cuda专题

PyInstaller问题解决 onnxruntime-gpu 使用GPU和CUDA加速模型推理
前言 在模型推理时,需要使用GPU加速,相关的CUDA和CUDNN安装好后,通过onnxruntime-gpu实现。 直接运行python程序是正常使用GPU的,如果使用PyInstaller将.py文件打包为.exe,发现只能使用CPU推理了。 本文分析这个问题和提供解决方案,供大家参考。 问题分析——找不到ONNX Runtime GPU 动态库 首先直接运行python程序


CUDA:用并行计算的方法对图像进行直方图均衡处理
(一)目的 将所学算法运用于图像处理中。 (二)内容 用并行计算的方法对图像进行直方图均衡处理。 要求: 利用直方图均衡算法处理lena_salt图像 版本1:CPU实现 版本2:GPU实现 实验步骤一 软件设计分析: 数据类型: 根据实验要求,本实验的数据类型为一个256*256*8的整型矩阵,其中元素的值为256*256个0-255的灰度值。 存储方式: 图像在内存中

ffmpeg安装测试(支持cuda支持SRT)
文章目录 背景安装ffmpeg直接下载可执行文件选择版本选择对应系统版本下载测试Linux下安装 查看支持协议以及编码格式 常见错误缺少 libmvec.so.1LD_LIBRARY_PATH 错误 GPU加速测试SRT服务器搭建下载srs5.0源码解压安装配置启动 SRT推流测试SRT播放测试 背景 在音视频开发测试中,FFmpeg是一个不可或缺的工具,它以其强大的音视频处理

【FFMPEG】Install FFmpeg CUDA gltransition in Ubuntu
因为比较复杂,记录一下自己安装过程,方便后续查找,所有都是在docker环境安装cuda11.7的 **ffmpeg 4.2.2 nv-codec-headers-9.1.23.3 ** 手动下载安装吧 https://github.com/aperim/docker-nvidia-cuda-ffmpeg/blob/v0.1.10/ffmpeg/Dockerfile最好手动一个一个安装,错误跳

windows 机器学习 tensorflow-gpu +keras gpu环境的 相关驱动安装-CUDA,cuDNN。
本人真实实现的情况是: windows 10 tensorboard 1.8.0 tensorflow-gpu 1.8.0 pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ tensorflow-gpu==1.8.0 Keras 2.2.4 pip
CUDA与TensorRT学习三:TensorRT基础入门
文章目录 一、TensorRT概述二、TensorRT应用场景三、TensorRT模块四、导出并分析ONNX五、剖析ONNX架构并理解Protobuf六、ONNX注册算子的方法七、快速分析开源代码并导出ONNX八、使用trtexec九、trtexec log分析 一、TensorRT概述 二、TensorRT应用场景 三、TensorRT模块 四、导出并分析ONNX 五、

【并行计算】CUDA基础
cuda程序的后缀:.cu 编译:nvcc hello_world.cu 执行:./hello_world.cu 使用语言还是C++。 1. 核函数 __global__ void add(int *a, int *b, int *c) {*c = *a + *b;} 核函数只能访问GPU的内存。也就是显存。CPU的存储它是碰不到的。 并且核函数不能使用变长参数、静态变量、函数指
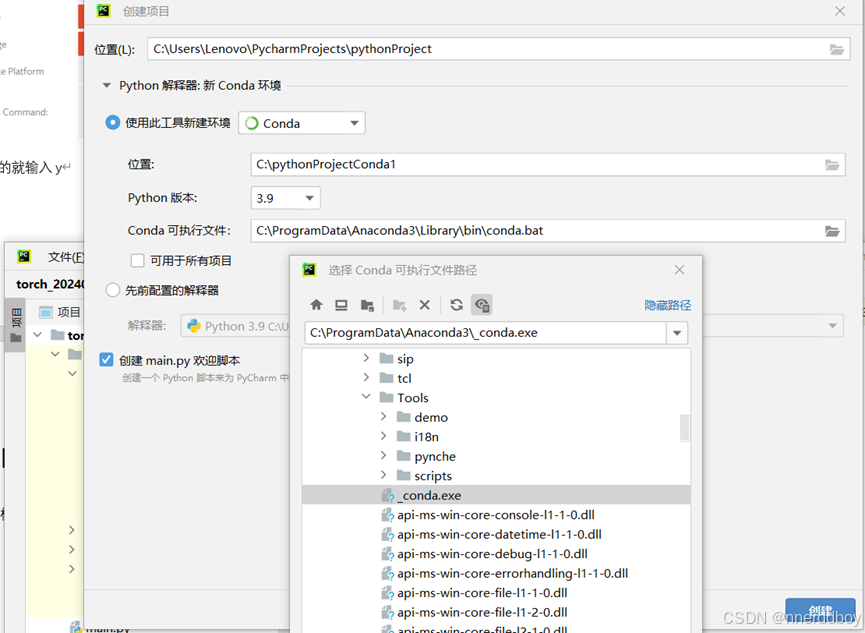
GPU环境配置:1.CUDA、Anaconda、Pytorch
一、查看显卡适配CUDA型号 查看自己电脑的显卡版本: 在 Windows 设置中查看显卡型号:使用 Windows + I 快捷键打开「设置」,依次点击「系统」-「屏幕」和「高级显示器设置」,在「显示器 1」旁边就可以看到显卡名称。 右键点菜单图标,选择系统,查看自己的Windows版本 右键菜单,设备管理器,点开“显示

Pytorch安装 CUDA Driver、CUDA Runtime、CUDA Toolkit、nvcc、cuDNN解释与辨析
Pytorch的CPU版本与GPU版本 Pytorch的CPU版本 仅在 CPU 上运行,适用于没有显卡或仅使用 CPU 的机器。安装方式相对简单,无需额外配置 CUDA 或 GPU 驱动程序。使用方式与 GPU 版相同,唯一不同的是计算将自动在 CPU 上进行。 Pytorch的GPU版本 在 NVIDIA GPU 上运行,充分利用 CUDA(Compute Unified Device

CUDA-MODE课程笔记 第9课: 归约(也对应PMPP的第10章)
我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode CUDA-MODE课程笔记 第9课: 归约(也对应PMPP的第10章) 课程笔记 本节课的题目。 这节课的内容主要是 Chapter 10 of PMPP book ,Slides里面还给出了本节课的

ubuntu下CUDA安装绕坑
OS: ubuntu16.04 , 显卡 Nvidia 1080 装CUDA原因: 1.在配置elasticFusion等需要GPU加速的开源SLAM工程时要装CUDA (配置时请将elasticfusion的bash中的CUDA-7-5删掉) 2.深度学习装CUDA 安装流程: 先安装机子显卡对应的显卡驱动: sudo add-apt-repository ppa:graphic

vs cuda新建文件模板
新建cuda文件模板 现有vs安装目录下的cuda文件模板将CudaFile相关三个文件复制修改名称修改.vsdir内容(为新建模板文件名和描述信息) 重启vs,项目中添加新建项已包含模板代码 现有vs安装目录下的cuda文件模板 将CudaFile相关三个文件复制修改名称 在cu文件中添加头文件、主函数等常用代码 修改.vsdir内容(为新建模板文件名和描述信息)

cuda 入门 threadIdx
cuda threadIdx 访问唯一数组下标 三维 grid block访问下标 三维 grid block dim3 block(2, 2, 2);dim3 grid(2, 2, 2); 访问下标 __global__ void mem_trans(int* input){int threadId_3D = threadIdx.x + threadIdx.y

【202408最新】Anaconda+VSCode+CUDA+Pytorch安装配置保姆级教程
最近新换了电脑,又开始从头配置代码环境,到处看教程真的一个头两个大,干脆自己整理了一下,方便以后一站式重装。也提供给大家参考。 1.Anaconda下载安装 Anaconda和Python是替代品(也不是),下载conda之后会有python。但是Anaconda还自带了 Python 解释器以及许多常用的科学计算、数据分析库(如 NumPy、Pandas、SciPy 等),并且还提供了 Co

Python和C++(CUDA)及Arduino雅可比矩阵导图
🎯要点 对比三种方式计算读取二维和三维三角形四边形和六面体网格运动学奇异点处理医学图像成像组学分析特征敏感度增强机械臂路径规划和手臂空间操作变换苹果手机物理稳定性中间轴定理 Python雅可比矩阵 多变量向量值函数的雅可比矩阵推广了多变量标量值函数的梯度,而这又推广了单变量标量值函数的导数。换句话说,多变量标量值函数的雅可比矩阵是其梯度(的转置),而单变量标量值函数的梯度是其导数。 在

AI自动采集教学行为——机器学习部分和深度学习部分(含torch和cuda)
文章目录 数据清洗机器学习深度学习代码没问题之后的文件下载 bert环境配置太麻烦 ,改用飞浆的bert 数据清洗 要遍历当前文件夹下从1.x1sx到8.x1sx的所有文件, 提取“句子”列,‘标注’列和‘上下文情境’这三列 按顺序把excel中的这三列拼接在一起。 合并输出成一个xlsx文件。 import osimport pandas as pd# 获取当前脚本所在


Ubuntu16.04安装Nvidia驱动cuda,cudnn和tensorflow-gpu
本文个人博客地址: 点击查看之前有在阿里云GPU服务器上弄过: 点击查看, 这里从装Nvidia开始 一、 安装Nvidia驱动 1.1 查找需要安装的Nvidia版本 1.1.1 官网 官网上查找: https://www.nvidia.com/Download/index.aspx?lang=en-us 这里是 GeForce GTX 1080 TI如下图,推荐 410 版本的

封装CUDA为动态链接库+Qt调用
由于工作需要在Qt中调用CUDA做并行计算,加速算法实现时间,发现有两种方法可以在Qt中调用CUDA代码。 第一种是在项目中创建CUDA的cu文件,编写CUDA的核函数给其他的QT代码调用,Qt的代码正常编译,CUDA代码使用nvcc编译器编译。这种方法只要配置一下pro文件就可以了,适合CUDA代码比较少的项目,只需要几个核函数调用CUDA进行一下加速运算,具体

bitsandbytes使用错误:CUDA Setup failed despite GPU being available
参考:https://huggingface.co/docs/bitsandbytes/main/en/installation 报错信息 ======================
并行计算的艺术:PyTorch中torch.cuda.nccl的多GPU通信精粹
并行计算的艺术:PyTorch中torch.cuda.nccl的多GPU通信精粹 在深度学习领域,模型的规模和复杂性不断增长,单GPU的计算能力已难以满足需求。多GPU并行计算成为提升训练效率的关键。PyTorch作为灵活且强大的深度学习框架,通过torch.cuda.nccl模块提供了对NCCL(NVIDIA Collective Communications Library)的支持,为多GP
精准掌控GPU:深度学习中PyTorch的torch.cuda.device应用指南
精准掌控GPU:深度学习中PyTorch的torch.cuda.device应用指南 在深度学习的世界里,GPU加速已成为提升模型训练和推理速度的关键。PyTorch,作为当下最流行的深度学习框架之一,提供了torch.cuda.device这一强大的工具,允许开发者精确指定和控制GPU设备。本文将深入探讨如何在PyTorch中使用torch.cuda.device来指定GPU设备,优化你的深度
性能优化利器:PyTorch中torch.cuda.Event的高效计时应用
性能优化利器:PyTorch中torch.cuda.Event的高效计时应用 在深度学习模型的开发和训练过程中,性能调优是一个不可或缺的环节。准确测量不同操作的执行时间对于识别性能瓶颈和优化算法至关重要。PyTorch提供了torch.cuda.Event,这是一个用于在CUDA设备上进行精确计时的工具。本文将详细介绍如何在PyTorch中使用torch.cuda.Event来监控和测量GPU上
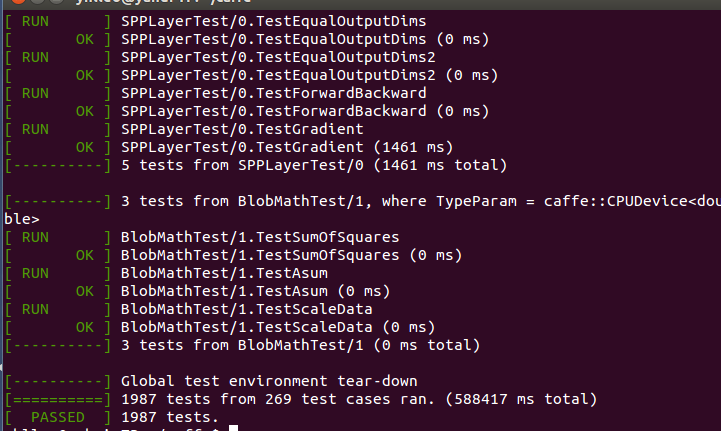
cuda caffe cudnn
本系列文章由 @yhl_leo 出品,转载请注明出处。 文章链接: http://blog.csdn.net/yhl_leo/article/details/50961542 花了一天时间,在电脑上安装配置了Caffe深度学习框架,网上的很多教程和指导都已经过期,中间辗转耗费了点时间,这里把个人认为最简单的方法整理如下。 1 版本 笔记本:ThinkPad W541