基因专题

临床基础两手抓!这个12+神经网络模型太贪了,免疫治疗预测、通路重要性、基因重要性、通路交互作用性全部拿下!
生信碱移 IRnet介绍 用于预测病人免疫治疗反应类型的生物过程嵌入神经网络,提供通路、通路交互、基因重要性的多重可解释性评估。 临床实践中常常遇到许多复杂的问题,常见的两种是: 二分类或多分类:预测患者对治疗有无耐受(二分类)、判断患者的疾病分级(多分类); 连续数值的预测:预测癌症病人的风险、预测患者的白细胞数值水平; 尽管传统的机器学习提供了高效的建模预测与初步的特征重

bedtools subtract 基因区段取差集
基本概述: bedtools subtract 通俗的说,得到 A - B 的区段。如果在A中发现了B区段,就把 B 扣除,通过不同的参数,扣除的标准不一样。其中,参数 -A 可以达成 Remove features with any overlap 的效果(第四行)。 使用方法: bedtools subtract [OPTIONS] -a <BED/GFF/VCF> -b <BE

【佳学基因检测】网站加密证书失效后,如何移除并为新的证书安装准备环境?
【佳学基因检测】网站加密证书失效后,如何移除并为新的证书安装准备环境? 当WoTrus DV Server CA证书失效后,你需要确保你的Nginx配置中不再引用该证书,并且移除或替换相关的证书文件。以下是具体步骤: 1. 确认Nginx配置文件 首先,检查Nginx的配置文件,确保它不再引用旧的WoTrus证书。如果你已经使用Certbot安装了Let’s Encrypt证书,Certbo

外泌体相关基因肝癌临床模型预测——2-3分纯生信文章复现——5.拷贝数变异及突变图谱(2)
内容如下: 1.外泌体和肝癌TCGA数据下载 2.数据格式整理 3.差异表达基因筛选 4.预后相关外泌体基因确定 5.拷贝数变异及突变图谱 6.外泌体基因功能注释 7.LASSO回归筛选外泌体预后模型 8.预后模型验证 9.预后模型鲁棒性分析 10.独立预后因素分析及与临床的相关性分析 11.列线图,ROC曲线,校准曲线,DCA曲线 12.外部数据集验证 13.外泌

在线绘制哑铃图(dumbbell chart)展示基因拷贝数变异(CNV)
导读: 哑铃图的名称来源于其形状,它看起来像一个哑铃,有两个圆形的“重量”在两端,通过一根“杆”连接。常用于展示两个或多个数据集之间的差异。本文介绍了如何使用哑铃图展示基因的拷贝数变异。 Journal of Translational Medicine文章《SLC26A4 correlates with homologous recombination deficiency and pa



与PC1显著相关的基因 | p值计算
1. 相关系数的显著性 t=r*sqrt(n-2) / sqrt(1-r**2) 其中,统计量t符合自由度为 n-2 的t分布。 2. 与PC1显著相关的基因 就是求相关系数r=cor(PC1_score, Xk),其中 PC1_score 长度为样品总数,是PC1 的loading * 每个变量的scale后的值Xk是第k个变量在每个样品的值 然后由r计算t统计量,及对用的p值,见上文

零基础入门转录组数据分析——单基因ROC分析
零基础入门转录组数据分析——单基因ROC分析 目录 零基础入门转录组数据分析——单基因ROC分析1. ROC分析的基础知识2. 单基因ROC分析(Rstudio)——代码实操2. 1 数据处理2. 2 单基因ROC分析2. 3 ROC曲线简单可视化 1. ROC分析的基础知识 1.1 ROC分析是什么? ROC(Receiver Operating Characte
基因调控网络(gene regulatory network-GRN)分析基础概念
基础背景: 染色质、转录因子和基因之间的相互作用产生了复杂的调控回路,可以表示为基因调控网络(gene regulatory nerworks,GRNs) 1. 染色质(Chromatin) 染色质是由DNA和蛋白质(主要是组蛋白)组成的复合结构。它是细胞核中DNA的主要存储形式。在真核细胞中,染色质的状态可以是高度压缩的异染色质或相对松散的常染色质,这种状态会影响基因的表达。 作
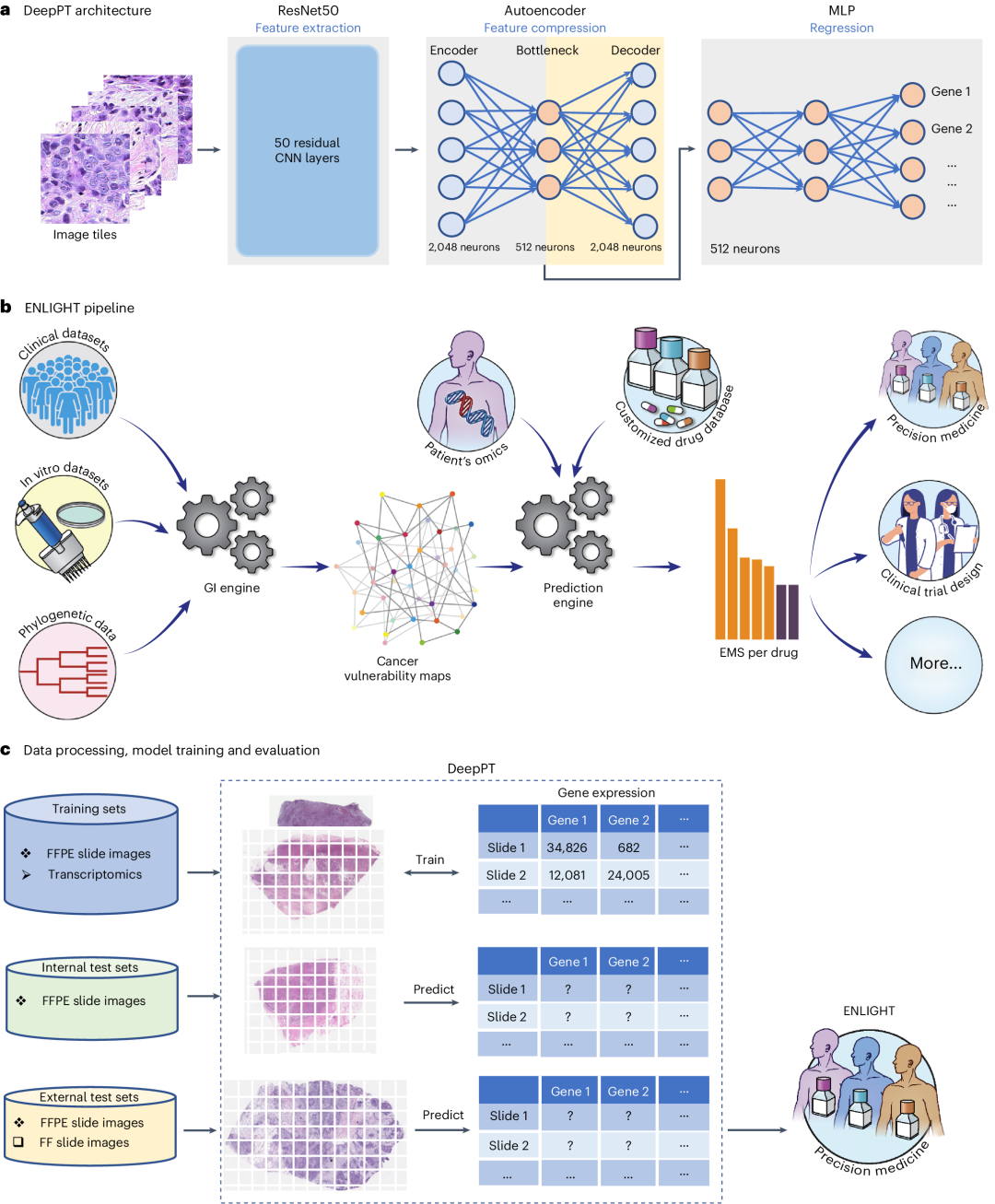
23+ 顶刊纯公开数据库建模!病理切片预测基因表达与患者治疗反应,原文提供了非常清晰的代码实现!
图像预测基因表达 病理学长期以来被认为是癌症临床诊断和预后的金标准。随着数字病理学的快速进步,机器学习和人工智能方法在图像分析中的应用,使得从肿瘤切片中提取临床相关信息成为可能。利用这些技术,全视野切片图像(WSI)结合苏木精-伊红(H&E)染色的组织切片已经用于计算机化的各类研究,这包括:肿瘤诊断、癌症类型分类、区分高低突变负荷的肿瘤、识别基因突变、预测患者生存、检测DNA甲基化模式和有丝分裂

两个基因相关性CPTAC蛋白组数据
目录 蛋白数据下载 ①蛋白数据下载 1,TCGA-选择泛癌数据 2,TCGA-TCPA 3,CPTAC(非TCGA) ②蛋白相关性分析 1,数据整理 2,蛋白相关性分析 PCAS在线分析 蛋白数据下载 CPTAC蛋白组学数据库介绍及数据下载分析 – 王进的个人网站 (jingege.wang) ①蛋白数据下载 可以下载泛癌蛋白数据:UCSC Xena (xena

两个基因相关性细胞系(CCLE)(升级)
目录 单基因CCLE数据 ①细胞系转录组CCLE数据下载 ②单基因泛癌表达 CCLE两个基因相关性 ①进行数据整理 ②相关性分析 单基因CCLE数据 ①细胞系转录组CCLE数据下载 基因在各个细胞系表达情况_ccle expression 23q4-CSDN博客 rm(list = ls())library(tidyverse)library(ggpubr)rt

使用MAKER进行基因注释(基础入门)
maker 在基因组注释上,MAKER算是一个很强大的分析流程。能够识别重复序列,将EST和蛋白序列比对到基因组,进行从头预测,并在最后整合这三个结果保证结果的可靠性。此外,MAKER还可以不断训练,最初的输出结果可以继续用作输入训练基因预测的算法,从而获取更高质量的基因模型。 Maker的使用比较简单,在软件安装成后,会有一个"data"文件夹存放测试数据 ls ~/o
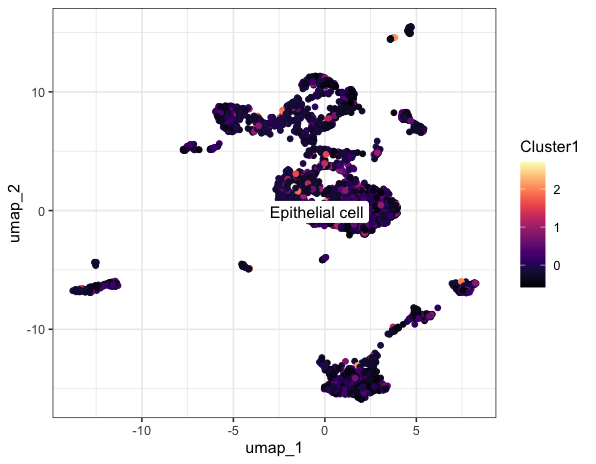
AUCell和AddModuleScore函数进行基因集评分
AUCell 和AddModuleScore 分析是两种主流的用于单细胞RNA测序数据的基因集活性分析的方法。这些基因集可以来自文献、数据库或者根据具体研究问题进行自行定义。 AUCell分析原理: 1、AUCell分析可以将细胞中的所有基因按表达量进行排序,生成一个基因排名列表,表达量越高的基因排名越靠前。 2、接下来对每个基因集中的基因找到它们在每个细胞的基因排名列表中的位置,这些位置则

易基因:NSUN2/YBX1介导m5C甲基化增强HGH1 mRNA稳定性以促进肿瘤进展 | 科研速递
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 RNA m5C甲基化已被证明广泛参与肿瘤的发生和发展。作为主要的m5C甲基转移酶,NSUN2在多种肿瘤类型中发挥着关键的调控作用。但NSUN2介导的m5C修饰对乳腺癌(BC)的具体作用仍不清楚。 郑州大学第一附属医院/河南省精准临床药学重点实验室阚全程、田鑫团队和中国科学院大学杨运桂合作阐明NSUN2如何通过m5C修饰调控靶基因H

基因相关性(信息学奥赛一本通-T1131)
【题目描述】 为了获知基因序列在功能和结构上的相似性,经常需要将几条不同序列的DNA进行比对,以判断该比对的DNA是否具有相关性。 现比对两条长度相同的DNA序列。定义两条DNA序列相同位置的碱基为一个碱基对,如果一个碱基对中的两个碱基相同的话,则称为相同碱基对。接着计算相同碱基对占总碱基对数量的比例,如果该比例大于等于给定阈值时则判定该两条DNA序列是相关的,否则不相关。 【输入】 有三行,第
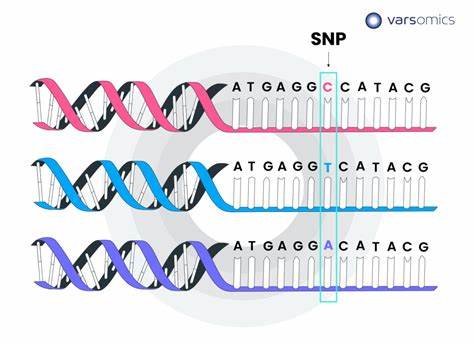
生信技能48 - 如何获取基因的SNP及RefSeq参考序列命名规则
1. SNP概念 SNP 是指基因组水平上由单个核苷酸的变异所引起的DNA 序列多态性,在群体中的发生频率不小于1 %,包括单个碱基的转换、颠换、插入和缺失等。每核苷酸发生突变的概率大约为10 -9 , 由于压力选择,SNP在单个基因和基因组以及动物不同种群间分布是不均匀的,在非编码区区SNP数量要多于编码区。 1.1 转换 转换是指同类型碱基之间的转换,如嘌呤与嘌呤( G2A) 、嘧啶与
如何快速从基因组中提取基因、转录本、蛋白、启动子、非编码序列?
有读者留言想要提取外显子,内含子,启动子,基因体,非编码区,编码区,TSS上游1500,TSS下游500的序列。下面我们就来示范如何提取这些序列。 NGS基础 - 参考基因组和基因注释文件提到了如何下载对应的基因组序列和基因注释文件。 假如我们已经拿到了基因组序列文件GRCh38.fa和基因注释文件GRCh38.gtf,也可从文后链接获取。 查看下文件内容和格式 基因组序列文件为FASTA

美团面试:百亿级分片,如何设计基因算法?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的架构类/设计类的场景题: 1.说说分库分表的基因算法? 2.大厂常用的基因算法,是如何设计的? 3.百亿级分片,如何设计基因算法? 最近有小伙伴在面试美团,又遇到这一个问题。小伙伴支支吾吾的说了几句,卒。 所以
Microbiome | binning+转录组→首个草鱼肠道基因集目录发布啦
草鱼便宜又好吃 但是你了解草鱼吗? 草鱼的肠道里定殖着成千上万的共生微生物,它们与草鱼共同生存,相互影响。这些微生物在草鱼的新陈代谢、免疫调节等方面发挥着重要作用。 虽然同为经济作物,鱼类的微生态相关研究远远不如于其他畜禽,经济鱼类的微生物基因目录也尚未构建。 近期,来自中国农业科学院饲料研究所的研究团队,在《Microbiome》上发表了题目为《Decipher

易基因:人类精子发生过程中的全基因组DNA甲基化水平变化|研究速递
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 精子发生和精子功能需要在生殖细胞系中正确建立DNA甲基化模式。 德国明斯特大学生殖与再生生物学研究所生殖医学中心Sandra Laurentino团队分析了人类精子发生(spermatogenesis)过程中的全基因组DNA甲基化变化以及在精子发生障碍时的变化。分析结果表明精子发生与甲基化重塑有关,包括初级精母细胞中DNA甲基化的

伦敦银的白银现货交易“基因”
为什么说伦敦银拥有与现货白银同等的“基因”呢?这主要是因为伦敦银的交易机制允许投资者在交易成交后的1~2个工作日内完成交割手续,但很多投资者并不进行实际的白银交割,而是选择到期平仓以赚取差价利润,这种交易方式就构成了现货交易的基础。 伦敦银的市场是一个国际化的市场,任何人无法操纵它的市场价格,从而保证了市场的公开透明。利用资金杠杆的原理,伦敦银投资者可以用较小的资金进行较大规模的投资,大大提
易基因:RNA免疫共沉淀测序 (RIP-seq) 技术介绍
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 RIP-seq是将RNA免疫共沉淀(RNA Immunoprecipitation,RIP)与二代测序技术(NGS)相结合以研究细胞内RNA与蛋白互作的技术,RIP利用目标蛋白抗体把相应的RNA-蛋白复合物(RNA Binding Protein,RBP)沉淀下来,然后经过富集和纯化就可以对结合在复合物上的RNA进行测序分析。 R