human专题
MonoHuman: Animatable Human Neural Field from Monocular Video 翻译
MonoHuman:来自单目视频的可动画人类神经场 摘要。利用自由视图控制来动画化虚拟化身对于诸如虚拟现实和数字娱乐之类的各种应用来说是至关重要的。已有的研究试图利用神经辐射场(NeRF)的表征能力从单目视频中重建人体。最近的工作提出将变形网络移植到NeRF中,以进一步模拟人类神经场的动力学,从而动画化逼真的人类运动。然而,这种流水线要么依赖于姿态相关的表示,要么由于帧无关的优化而缺乏运动一致性

论文笔记:Estimating future human trajectories from sparse time series data
sigspatial 2023 humob竞赛paper hiimryo816/humob2023-MOBB (github.com) 1 数据集分析 这里只分享了HuMob数据集1的内容 1.1 假日分析 对HuMob数据集#1地理数据的方差分析显示了非工作日的模式 在某些天的y坐标方差中有显著的峰值,这是非工作日的象征【x坐标有相似的模式】 ——>识别了任务1数据集中最有可能是

【python】OpenCV—Single Human Pose Estimation
文章目录 1、Human Pose Estimation2、模型介绍3、基于图片的单人人体关键点检测4、基于视频的单人人体关键点检测5、左右校正6、关键点平滑7、涉及到的库函数scipy.signal.savgol_filter 8、参考 1、Human Pose Estimation Human Pose Estimation,即人体姿态估计,是一种基于计算机视觉和深度学习的技

姿态估计Rethinking on Multi-Stage Networks for Human Pose Estimation论文梗概及代码解读
2018年COCO关键点检测冠军算法MSPN,姿态估计,Top-down的技术路线 应该是截止2019年10月26日时开源的最好的姿态估计算法之一了 旷世出品 代码链接点这,是基于Pytorch的 论文链接点这 摘要 姿态估计方法以基本形成one-stage 和 multi-stage两个路线 多阶段看上去更适合任务,但是现在多阶段的性能还是不如单阶段的 我们论文就来研究这个问题,我们讨论当下
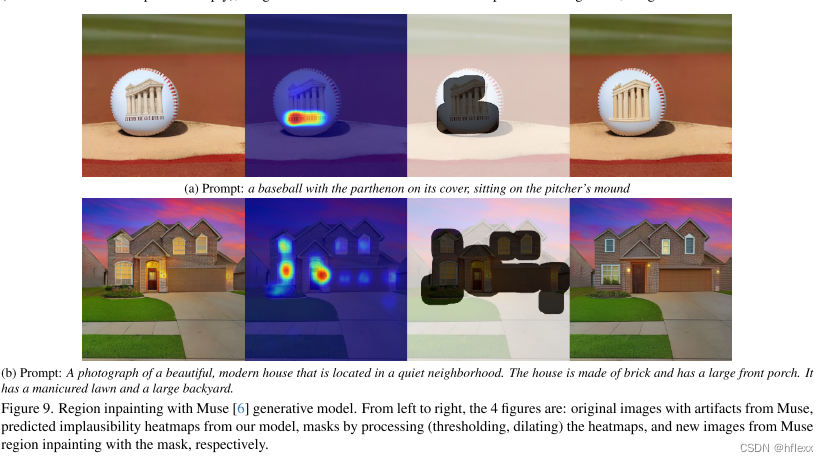
AIGC-CVPR2024best paper-Rich Human Feedback for Text-to-Image Generation-论文精读
Rich Human Feedback for Text-to-Image Generation斩获CVPR2024最佳论文!受大模型中的RLHF技术启发,团队用人类反馈来改进Stable Diffusion等文生图模型。这项研究来自UCSD、谷歌等。 在本文中,作者通过标记不可信或与文本不对齐的图像区域,以及注释文本提示中的哪些单词在图像上被歪曲或丢失来丰富反馈信号。 在 18K 生成图像 (R

3DCNN参数解析:2013-PAMI-3DCNN for Human Action Recognition
3DCNN参数解析:2013-PAMI-3DCNN for Human Action Recognition 参数分析 Input:7 @ 60 × \times × 40, 7帧,图片大小60 × \times × 40 hardwired: H1 产生5通道信息,分别是gray, gradient-x, gradient-y, optflow-x, optflow-y

hdu 1080 ;poj 1080 Human Gene Functions
求两串字符串的匹配。类似于求最长公共子序列。不同的是:上下两串不同的匹配有不同的权值。 可以在两串加入‘-’, 开始题目理解有误,以为只能在长度较短的那串加入‘-’ 。说到底还是太水了。 这个题目的初始化需要注意一下 #include <iostream>#include<algorithm>#include<cstdio>#include<cstring>using name

配置 human_pose_estimation_demo 的开发环境
配置 human_pose_estimation 的开发环境 主要讲述如何在 VS2017 IDE 里面配置 OpenIVNO 的演示案例 human_pose_estimation_demo 开发环境。 1. 开发环境说明 系统版本:windows 10OpenVINO 版本:2020 1IDE :VS2017 2. 创建项目 打开 VS017 ,新建项目,在新建项目时选择空项目 然后
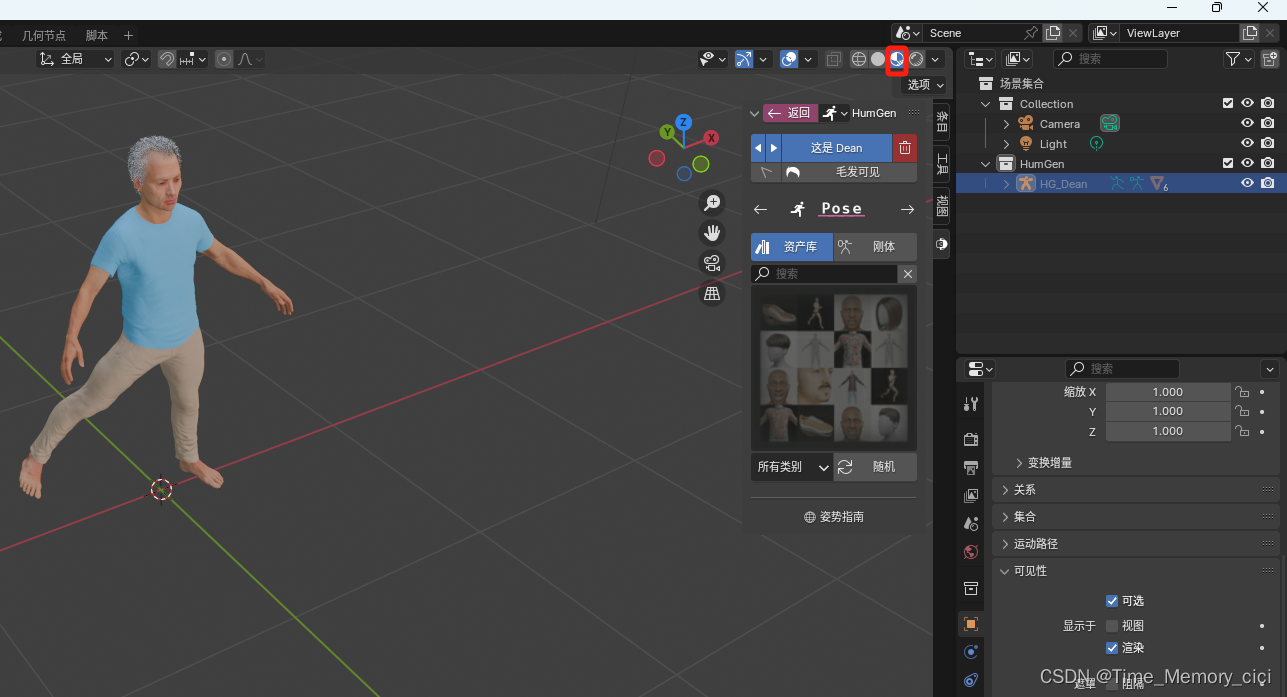
Blender人物插件Human Generator下载及使用方法
一、Blender介绍及安装 Blender是一款免费开源三维图形图像软件,提供从建模、动画、材质、渲染、到音频处理、视频剪辑等一系列动画短片制作解决方案。 安装方式非常简单,官网下载即可,截止到2024年5月,Blender以更新至4.1版本了。 Blender官网:https://www.blender.org/ 二、Blender人物插件Human Generator介绍 Huma

智能体之斯坦福AI小镇(Generative Agents: Interactive Simulacra of Human Behavior)
相关代码地址见文末 论文地址:Generative Agents: Interactive Simulacra of Human Behavior | Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology 1.概述 论文提出了一种多个智能体进行协同,进而模拟

重点解码效果总结#####论文阅读——《Towards a Human-like Open-Domain Chatbot》
Introduction 开放的chatbot API总结 cleverbot API: https://www.cleverbot.com/api/ https://github.com/plasticuproject/cleverbotfreexiaobing: https://www.msxiaobing.com/mitsuku: https://www.pandorabots.com/

【论文笔记】Training language models to follow instructions with human feedback B部分
Training language models to follow instructions with human feedback B 部分 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练+少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm);下游各种具体任务的适应是通过在模型架

hdu 1080 dp Human Gene Functions
分三种情况考虑。 dp[i][j]=max(dp[i-1][j-1]+a[s1[i]][s2[j]],max(dp[i-1][j]+a[s1[i]][4],dp[i][j-1]+a[s2[j]][4])); #include <iostream>using namespace std;int max(int a,int b){return a>b?a:b;}int main(

【论文笔记】Training language models to follow instructions with human feedback A部分
Training language models to follow instructions with human feedback A 部分 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练+少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm);下游各种具体任务的适应是通过在模型架

HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors
标题:HARDVS: 用动态视觉传感器重新审视人类行为识别 原文链接:HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors| Proceedings of the AAAI Conference on Artificial Intelligencehttps://ojs.aaai.org/index

3-D Human Modeling and Animation, Second Edition
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp All the tools and know-how to create digital characters that can move, express emotions, and talk 3-D Hum

Human-Computer Interaction Fundamentals
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Channel Data Warehouse Sql Language ACCESS FileMaker Data Mining Database Design Database General
Ethersjs human readable abi
Ethersjs human readable abi ethersjs 使用可阅读的abi方式初始化合约rpc方法时,应该如何填写,以至于可以正确使用struct类型进行传参。填写方式如下,来源于ethers文档官网 const humanReadableAbi = [// Simple types"constructor(string symbol, string name)","func

论文笔记:Are Human-generated Demonstrations Necessary for In-context Learning?
iclr 2024 reviewer 评分 6668 1 intro 大型语言模型(LLMs)已显示出在上下文中学习的能力 给定几个带注释的示例作为演示,LLMs 能够为新的测试输入生成输出然而,现行的上下文学习(ICL)范式仍存在以下明显的缺点: 最终性能极度敏感于选定的演示示例,到目前为止,还没有公认的完美演示选择标准制作演示可能是劳动密集型的,麻烦的甚至是禁止性的 在许多 ICL 场景中

Stacked Hourglass Networks for Human Pose Estimation 用于人体姿态估计的堆叠沙漏网络
Stacked Hourglass Networks for Human Pose Estimation 用于人体姿态估计的堆叠沙漏网络 这是一篇关于人体姿态估计的研究论文,标题为“Stacked Hourglass Networks for Human Pose Estimation”,作者是 Alejandro Newell, Kaiyu Yang, 和 Jia De

photomaker:customizing realistic human photos via stacked id embedding
PhotoMaker: 高效个性化定制人像照片文生图 - 知乎今天分享我们团队最新的工作PhotoMaker的技术细节。该工作开源5天Githubstar数已过6千次,已列入Github官方Trending榜第一位,PaperswithCode热度榜第一位,HuggingFace Spaces趋势榜第一位。项目主页在: PhotoMa…https://zhuanlan.zhihu.com/p/68
人眼视觉系统(Human Visual System)
转载自:点击打开链接 人眼类似于一个光学系统,但它不是普通意义上的光学系统,还受到神经系统的调节。人眼观察图像时可以用以下几个方面的反应及特性: (1)从空间频率域来看,人眼是一个低通型线性系统,分辨景物的能力是有限的。由于瞳孔有一定的几何尺寸和一定的光学像差,视觉细胞有一定的大小,所以人眼的分辨率不可能是无穷的,HVS对太高的频率不敏感。 (2)人眼对亮度的响应具有对数非线性性质,以达到
Training language models to follow instructions with human feedback
Abstract 使语言模型变得更大并不意味着它们本身就能更好地遵循用户的意图。模型的输出结果可能存在以下问题 不真实有毒对用户没有帮助 即这些模型没有和用户 “对齐”(aligned) 在给定的 Prompt 分布上,1.3B 的 InstructGPT 的输出比 175B GPT-3 的输出更好(尽管参数量相差 100 多倍)。 1 Introduction 语言建模的目标:pr
601. Human Traffic of Stadium - 体育馆的人流量 <Hard> - 重点警告
表:Stadium +---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int || visit_date | date | | people | int | +---------------+------
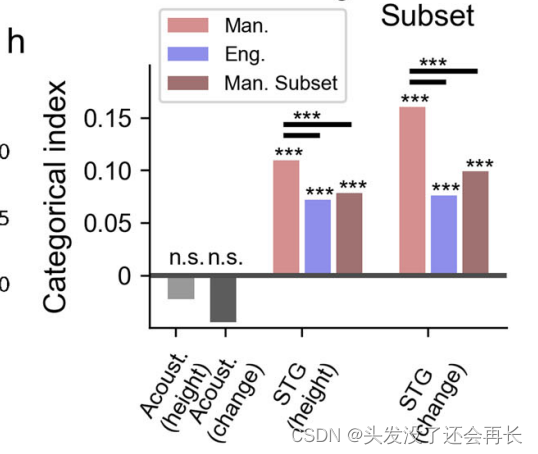
语音神经科学—05. Human cortical encoding of pitch in tonal and non-tonal languages
Human cortical encoding of pitch in tonal and non-tonal languages(在音调语音和非音调语言中人类大脑皮层的音高编码) 专业术语 tonal language 音调语言 pitch 音高 lexical tone 词汇音调 anatomical properties 解刨学特性 temporal lobe 颞叶 superior

win10下采用XShell+Xmanager运行lightweight-human-pose-estimation
目录 1.背景 2.系统及软件配置 3.开始工作 4.各种报错以及解决方案 4.1 No module named “XXX” 4.2 ImportError: libGL.so.1: cannot open shared object file: No such file or directory 4.3 qt.qpa.plugin: Could not load the Qt