本文主要是介绍HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

标题:HARDVS: 用动态视觉传感器重新审视人类行为识别
原文链接:HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors| Proceedings of the AAAI Conference on Artificial Intelligence![]() https://ojs.aaai.org/index.php/AAAI/article/view/28372
https://ojs.aaai.org/index.php/AAAI/article/view/28372
源码:GitHub - Event-AHU/HARDVS: [AAAI-2024] HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors![]() https://github.com/Event-AHU/HARDVS?tab=readme-ov-file
https://github.com/Event-AHU/HARDVS?tab=readme-ov-file
发表:AAAI 2024
目录
摘要
介绍
相关工作
HARDVS基准数据集
方法
概述
初始空间和时间嵌入
空间和时间增强学习
融合Transformer
损失函数
实验
数据集和评估指标
与SOTA算法的比较
消融实验
组件分析
关于输入帧数的分析
分析空间数据的分割块大小
分析Transformer层的层数
模型参数和运行效率
可视化
结论
读后总结
摘要
人类活动识别(human activity recognition,HAR)算法的主要流派是基于RGB摄像头开发的,通常受到照明、快速运动、隐私保护和大能耗的影响。与此同时,受生物启发的事件摄像头(event cameras)因其独特的特性而引起了极大的兴趣,如高动态范围、密集的时间但稀疏的空间分辨率、低延迟、低功耗等。由于这是一种新兴的传感器,甚至还没有针对HAR的现实大规模数据集。考虑到其巨大的实际价值,在本文中,我们提出了一个大规模基准数据集,称为HARDVS,其中包含300个类别和100,000多个事件序列。我们评估并报告了多种流行的HAR算法的性能,为未来的研究提供了广泛的基准。更重要的是,我们提出了一种新颖的空间-时间特征学习和融合框架,称为ESTF,用于基于事件流的人类活动识别。它首先使用StemNet将事件流投影到空间和时间嵌入中,然后使用Transformer网络对双视图表示进行编码和融合。最后,双重特征被串联并输入到分类头部进行活动预测。对多个数据集的广泛实验充分验证了我们模型的有效性。数据集和源代码将在https://github.com/Event-AHU/HARDVS 上发布。
介绍
随着智能城市的迅速发展,准确高效地识别人类行为(即人类活动识别,HAR)正在成为一项极其紧迫的任务。大多数研究人员基于广泛部署且易于收集数据的RGB摄像头开发HAR算法(Kong和Fu,2018年;Ahmad等人,2021年)。在大规模基准数据集和深度学习的帮助下,常规场景中的HAR已经得到了一定程度的研究。然而,由于使用RGB传感器,监控视频的存储、传输和分析限制了实际系统中的需求。更详细地说,标准RGB摄像头的帧率有限(例如,30帧每秒),这使得难以捕捉快速移动的物体,并容易受到运动模糊的影响。低动态范围(60 dB)使得RGB传感器在低照明环境下效果不佳。它还受到相邻帧之间高冗余的影响,需要更多的存储和能耗。隐私保护也极大地限制了其发展。因此,一个自然的问题是我们是否必须使用RGB传感器来识别人类活动?
最近,受生物启发的传感器(称为事件摄像头),如DAVIS(Brandli等人,2014年)、CeleX(Chen和Guo,2019年)、ATIS(Posch、Matolin和Wohlgenannt,2010年)以及PROPHESEE,引起了越来越多研究者的关注。与以同步方式记录光线的RGB摄像头不同(即视频帧),事件摄像头异步输出事件(或脉冲),对应着光照变化。换句话说,事件摄像头的每个像素在光线变化超过阈值时独立记录一个二进制值。增加和减少照明的事件分别称为ON和OFF事件。由于独特的采样机制,异步事件在空间上稀疏但在时间上密集。它受运动模糊的影响较小,因此适用于捕捉快速移动的人类动作,例如魔术师的快速手掌移动和运动员的运动识别。它具有更高的动态范围(120 dB)和更低的延迟,即使在低照明条件下,也能与标准RGB摄像头相比表现更良好。此外,存储和能耗也显著降低。事件流突出显示轮廓信息,并在很大程度上保护个人隐私。根据上述观察和思考,我们受到启发,通过使用事件摄像头来解决野外的人类活动识别问题。
尽管已经有几个用于分类任务的基准数据集被提出(Bi等,2020年;Amir等,2017年;Li等,2017年;Serrano-Gotarredona和Linares-Barranco,2015年;Kuehne等,2011年;Soomro、Zamir和Shah,2012年;Kliper-Gross、Hassner和Wolf,2011年;Plana- mente等,2021年;Cannici等,2021年),但其中大多数是从RGB视频通过模拟器转换而来的模拟/合成数据集。一些研究人员通过在显示RGB视频时录制屏幕来获得事件数据。显然,这些数据集很难反映真实世界场景中事件摄像头的特性,特别是快速移动和低光照情况。ASL-DVS由Bi等人提出(Bi等,2020年),由100800个样本组成,但只能用于手势识别,有24个类别。DvsGesture(Amir等,2017年)在深度学习时代也受到规模和类别的限制。此外,一些数据集的性能已经达到饱和,例如,Wang等人(Wang等,2019年a)已经在DvsGesture(Amir等,2017年)数据集上达到了97.08%。因此,研究界仍然对在野外记录的大规模HAR基准数据集有着坚实的需求。
在本文中,我们提出了一个新的大规模基准数据集,称为HARDVS,以解决缺乏真实事件数据的问题。具体来说,我们提出的HARDVS数据集包含了使用DAVIS346摄像头录制的100,000多个视频片段,每个片段持续时间约为5-10秒。它包含了300个日常生活中的人类活动类别,例如喝水、骑自行车、坐下和洗手等。我们考虑了以下因素,使我们的数据更加多样化,包括多视图、照明、运动速度、动态背景、遮挡、闪光灯和摄影距离。据我们所知,我们提出的HARDVS是第一个在野外进行人类活动识别的真实、大规模且具有挑战性的基准数据集。图1显示了现有识别数据集与我们的HARDVS之间的比较。
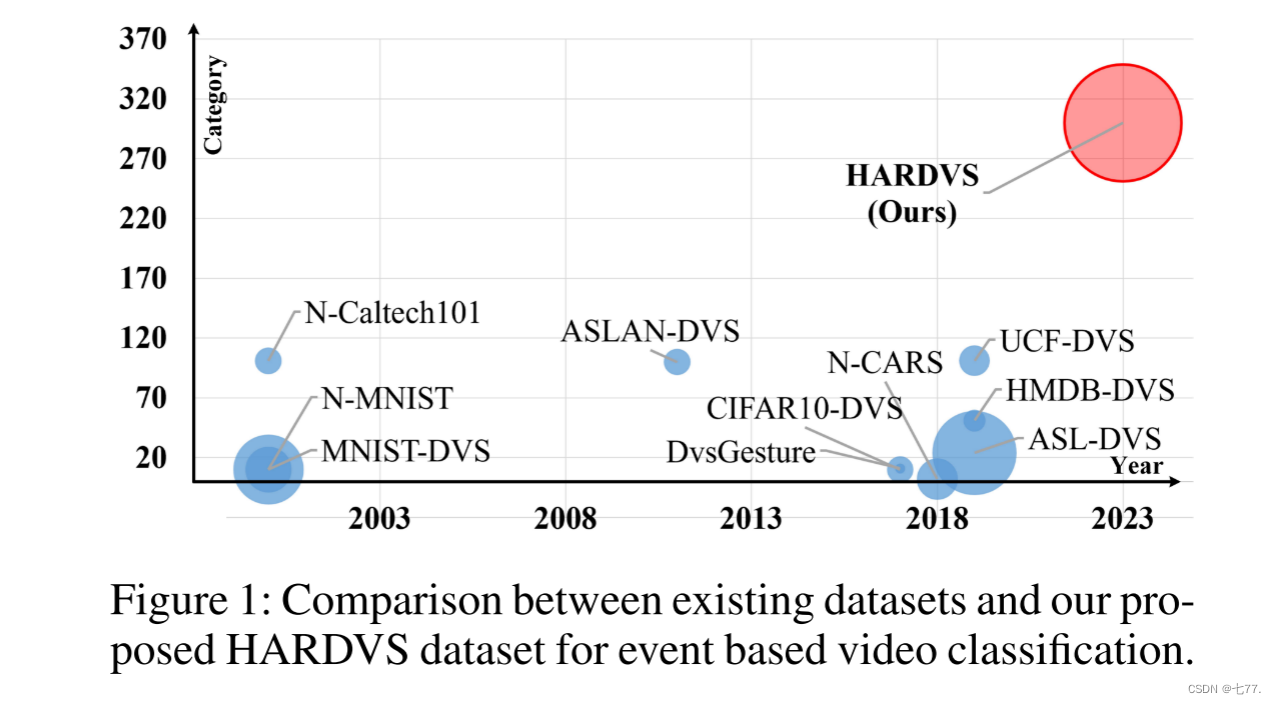
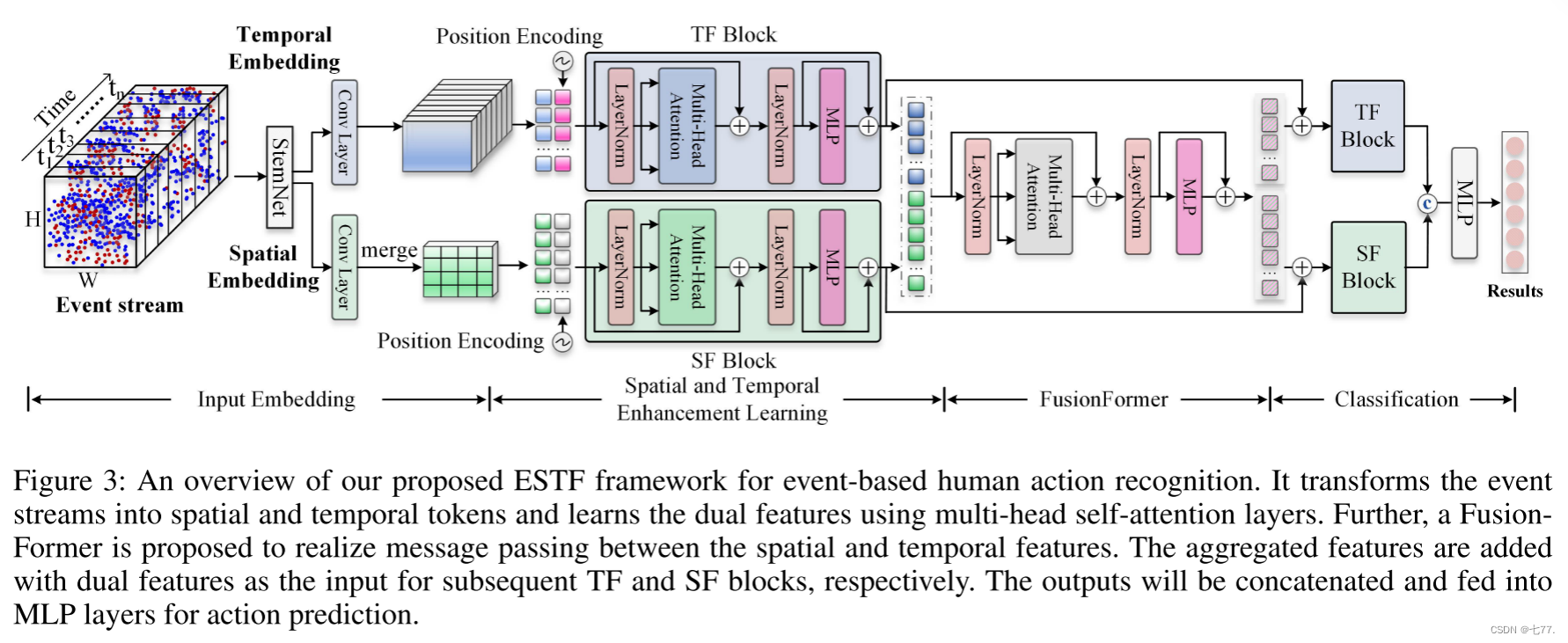
基于我们新提出的HARDVS数据集,我们构建了一个新颖的基于事件的人类动作识别框架,称为ESTF(事件空间-时间变换器)。如图3所示,ESTF将事件流转换为空间和时间令牌序列,并分别利用SpatialFormer(SF)和TemporalFormer(TF)学习双重特征。此外,我们提出了一个FusionFormer(融合模块)来实现空间和时间特征之间的信息传递。将聚合表示与双分支的特征相加作为后续学习块的输入。输出将被串联并输入到两个MLP层进行最终的动作预测。
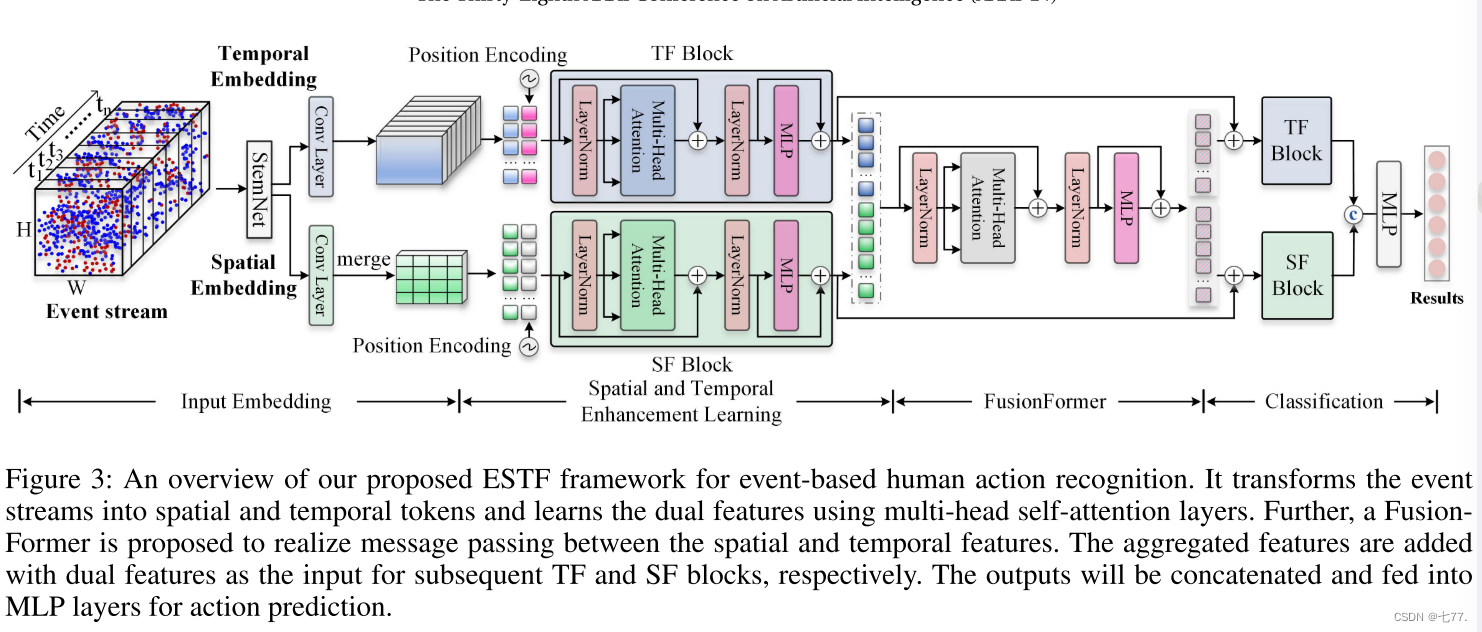
总的来说,本文的贡献可以总结为以下三个方面:
• 我们提出了一个新的用于人类活动识别的大规模神经形态学数据集,称为HARDVS。它包含了300个类别的100,000多个样本,并充分反映了真实世界中的挑战因素。
• 我们提出了一种新颖的基于事件的空间-时间变换器(ESTF)方法,通过利用空间和时间特征学习,并将它们与Transformer网络融合,实现了对人类动作的识别。对多个基于事件的分类数据集进行的广泛实验充分证明了我们提出的ESTF方法的有效性。
• 我们重新训练并报告了多个流行的HAR算法在我们的HARDVS数据集上的性能,为未来的工作提供了丰富的基线,用于在HARDVS数据集上进行比较。
相关工作
在使用事件传感器进行人类活动识别(HAR)方面,相比RGB摄像头,很少有研究人员专注于基于事件摄像头的HAR。Arnon等人(Amir等人,2017年)提出了基于TrueNorth神经突触处理器的第一个手势识别系统。Xavier等人(Clady等人,2017年)提出了一种基于事件的无亮度特征,用于局部角点检测和全局手势识别。陈等人(Chen等人,2021年)提出了一种基于DVS的手势识别系统,并设计了一款带有高频主动LED标记的可穿戴手套,充分利用了其特性。陈等人(Chen等人,2019年)提出了一种视网膜型事件驱动表示(EDR),它可以实现生物视网膜的三个重要功能,即对数转换、ON/OFF通路和多个时间尺度的整合。图神经网络(GNN)和SNN也被用于基于事件的识别。具体来说,王等人(Wang等人,2021年b)采用GNN和CNN进行步态识别。邢等人设计了一种用于基于事件序列的尖峰卷积循环神经网络(SCRNN)架构(邢、Di Caterina和Soraghan,2020年)。根据我们的观察,这些工作仅在简单的HAR数据集或模拟数据集上进行了评估。因此,引入一个大规模的HAR数据集用于当前评估是必要且迫切的。
表1显示,目前大多数基于事件摄像头的识别数据集都是人工数据集。通常,研究人员会将RGB HAR数据集显示在大屏幕上,并使用神经形态传感器记录活动。例如,N-Caltech101(Orchard等人,2015年)和N-MNIST(Orchard等人,2015年)分别使用ATIS摄像头记录,其中包含101和10个类别。Bi等人(Bi等人,2020年)还将流行的HAR数据集转换为模拟事件流,包括HMDB-DVS(Bi等人,2020年;Kuehne等人,2011年)、UCF-DVS(Bi等人,2020年;Soomro、Zamir和Shah,2012年)和ASLAN-DVS(Kliper-Gross、Hassner和Wolf,2011年),进一步扩展了可用于HAR的数据集数量。然而,这些模拟的事件数据集很难反映事件摄像头的优势,如低光照、快速运动等。目前有三个用于分类的真实事件数据集,即DvsGesture(Amir等人,2017年)、N-CARS(Sironi等人,2018年)和ASL-DVS(Bi等人,2020年),但这些基准受到规模、类别和场景的限制。具体来说,这些数据集只包含11、2和24个类别,并且很少考虑多视图、运动和闪光等挑战因素。与现有数据集相比,我们提出的HARDVS数据集规模大(100,000个样本)且类别广泛(300个类别),适用于深度神经网络。我们的序列是在野外录制的,充分反映了前述属性的特征。我们相信我们提出的基准数据集将极大推动基于事件的HAR的发展。
HARDVS基准数据集
重点 我们旨在为基于DVS的人类活动识别提供一个良好的训练和评估平台。在构建HARDVS基准数据集时,考虑了以下属性/亮点:
1). 大规模:众所周知,大规模数据集在深度学习时代扮演着非常重要的角色。在这项工作中,我们收集了超过100,000个DVS事件序列,以满足人类活动识别大规模训练和评估的需求。
2). 多样性:现实世界中可能存在成千上万种人类活动,但现有的基于DVS的HAR数据集只包含有限的类别。因此,很难充分反映HAR算法的分类和识别能力。我们新提出的HARDVS包含300个类别,比其他DVS数据集大几倍。
3). 不同的拍摄距离:HARDVS数据集是在不同距离下收集的,即1-2米、3-4米和5米以上。
4). 长期性:大多数现有的基于DVS的HAR数据集是微秒级的,相比之下,我们HARDVS数据集中的每个视频持续约5秒钟。
5). 双模态性:DAVIS346摄像头可以同时输出RGB帧和事件流,因此,我们的数据集也可以通过融合视频帧和事件用于HAR。在这项工作中,我们专注于仅使用DVS进行HAR,但RGB帧也将被发布以支持基于双模态融合的HAR研究。
我们的数据集考虑了多个可能影响使用DVS传感器进行HAR结果的挑战因素。具体介绍如下:
(a). 多视角:我们收集了同一行为的不同视角以模拟实际应用,包括正面、侧面、水平、俯视和仰视视角。
(b). 多照明:高动态范围是DVS传感器最重要的特点之一,因此,我们在强光、中光和低光情况下收集了视频。请注意,每个类别中有60%的视频是低光条件下录制的。我们的数据集还包含许多具有闪烁光的视频,因为我们发现DVS传感器对闪烁光特别敏感,尤其是在夜间。
(c). 多运动:我们还通过记录许多不同运动速度的动作来突出DVS传感器的特点,包括缓慢、适中和高速。
(d). 动态背景:识别没有背景物体的动作相对容易,即固定的DVS摄像机,因此我们还收集了许多具有动态移动摄像机的动作,以使我们的数据集具有足够的挑战性。
(e). 遮挡:在现实世界中,人类动作通常会被遮挡,这种挑战也考虑在我们的数据集中。
数据收集和统计分析:HARDVS数据集是使用分辨率为346×260的DAVIS346摄像头收集的。在数据收集阶段共有五名参与者。从统计的角度来看,我们的数据集包含了共计107,646个视频序列和300个常见人类活动类别。我们将每个类别的60%、10%和30%分别用于训练、验证和测试。因此,训练、验证和测试子集中的视频数量分别为64526、10734和32386。基于上述特点,我们相信我们的HARDVS数据集将成为神经形态分类问题的更好评估平台,特别是对于人类活动识别任务。
方法
概述
在本节中,我们设计了一种新的基于事件的空间-时间变换器(ESTF)方法,用于事件流数据的学习。如图3所示,所提出的ESTF架构包含三个主要的学习模块,即i)初始空间和时间嵌入,ii)空间和时间增强学习,以及iii)空间-时间融合变换器。具体而言,给定输入的事件流数据,我们首先分别提取初始的空间和时间嵌入。然后,设计了一个空间和时间特征增强学习模块,通过深度捕捉事件流的空间相关性和时间依赖性,进一步丰富事件流数据的表示。最后,设计了一个有效的融合变换器(FusionFormer)模块,将空间和时间线索整合在一起,用于最终的特征表示。下面介绍这些模块的详细内容。
初始空间和时间嵌入
与基于帧的传感器不同,每次事件摄像头以异步方式捕捉log-scale中的强度变化。换句话说,当视觉变化超过预定义的阈值时,每个像素都会独立输出一个离散事件(或脉冲)。通常,我们使用一个4元组{x,y,t,p}来表示用DVS捕获的像素的离散事件,其中x、y是空间坐标,t是时间戳,p ∈ {1,-1}是亮度变化的极性。按照以前的工作(Wang等人,2019b;Zhu和Yuan,2018;Fang等人,2021;Yao等人,2021),我们首先通过在时间间隔内堆叠事件来将异步事件流转换为同步事件图像,基于曝光时间。令为采样输入事件帧的集合。根据现有工作(Tran等人,2015),我们在实验中设定T = 8。对于每个事件帧Et,我们采用StemNet(在我们的实验中选择ResNet-18(He等人,2016))来提取其初始CNN特征描述符,并将
作为T个事件帧的集合。基于此,我们分别提取空间和时间嵌入。具体而言,对于时间分支,我们采用卷积层来减少特征大小以获取
,并将其重塑为矩阵形式,如
,其中
。对于空间分支,我们首先采用卷积层来将特征X调整大小为
,其中
。然后,我们在时间维度上进行合并/求和操作,并将其重塑为矩阵形式
,其中
。因此,空间和时间嵌入均具有相同的d维特征描述符。
空间和时间增强学习
基于上述初始空间嵌入 和时间嵌入
,我们设计了空间和时间增强学习(STEL)模块,以进一步丰富它们的表示。所提出的STEL模块包括两个子模块,即空间变换器(Spatial Transformer,SF)模块和时间变换器(Temporal Transformer,TF)模块,分别捕获事件数据的空间相关性和时间依赖性,以学习上下文丰富的表示。SF模块包括多头自注意力(MSA)和MLP模块,两个模块之间使用LayerNorm(LN),同时还采用了残差连接,如图3所示。具体而言,给定空间嵌入
,我们首先将位置编码(Dosovitskiy等人,2020)整合到其中,得到表示N个输入标记的
,其具有d维特征描述符。然后,SF模块的输出总结如下,
与输入 相比,输出
利用MSA机制对不同事件块的空间关系进行建模,提供了空间感知增强表示。类似地,给定表示T个时间标记的
,TF模块的输出总结如下,
与输入相比,输出
利用MSA机制对不同帧标记的依赖关系进行建模,提供了时间上下文增强表示。
融合Transformer
为了在上述空间和时间模块之间进行交互,并学习统一的时空上下文数据表示,我们还设计了一个融合变换器(Fusion Transformer)模块。具体而言,让 和
分别表示先前 SF 和 TF 模块的输出。我们首先将 N 个空间标记和 T 个时间标记收集在一起,然后将它们输入到一个统一的变换器块中,其中包括多头自注意力(MSA)和 MLP 子模块,即
随后,我们将分成
,其中
和
,并进一步使用上述 SF(公式(1,2))和 TF(公式(3,4)) 模块来分别增强它们的表示,如下所示,
最后,我们将和
连接在一起,并将连接后的特征重塑为向量形式。然后,我们使用一个两层 MLP 来输出最终的类别标签预测,如图3所示。
损失函数
我们提出的ESTF框架可以以端到端的方式进行优化。采用标准的交叉熵损失函数来衡量我们模型预测与实际情况之间的距离,如下所示:
其中,B 表示批大小,N 表示事件类别的数量。Y 和 P 分别代表事件样本的实际类别标签和预测类别标签。
实验
数据集和评估指标
在这项工作中,我们采用了三个数据集来评估我们提出的模型,包括N-Caltech101(Orchard等人,2015年),ASL-DVS(Bi等人,2020年)以及我们新提出的HARDVS。关于这些数据集的更多细节可以在表1中找到。常用的top-1和top-5准确度被采用作为评估指标。
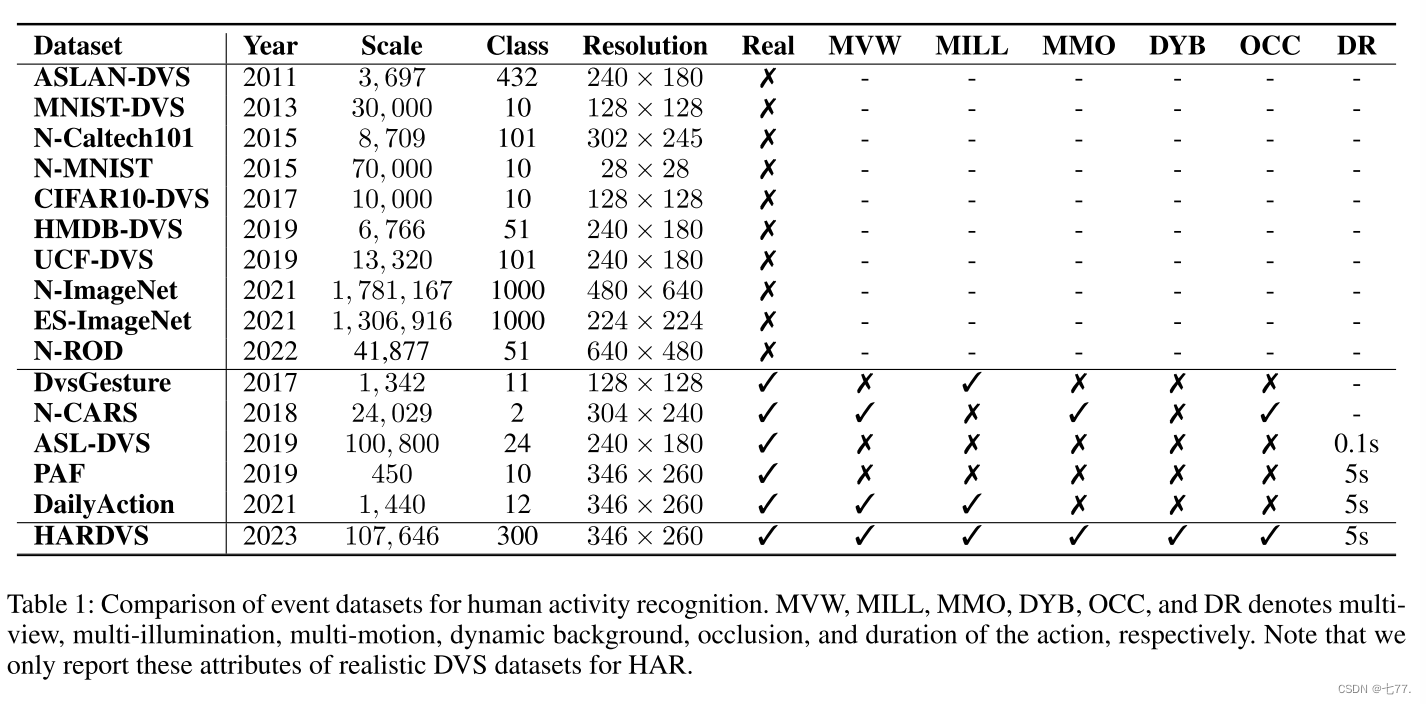
表1:用于人类活动识别的事件数据集比较。MVW、MILL、MMO、DYB、OCC和DR分别表示多视角、多光照、多动作、动态背景、遮挡和动作持续时间。请注意,我们仅报告用于HAR的真实DVS数据集的这些属性。
与SOTA算法的比较
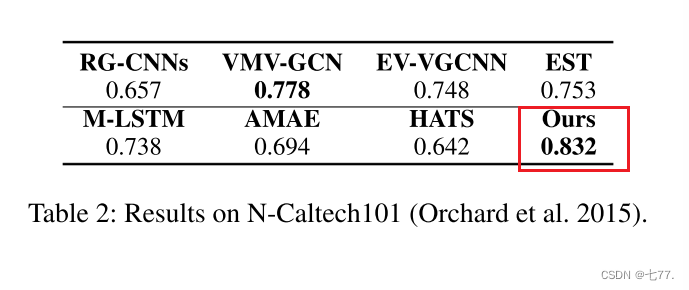
在N-Caltech101数据集上的结果(Orchard等人,2015)。如表2所示,我们提出的方法在top-1准确率指标上达到了0.832,远远优于其他模型。例如,VMV-GCN在这个基准数据集上达到了0.778,排名第二,而我们的模型则比它高出了5.4%。M-LSTM是一种自适应事件表示学习模型,仅在这个数据集上获得了0.738。EV-VGCNN是一种基于图神经网络的模型,其准确率为0.748,也比我们的模型差。这些实验结果充分证明了我们提出的基于时空特征学习的事件模式识别的有效性。
在ASL-DVS数据集上的结果(Bi等人,2020)。如表3所示,该数据集上的性能已经接近饱和,大多数比较的模型在top-1准确率上均达到了0.95+以上。值得注意的是,VMV-GCN(Xie等人,2022)在这个基准数据集上达到了0.989的准确率,排名第二。由于我们提出的时空特征学习和融合模块,我们在这个数据集上取得了新的最先进性能,即top-1准确率为0.999。因此,我们可以得出结论,我们的方法几乎完全解决了ASL-DVS中定义的简单手势识别问题。

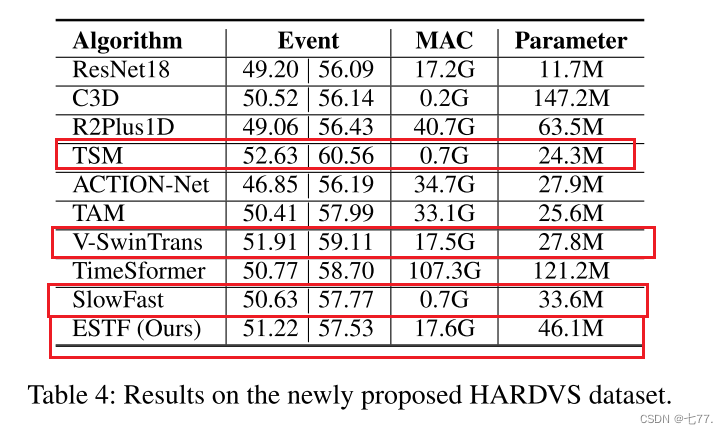
HARDVS数据集的结果。从ASL-DVS(Bi等人,2020)和N-Caltech101(Orchard等人,2015)中报告的实验结果中,我们可以发现现有的基于事件的识别数据集几乎已经饱和。新提出的HARDVS数据集可以填补这一空白,并进一步推动基于事件的人体动作识别的发展。如表4所示,我们重新训练和测试了多个最新模型,供未来的工作在HARDVS基准数据集上进行比较,包括C3D(Tran等人,2015)、R2Plus1D(Tran等人,2018)、TSM(Song等人,2019)、ACTION-Net(Wang、She和Smolic,2021)、TAM(Liu等人,2021b)、Video-SwinTrans(Liu等人,2021a)、TimeSformer(Bertasius、Wang和Torresani,2021)、Slow-Fast(Feichtenhofer等人,2019)。很容易发现,这些流行且强大的识别模型在我们新提出的HARDVS数据集上性能仍然较差。具体来说,R2Plus1D(Tran等人,2018)、ACTION-Net(Wang、She和Smolic,2021)和SlowFast(Feichtenhofer等人,2019)仅在top-1和top-5准确率上分别达到了49.06|56.43、46.85|56.19和50.63|57.77。最近提出的TAM(Liu等人,2021b)(ICCV-2021)、Video-SwinTrans(Liu等人,2021a)(CVPR-2022)和TimeSformer(Bertasius、Wang和Torresani,2021)(ICML 2021)在这两个指标上分别达到了50.41|57.99、51.91|59.11和50.77|58.70。与这些模型相比,我们提出的时空特征学习和融合模块表现与这些SOTA模型相当甚至更好,即51.22|57.53。这是因为我们提出的时空特征增强模块在捕捉事件流中的运动线索方面表现良好。总的来说,我们提出的模型对于基于事件的人体动作识别任务是有效的,并且可能是未来工作进行比较的良好基线。
消融实验
组件分析
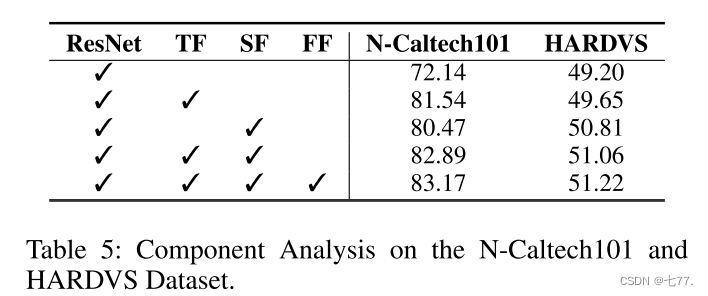
如表5所示,我们在N-Caltech101和HARDVS数据集上对三个主要模块进行了分析,包括SpatialFormer(SF)、TemporalFormer(TF)和FusionFormer。对于N-Caltech101,我们发现我们的基准方法ResNet18(He等,2016年)在top-1准确度指标上达到了72.14。当引入TemporalFormer(TF)到识别框架中时,整体性能可以显著提高+9.4,达到81.54。当采用SpatialFormer(SF)进行长距离全局特征关系挖掘时,识别结果可以提高到80.47,改善了+8.33。当两个模块都用于联合空间-时间特征学习时,可以获得更好的结果,即82.89。如果采用FusionFormer来实现空间和时间Transformer分支之间的交互式特征学习和信息传播,则可以获得最佳结果,即top-1准确度为83.17。类似的结论也可以从HARDVS数据集的实验结果中得出。根据表5和表2的实验分析,我们可以得出结论,我们提出的各个模块都对最终的识别结果有贡献。
关于输入帧数的分析
在本文中,我们将事件流转换为类似图像的表示进行分类。在我们的实验中,采用了8帧来评估我们的模型。实际上,可以使用不同时间窗口间隔获取各种事件帧。在这部分中,我们在N-Caltech101数据集上测试了4、6、8、10、12和16帧的模型,并在图5中报告了结果。很容易发现,平均准确率分别为73.67、75.94、77.37、73.49、75.11和73.03,并且当采用8帧时可以获得最高的平均准确率。对于帧数大于8时准确率下降的情况,我们认为这可能是由于事件流被分割成更多帧,每帧将更加稀疏所导致的。因此,这将导致稀疏的边缘信息,这对于识别非常重要。

分析空间数据的分割块大小
在这篇论文中,空间特征被划分为非重叠的块。在本小节中,我们测试了多个尺度,包括8×8、6×6和4×4。如图5(右侧)所示,当采用4×4时可以获得最佳性能,即在top-1、top-5和平均准确率上分别为83.17、94.20和77.37。
分析Transformer层的层数
我们都知道,自注意力或Transformer层可以堆叠多次以实现更准确的识别,这在许多研究中得到了验证。在这个实验中,我们还测试了不同的Transformer层数,以检查它们对我们模型的影响。如图5(中)所示,我们测试了四种不同的设置,即1、2、3和4层,相应的平均准确率为77.37、75.20、76.05和74.64。我们可以发现,当Transformer设置为1到3层时,可以获得更高的识别结果。也许需要更大的数据集来训练更深层的Transformer。
模型参数和运行效率
我们的模型检查点占用的存储空间为377.34 MB,参数数量为46.71 M。使用工具包ptflops 2测试得到的MAC为17.62 G。在配备GPU RTX-3090的服务器上,我们的模型在我们提出的HARDVS数据集中每个视频(使用了8帧)耗时25毫秒。
可视化
如图4(a,b)所示,我们选择了HARDVS数据集中定义的10类动作,并使用tSNE工具包将它们投影到2D平面上进行特征可视化。很容易发现,使用基线ResNet18时部分数据样本的区分效果不佳,例如蓝色边界框中突出显示的区域。相比之下,我们提出的ESTF模型实现了更好的特征表示学习,更多类别被正确分类。对于N-Caltech101数据集的混淆矩阵,如图4(c,d)所示,我们可以发现我们提出的ESTF与基线ResNet18相比取得了显著改进。总的来说,我们可以得出结论,我们提出的空间-时间特征学习方法对基于事件的动作识别效果良好。
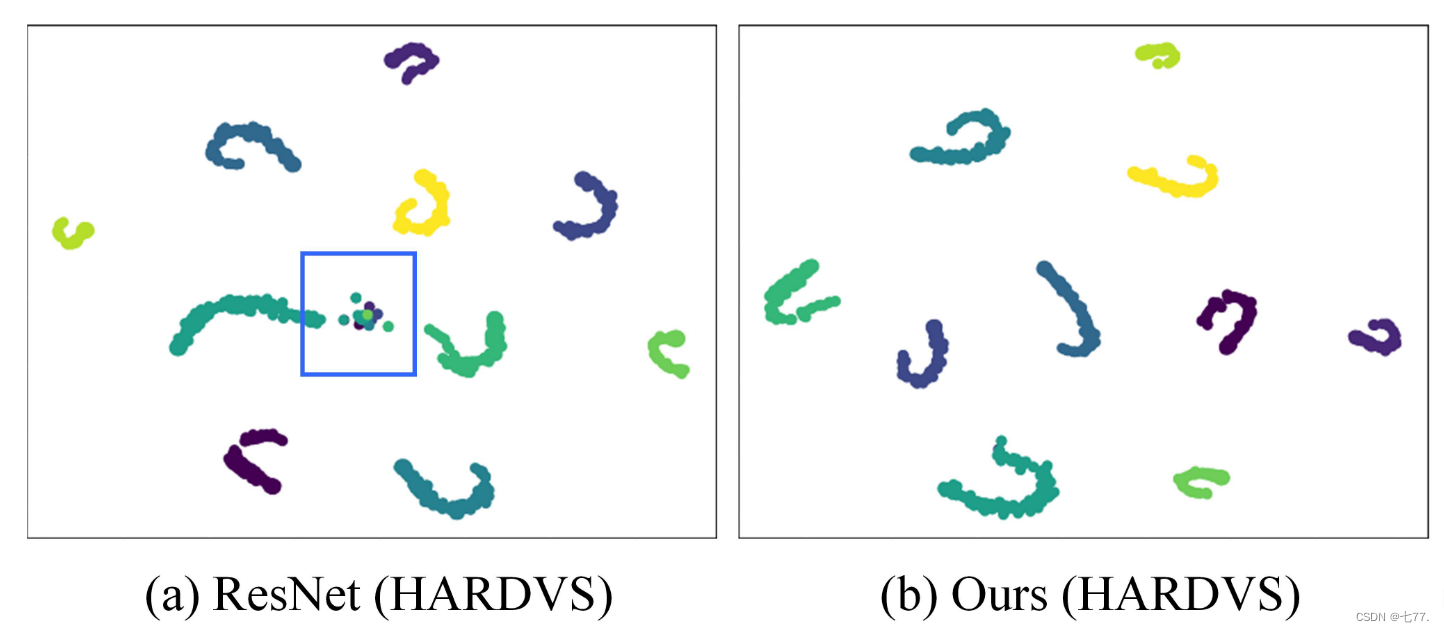

图4:基线模型和我们新提出的ESTF在HARDVS数据集上特征分布的可视化(a,b),以及基线ResNet和我们模型在N-Caltech101数据集上的混淆矩阵(c,d)。最好通过放大查看。
结论
在本文中,我们提出了一个用于基于事件的人体动作识别的大规模基准数据集,称为HARDVS。它包含300种人类活动类别,以及从DAVIS346相机捕获的100K多个事件序列。这些视频反映了各种视角、光照、运动、动态背景、遮挡等情况。我们评估了超过10种流行和最新的分类模型,以便未来的研究进行比较。此外,我们还提出了一种新颖的基于事件的时空转换器(简称为ESTF),用于进行空间-时间增强学习和融合,以实现准确的动作识别。对多个基准数据集的广泛实验验证了我们提出的框架的有效性。它在N-Caltech101和ALS-DVS数据集上取得了新的SOTA性能。我们希望所提出的数据集和基准方法能够推动基于事件相机的人体动作识别的进一步发展。
读后总结
个人认为这篇论文并没有很大的创新点,主要是抓住事件摄像头的数据为出发点,针对现今事件数据较少的问题,提出一个用于基于事件的人体动作识别的大规模基准数据集(个人认为这是最大的贡献),然后提出一个基于事件的时空转换器模型(ESTF),然而这个模型在实验部分只在之前现有的N-Caltech101和ASL-DVS两个数据集上达到了SOTA,但是该模型在论文中提出的HARDVS数据集中却比没有达到SOTA水平(似乎提出的ESTF模型对于提出的数据集并没有针对性的研究,这是否归结于模型中的SF、TF、融合模块的内部结构都基本一致导致(均为Vision Transformer模块结构),整个模型的结构也比较常规,是否可以在这些结构中进行改进来提高模型的性能?)

这篇关于HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







