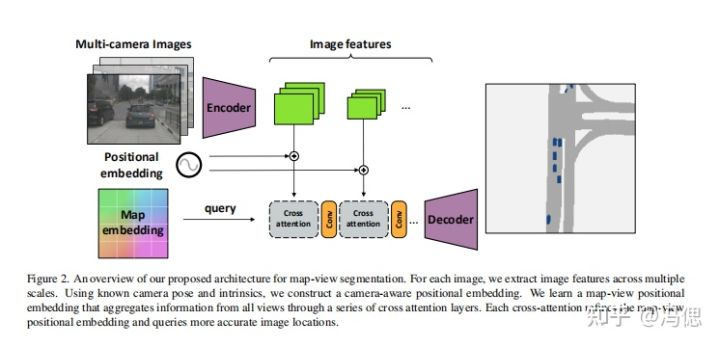
1)用于多视角图像编码的encoder
这部分网络采用的还是cnn的编码方式,使用的骨干网络是EfficientNet-B4。一个输入图像产生产生多个尺度(2个尺度)的特征表达。在这之后是根据ViT的算法思想进行多分辨率的patch embedding。
2)交叉视角的 cross-attention机制
这部分主要是实现了感知相机的位置编码,利用相机独立的校准矩阵(内外参等)对特征进行位置编码。这部分也是论文的核心,利用注意力机制进行处理。在lift、fiery是用深度估计概率编码(卷积的方法)。下面公式是位置编码时候世界相对坐标和图像坐标的处理。
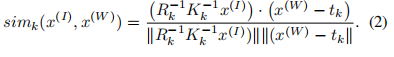
3)设计一个轻量级的解码网络decoder
decoder网络上采样调整bev视图的分辨率,并形成最终的分割结果
4实验环境
数据集:nuscense 使用4 GPU,每个GPU的batchsize=4.一共训练了30 epochs.这里要主要整体的batchsize=4*4(pytorchlighting)。训练时间8 hours。
5消融实验和结果
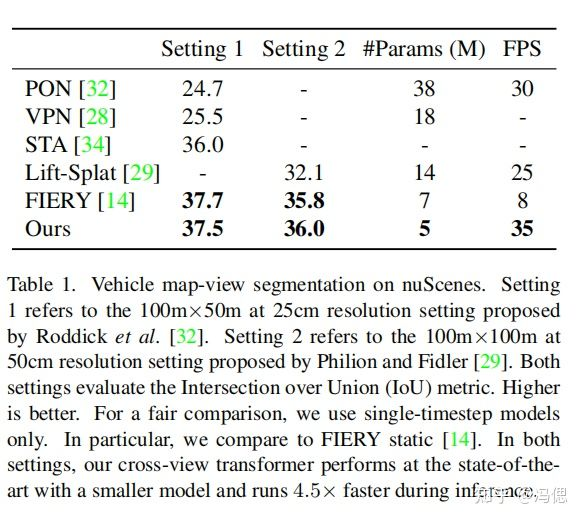
消融实验结果如下,不用多说了,肯定都加上效果才最好。

结果对比可以看出效果的确不错,和fiery不相上下。虽然在FPS的对比大幅超过其他算法,但是这样比较不合适,毕竟fiery算法还有利用3帧进行未来轨迹预测的GRU网络,而本文并没有。
可视化结果如下,没有车道线

6总结
整体上看在引入注意力机制后,BEV的感知结果好于当下所有算法。工作值得肯定,后面结合代码深入研究一下。另外,劝劝各位cver,ViT系列真香气,真的可以一战,而且用武之地会越来越多。
往期回顾
史上最全 | BEV感知算法综述(基于图像/Lidar/多模态数据的3D检测与分割任务)
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!

这篇关于SOTA!纯视觉多视图BEV下的地图生成和障碍物感知(CVPR2022)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






