本文主要是介绍解决长尾问题,BEV-CLIP:自动驾驶中复杂场景的多模态BEV检索方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
解决长尾问题,BEV-CLIP:自动驾驶中复杂场景的多模态BEV检索方法

理想汽车的工作,原文,BEV-CLIP: Multi-modal BEV Retrieval Methodology for Complex Scene in Autonomous Driving
链接:https://arxiv.org/pdf/2401.01065.pdf
自动驾驶中对复杂场景数据的检索需求正在增加,尤其是随着乘用车已经具备了在城市环境中导航的能力,必须解决长尾场景问题。同时,在已有的二维图像检索方法下,场景检索可能会出现一些问题,如缺乏全局特征表示和亚层次文本检索能力。
为了解决这些问题,作者提出了BEV-CLIP,这是第一种多模态BEV检索方法,它利用描述性文本作为输入来检索相应的场景。该方法利用大型语言模型(LLM)的语义特征提取能力,促进零样本检索大量文本描述,并结合知识图中的半结构化信息,提高语言嵌入的语义丰富性和多样性。实验结果表明在NuScenes数据集上,文本到BEV特征检索的准确率为87.66%。论文中的示例支持本文的检索方法也被证明在识别某些长尾场景方面是有效的!
本文旨在研究在自动驾驶场景中开发视觉文本检索系统的两个基本问题。
(1) 如何克服二维图像特征固有的局限性,特别是它们在自动驾驶场景中有效表示全局特征的能力较差?
(2) 哪些方法可能会增强自动驾驶领域中文本表示目前不令人满意的效果?为了解决这两个问题,提出以下建议。
特征提取:建议使用BEV框架,因为它为自动驾驶场景描述提供了统一的表示。通过组合多视角相机数据,BEV框架从自上而下的角度将2D感知投影到详细的3D描述中。该方法克服了在基于2D的后融合方法中经常出现的与特征截断相关的限制,并为决策规划和控制等下游任务实现了统一的感知格式。此外,在检索任务的上下文中,BEV特征的结合显著增强了模型将文本数据与3D空间内的位置属性相关联的能力!
作为一个值得注意的解决方案,BEVFormer,一种基于transformer的BEV编码器,仅从相机输入生成全局特征,并用作各种下游任务的端到端模型。因此,对BEV特征进行场景检索是解决提取全局表示问题的综合解决方案,作为一种众所周知的方法,将BEVFormer用于BEV特征提取对我们来说既有利又合理。
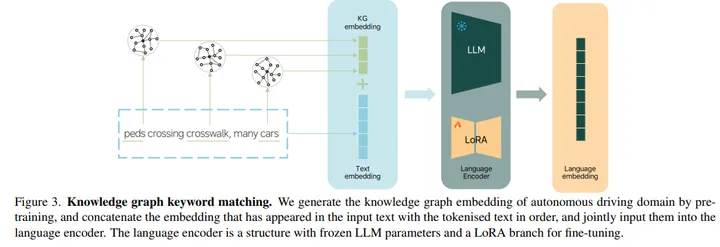
语言表达。建议将复杂的语义数据作为额外的输入,以补偿仅在图像数据中不明显的抽象特征。现有的多模态大型语言模型(LLM)在表达其他模态的特征方面表现出了显著的能力。CLIP为使用对比学习的多模式检索提供了基线,使模型能够通过利用语言模型的解码能力来生成零样本推断。受此启发,我们构建了一个改进的LLM,并采用微调策略来提供更丰富的语义信息,作为BEV特征的补充。此外,还将引入知识图特征,以提高知识在自动驾驶领域的显著性。LLM和知识图的融合旨在实现我们方法中极好的跨模态理解。
BEV-CLIP方法介绍
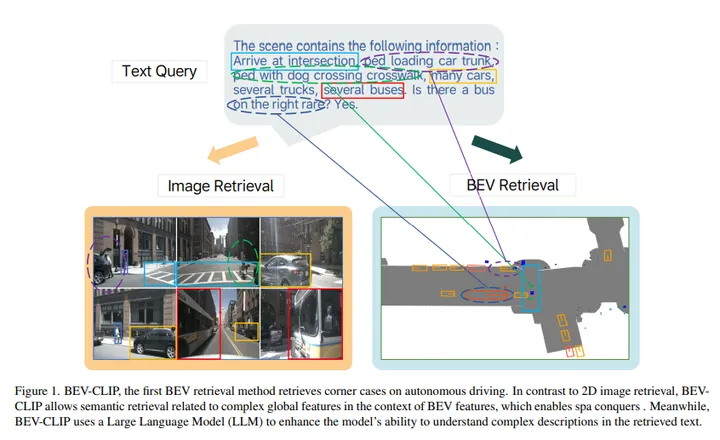
BEV-CLIP如下图所示,这是第一种BEV检索方法检索自动驾驶的corner case。与2D图像检索相比,BEVCLIP允许在BEV特征的背景下进行与复杂全局特征相关的语义检索,从而实现spa conquers。同时,BEV-CLIP使用大型语言模型(LLM)来增强模型理解检索文本中复杂描述的能力。
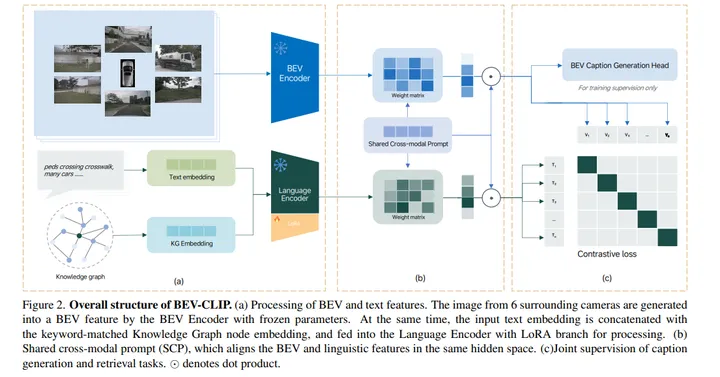
BEV-CLIP的总体结构。(a) BEV和文本特征的处理。BEV编码器使用冻结的参数将来自周围6个相机的图像生成为BEV特征。同时,将输入文本嵌入与关键字匹配的知识图节点嵌入级联,并输入到具有LoRA分支的语言编码器中进行处理。(b) 共享跨模态提示(SCP),将BEV和语言特征对齐在同一隐藏空间中。(c) caption生成和检索任务的联合监督。
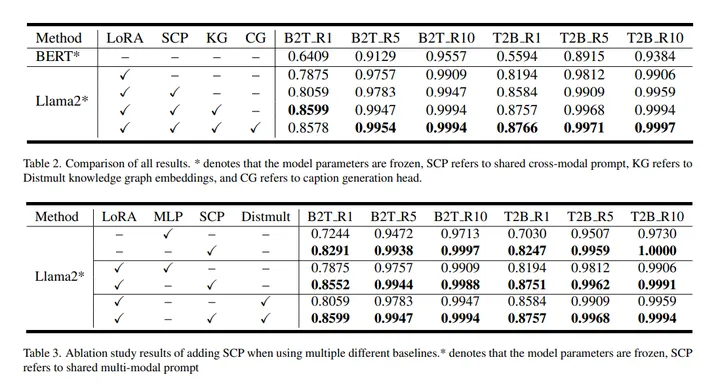
实验效果
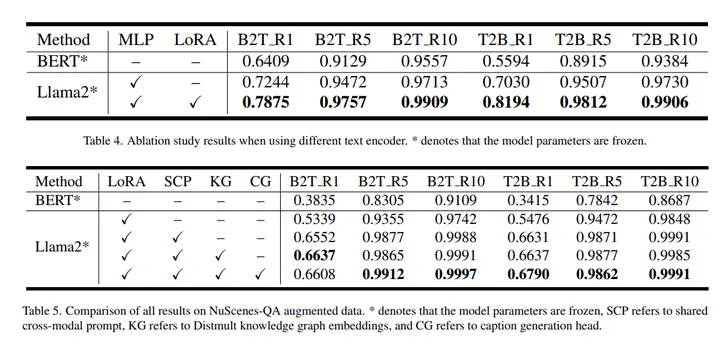
作者选择NuScenes数据集,这是唯一可用的具有开放文本描述的多视图数据集,并通过组合策略对其进行扩展。基于这样的数据集设置,作者希望揭示理解复杂、详细和独特的语义表示的能力。同时努力消除数据分布中的重复性和通用性,以验证零样本检索的能力。
最强自动驾驶学习资料和落地经验获取:链接
这篇关于解决长尾问题,BEV-CLIP:自动驾驶中复杂场景的多模态BEV检索方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




