本文主要是介绍临床基础两手抓!这个12+神经网络模型太贪了,免疫治疗预测、通路重要性、基因重要性、通路交互作用性全部拿下!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
生信碱移
IRnet介绍
用于预测病人免疫治疗反应类型的生物过程嵌入神经网络,提供通路、通路交互、基因重要性的多重可解释性评估。
临床实践中常常遇到许多复杂的问题,常见的两种是:
-
二分类或多分类:预测患者对治疗有无耐受(二分类)、判断患者的疾病分级(多分类);
-
连续数值的预测:预测癌症病人的风险、预测患者的白细胞数值水平;
尽管传统的机器学习提供了高效的建模预测与初步的特征重要评分,但是仍然缺乏一定的可解释性。也就是说,我们很难直接将疾病与基础的生物学过程连接。而这里不得不提到近几年在生物学领域越来越火的神经网络模型,由于其架构的灵活性使得可解释性有了很大的提升空间,一些嵌入了生物学基本过程的模型框架也被陆续提出。小编今天借花献佛,给各位佬哥佬姐分享一个神经网络架构IRnet,其利用先验的通路注释信息构建了一款图神经网络,于上个月初发表于Journal of Advanced Research[IF: 11.4] 期刊。

▲ DOI:10.1016/j.jare.2024.07.036
简要介绍一下,IRnet是一款可解释深度学习框架,用于预测患者对免疫疗法(尤其是免疫检查点抑制剂)的反应。IRnet的特点是不预先选择任何生物标记物,只需要输入患者的整个基因表达矩阵。具体点讲,该网络架构将通过"基因-通路"映射自主学习各种生物标记物的重要性,除了对于患者的预测结果以外,还可以获得三个层次的解释:通路重要性、通路相互作用重要性和基因重要性。看到这里,小编心里里立马想到: 这不就是某些老铁最喜欢的,临床意义基础意义全都要吗?
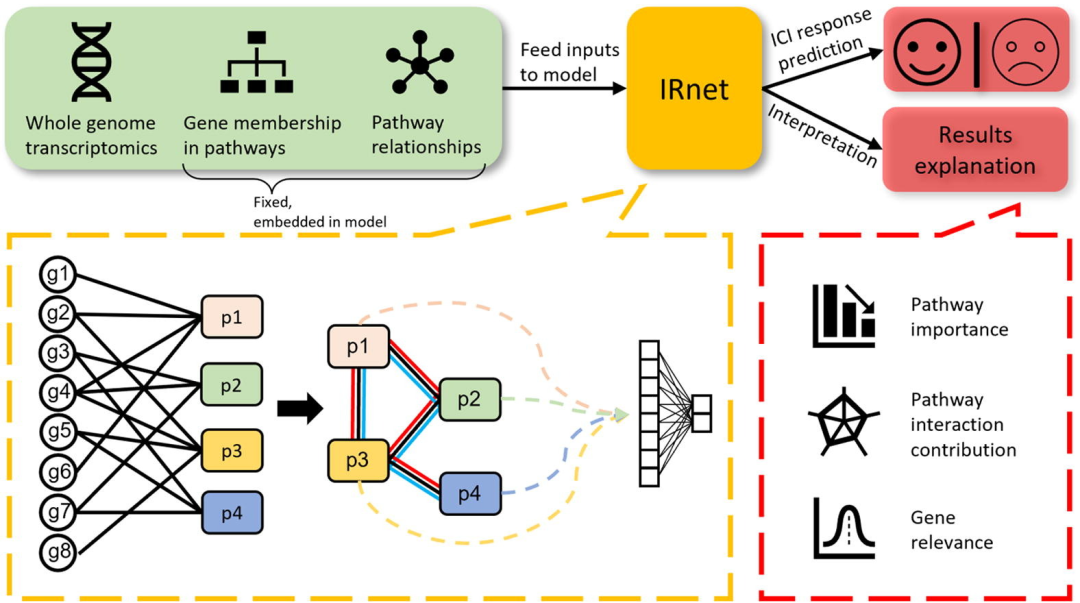
▲ IRnet模型架构的示意
小编接下来主要介绍一下IRnet的模型架构,其github仓如下,大家也可以自行深入了解:
-
https://github.com/yuexujiang/IRnet
IRnet的模型架构
① 首先,IRnet通过一个稀疏的全连接层将基因表达转化为通路嵌入(稀疏的原因则是因为基因只属于某些通路):
x_in = Input(shape=(n_genes,)) # 基因表达数据作为输入
x_drop1 = Dropout(x_dropRate)(x_in) # dropout层
# 自定义的稀疏张量层SparseTF类,具体实现并不难,输出是通路水平的网络嵌入
mapping_layer = SparseTF(n_pathways, mapp, activation='elu', W_regularizer=L1(mapping_l1_reg),name='mapping', kernel_initializer='glorot_uniform',use_bias=True)
layer2_output = mapping_layer(x_drop1)
layer2_res=Reshape([n_pathways,1])(layer2_output) # 重塑数据的形状
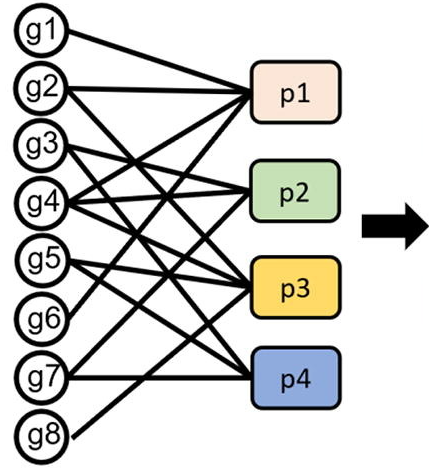
▲ ①稀疏的全连接层将基因表达转换为通路嵌入,图中gn代表第n个基因,pm代表第m个通路。
② 随后,使用两层的图注意力网络学习通路的交互作用,再通过全局注意力池化机制获得整个图的特征表示:
a_in = Input(shape=(n_pathways,),sparse=True) # 对接上方的数据输入
# 两层图注意力网络
x_1 = GATConv(gat1_channel,attn_heads=gat1_nhead,concat_heads=False,activation="tanh",return_attn_coef=False,dropout_rate=gat1_dropRate,kernel_regularizer=l2(gat1_l2_reg),attn_kernel_regularizer=l2(gat1_l2_reg),bias_regularizer=l2(gat1_l2_reg),bias_initializer='glorot_uniform',
)([layer2_res, a_in]) # 第一层图注意力网络,用于处理重塑后的映射输出和路径数据
x1bn = layers.BatchNormalization()(x_1) # 应用批量归一化,以帮助网络更快、更稳定地学习
x_2,att = GATConv(gat2_channel,attn_heads=1,concat_heads=True,activation="tanh",return_attn_coef=True,dropout_rate=gat2_dropRate,kernel_regularizer=l2(gat2_l2_reg),attn_kernel_regularizer=l2(gat2_l2_reg),bias_regularizer=l2(gat2_l2_reg),bias_initializer='glorot_uniform',
)([x1bn, a_in]) # 第二层图注意力网络,继续处理第一层的输出,同时返回注意力系数
x2bn = layers.BatchNormalization()(x_2) # 再次应用批量归一化
# 使用全局注意力池化来总结节点特征
attpool=GlobalAttentionPool(pool_channel, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=L1(pool_l1_reg))(x2bn)
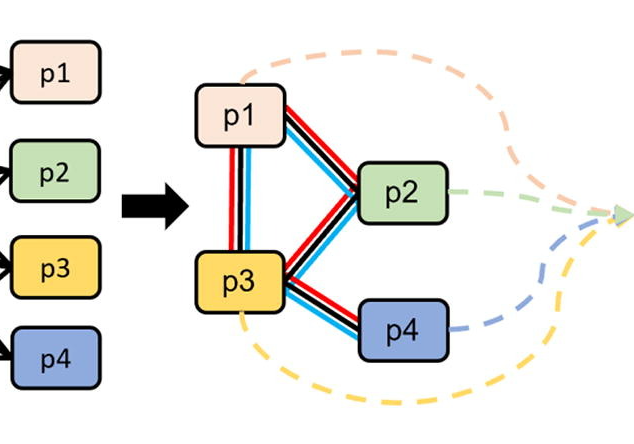
▲ ②使用上一层的通路嵌入pm,根据KEGG的注释将其构建成一个网络结构,同时作为图注意力网络的框架。
③ 最后,使用全局注意力池化的特征表示,通过一个全连接层与softmax激活函数获得分类的输出。
#全连接层,处理池化后的特征
x_fc1 = Dense(dense_channel, activation="elu")(attpool)
output = Dense(2, activation="softmax")(x_fc1) # 输出层,使用softmax进行多分类
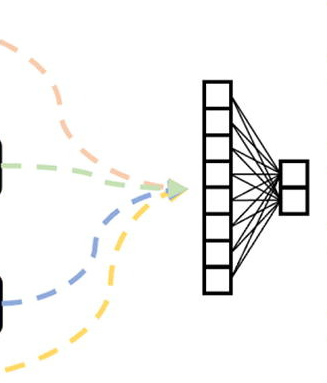
▲ ③使用全局注意力池化的特征表示通过一个全连接层获得分类结果,并用于计算损失以进行参数优化。
模型的学习过程使用焦点损失(Focal Loss)函数,后者用于处理样本不平衡的问题。
④ 由于网络架构中嵌入了基因、通路的信息,所以训练好的网络还可以用于评估基因、通路、通路交互对与预测结果的重要程度(在这里也就是对于预测免疫治疗反应的重要性):
-
通路重要性:基于全局注意力池化层中的注意力权重进行评估,为了简化分析,作者对病人维度和通路维度进行了平均。
-
通路交互重要性:通过第二层图注意力网络(GAT)的注意力权重来衡量的,通路j的权重反映了其在所有邻接通路中的相对重要性。
-
基因重要性:通过稀疏全连接层的学习权重来评估,该层模拟基因到通路的隶属关系。与病人特定的通路或通路交互重要性不同,一旦IRnet模型训练完成,基因重要性(权重)即固定,所以作者的github仓中也并没有给出基因重要性的预测。
⑤ 下面是github文档简要介绍的使用方法:
python ./predict.py \ # 脚本
-input ./example_expression.txt \ # 表达矩阵
-output ./prediction_results/ \ # 结果输出路径
-treatment anti-PD1 # 预测反应类型# 使用介绍
#usage: predict.py [-h] -input INPUTFILE -output OUTPUTDIR -treatment DRUG#IRnet: Immunotherapy response prediction using pathway knowledge-informed
#graph neural network#optional arguments:
# -h, --help show this help message and exit
# -input INPUTFILE Gene expression matrix with values separated by Tab. Rows
# are named with gene symbols. Columns are named with
# patient IDs. (default: None)
# -output OUTPUTDIR The name of the output directory. (default: None)
# -treatment DRUG Specify the immunotherapy treatment target, either "anti-
# PD1", "anti-PDL1", or "anti-CTLA4" (default: None)
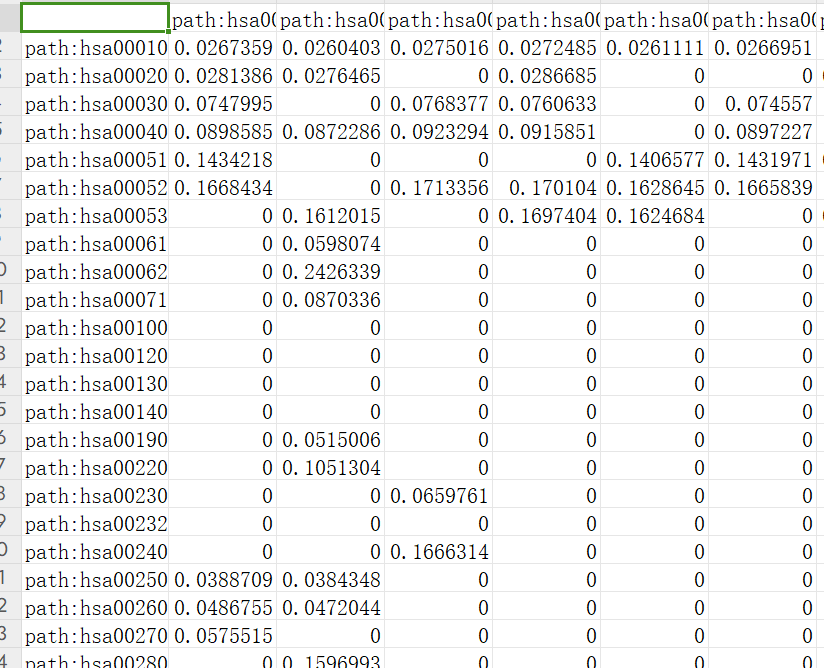
▲ 结果一:通路的交互重要性,每个样本都有
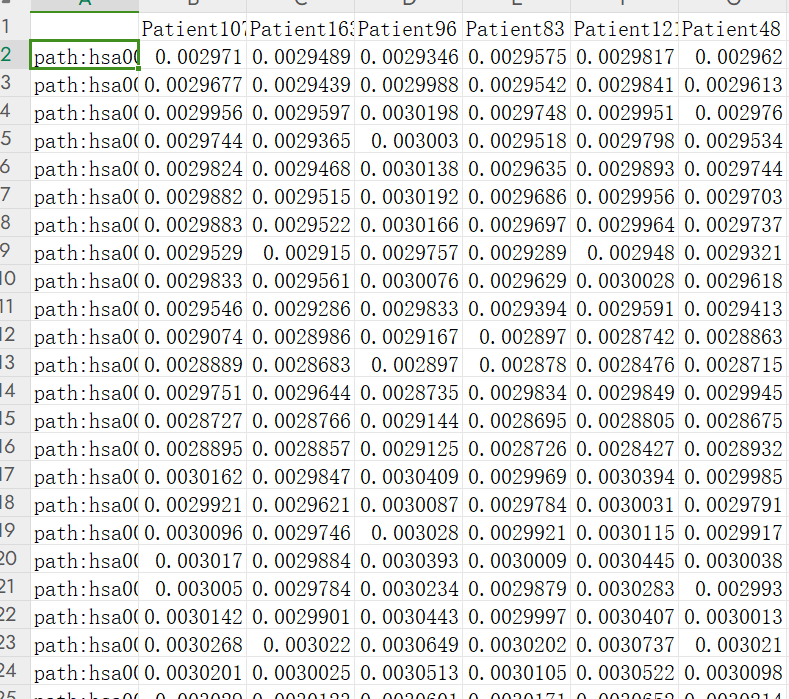
▲ 结果二:通路的重要性,每个样本都有

▲ 结果三:患者的预测得分与免疫治疗预测结果
作者提供的代码结果很简单,并且没有相关的可视化结果。同时,环境配置以及使用上会有不少bug。对于没有太多编程基础的铁子,小编将其环境配置以及运行过程全程包装在了r语言中,并且增加了通路注释以及两种对结果的可视化方案:
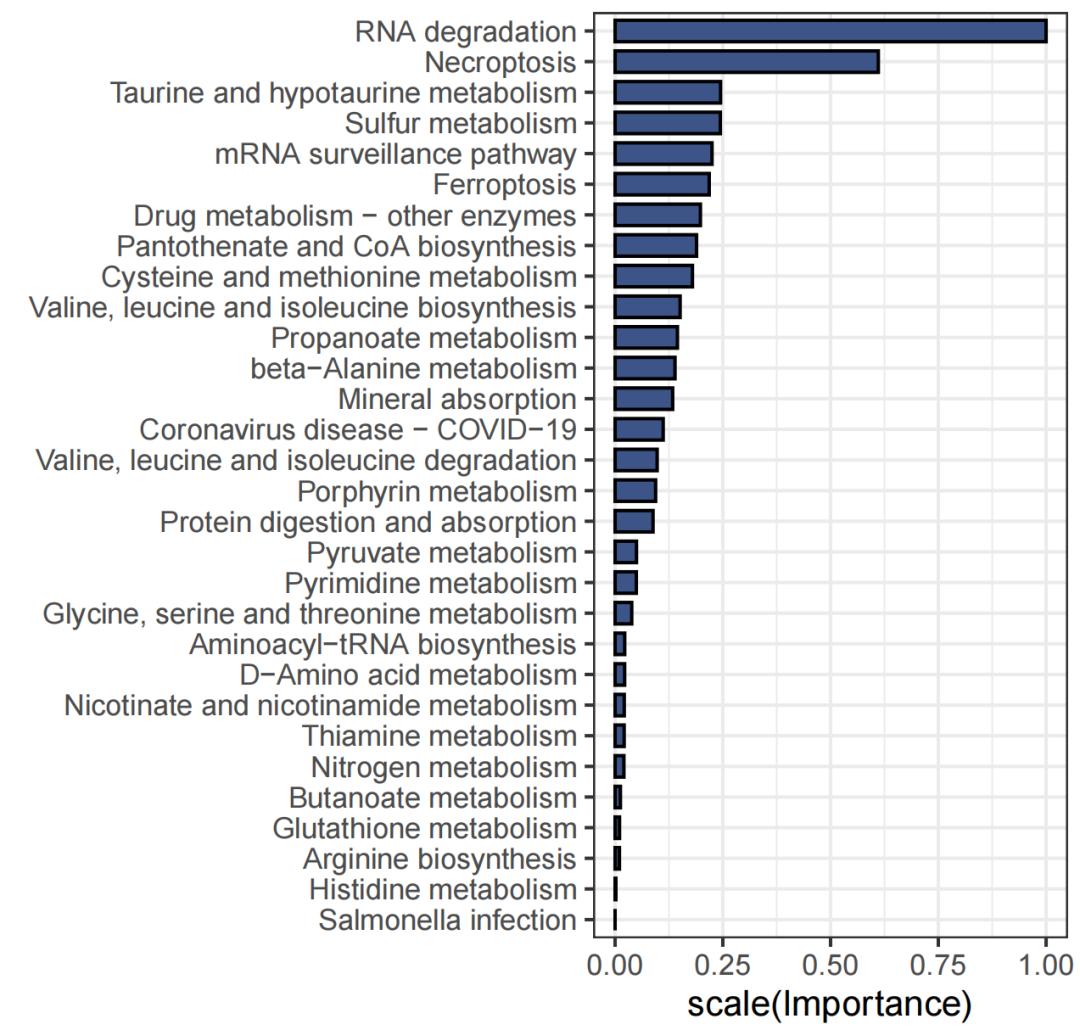
▲ 通路名称转换以及top重要性可视化
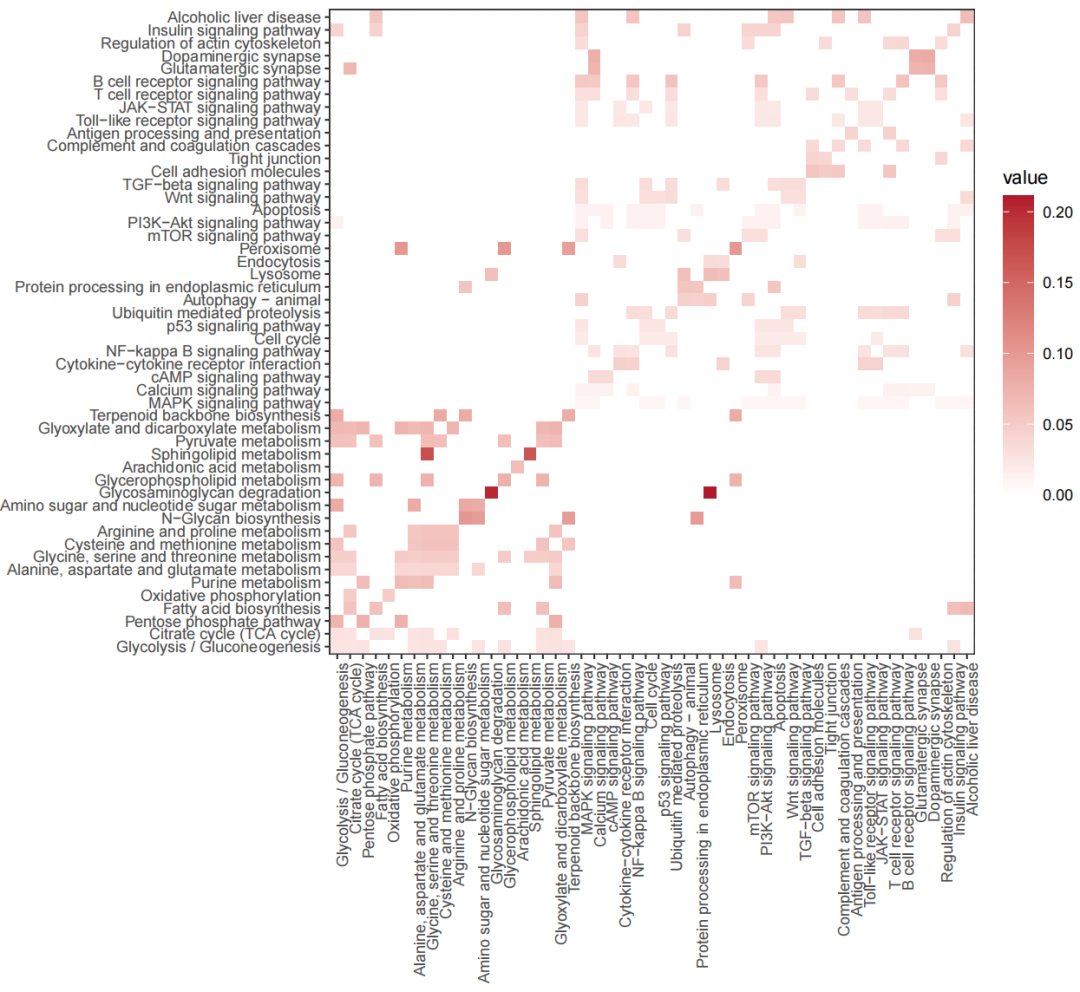
▲ top通路交互重要性的可视化

▲ 通路交互重要性的表格,可自行使用cytoscape进行可视化
有点意思
只用输入基因表达矩阵
当然训练是另外一回事
可惜这个模型没有提供基因重要性的计算
也没有提供完整的模型训练过程
同时也只是局限于免疫治疗预测
但是这些小编也可以做
二分类、回归、预后预测
就分享到这里了,欢迎关注!
这篇关于临床基础两手抓!这个12+神经网络模型太贪了,免疫治疗预测、通路重要性、基因重要性、通路交互作用性全部拿下!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






