本文主要是介绍photomaker:customizing realistic human photos via stacked id embedding,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PhotoMaker: 高效个性化定制人像照片文生图 - 知乎今天分享我们团队最新的工作PhotoMaker的技术细节。该工作开源5天Githubstar数已过6千次,已列入Github官方Trending榜第一位,PaperswithCode热度榜第一位,HuggingFace Spaces趋势榜第一位。项目主页在: PhotoMa…![]() https://zhuanlan.zhihu.com/p/680468694https://huggingface.co/spaces/TencentARC/PhotoMaker
https://zhuanlan.zhihu.com/p/680468694https://huggingface.co/spaces/TencentARC/PhotoMaker![]() https://huggingface.co/spaces/TencentARC/PhotoMaker相当于把以前串联型保ID项目,比如facechain和easyphoto的数据处理提前了,给了sd更好的特征维度。
https://huggingface.co/spaces/TencentARC/PhotoMaker相当于把以前串联型保ID项目,比如facechain和easyphoto的数据处理提前了,给了sd更好的特征维度。

定制化生成,dreambooth允许用户输入少量的待定制目标的图像,配合文本控制就可以生成该目标不同动作或者不同场景的图像。


DreamBooth的算法流程非常简单,主要分为了两个阶段。第一阶段,准备数张待定制目标的图像配合对应的触发词一同送入预训练的扩散模型中进行微调(Finetuning)。第二阶段,用户可以在文本中加入相应的触发词进行定制化目标的生成。由于DreamBooth一般需要对扩散模型中去噪器的所有参数进行上千次迭代步数的微调,整个流程非常消耗时间,往往需要花费约数十分钟时间。消耗的计算资源和存储资源都很大。因此一些工作尝试减少DreamBooth需要微调的参数。
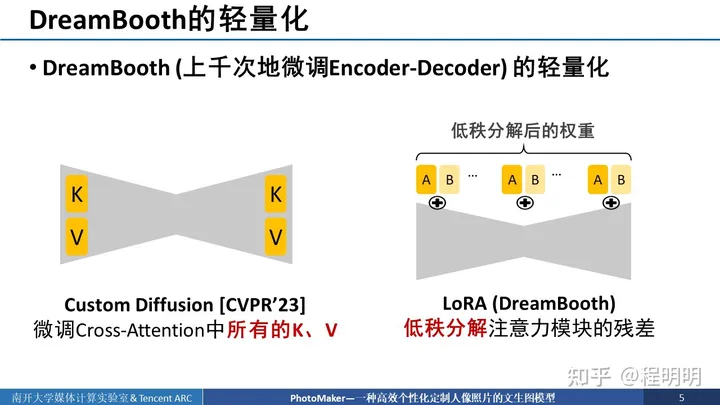
这些工作包括了:1)CVPR23的Custom Diffusion,其只需要微调去噪器的cross-attention中所有的k和v就可以实现定制化生成。以及2)社区中出现的基于LoRA的方式,该方式只需要微调低秩分解后的注意力模块的残差。不仅微调的参数量变少了、消耗的资源更少了、速度变快了,他们还可以达到比DreamBooth更好的效果。

但是,以上的这些基于DreamBooth+LoRA的人像定制应用都有三个资源采集和消耗上的痛点:
1. 定制时间慢:由于需要在“测试”(定制)阶段对模型进行微调,理论上消耗的时间往往需要大约15分钟,在一些商业化的APP上,由于资源分配和排队的问题这一定制时间甚至要更久(数小时到数天)。
2. 消耗显存高:如果不进行额外的优化,在SDXL底模上执行定制化过程只能在专业级显卡上进行,这些专业级显卡的昂贵都是出了名的。
3. 对输入素材要求高:以妙鸭举例,它要求用户输入20张以上高质量的人像照片,且每次定制过程都需要重新进行收集。对用户来说非常不友好。
因此,我们希望设计一个算法,它无需在“测试”(定制)阶段进行训练,只需要一次前向过程,就可以在10秒左右进行定制化生成。与此同时,这个算法可以在消费级显卡上运行,并且只需要用户少量(1-3)张不对质量有要求的图像。




我们的解决方案也非常简单,如图所示,首先,我们希望在训练时,我们的输入图像和输出的目标图像都不来源于同一个图像。其次,我们希望送入多个同一ID的图像提取embedding以得到对输出ID的一个全面且统一的表达。这个embedding我们将它命名为Stacked ID embedding。Stacked ID embedding中存取的每个embedding它们的图像来源可能姿态不同,表情不同以及配饰不同,但ID都是相同的,因此可以隐式的将ID与其他与ID无关的信息解耦,以使其只表征待输出的ID信息。依赖于Stacked ID embedding我们提出了PhotoMaker。

PhotoMaker可以在用户输入少量图像的前提下,生成待定制ID的图像并根据prompt进行上下文的改变。我们还可以改通过简单的改变触发词,改变待定制人物的年龄和性别。就比如说我们可以生成Hinton小时候带上博士帽的照片。



身份混合
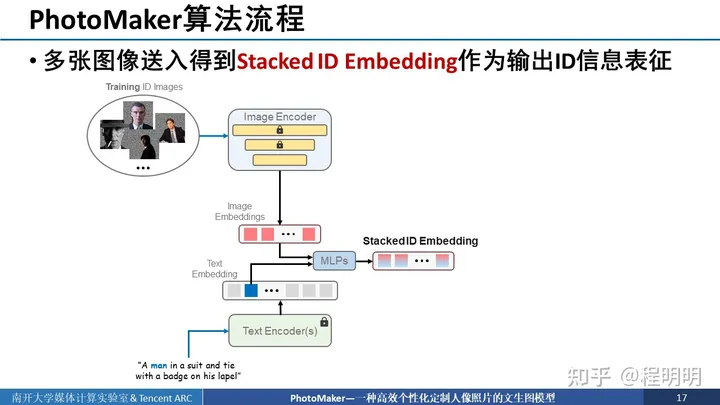
接下来我们详细介绍我们的算法流程,核心思想就是通过多张图像送入这个框架中得到stack ID embedding作为输出ID的信息表征。具体来说,首先我们准备好同一ID的多个图像并把最与ID信息无关的背景mask掉。然后将这些同一ID的多个图像送入图像编码器中进行编码,得到多个image embedding。如果我们有4个输入图像,那就有4个image embedding。我们同时使用text encoder将输入的文本进行编码,并且找出触发词(待定制目标的类别词)对应的编码后位置。使用该位置的text embedding与image embedding通过MLP一一进行混合得到stacked ID embedding,stacked ID embedding中emebdding的数量仍与输入图像数量一致。
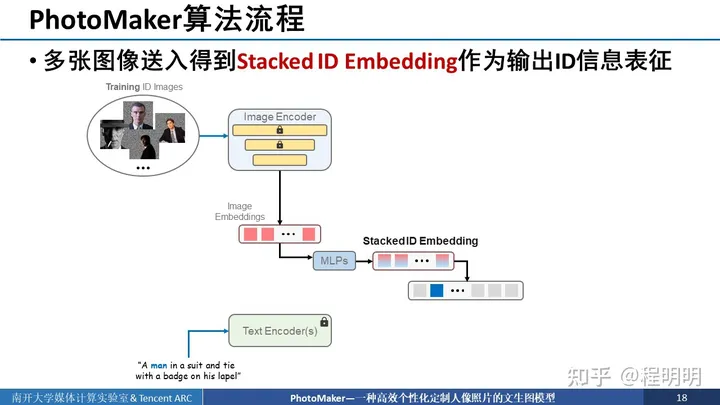
我们将得到的stacked ID embedding与text embedding中对应位触发词位置的embedding进行替换,进而得到更新后的text embedding。
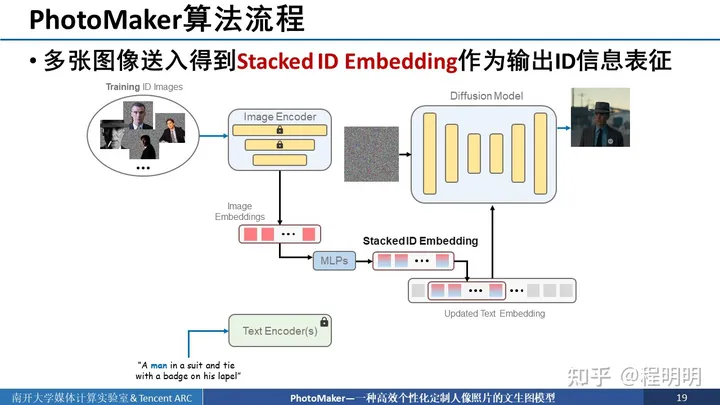
我们将更新后的text embedding放入diffusion model中,通过cross attention层进行融合。此外,我们还在每一个注意力层中添加了LoRA模块进行更新。
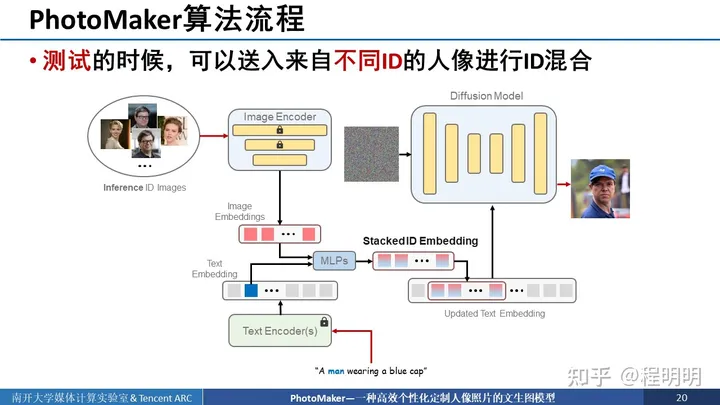
在测试阶段,我们可以使用来自不同ID的人像进行ID融合,就比如说我们可以送入2张LeCun的头像和2张斯佳丽的头像,以生成长得像LeCun的斯嘉丽。需要注意的是。送入的图像背景可以不需要被mask遮住。

接下来我们介绍以ID为中心的数据组装流程。为什么需要这个流程呢?是因为现有的数据集无法支持训练我们的PhotoMaker.因为第一,许多数据集不以ID进行分类,比如说LAION和FHHQ等,第二,以ID分类的数据集只关注人脸区域,比如CelebA-HQ以及一些用于人脸检测的数据集等。我们希望组建一个数据准备流程,通过这个流程,可以得到一个数据集,其以ID进行分类,且每一个ID都有多张以人物为主体的图像。
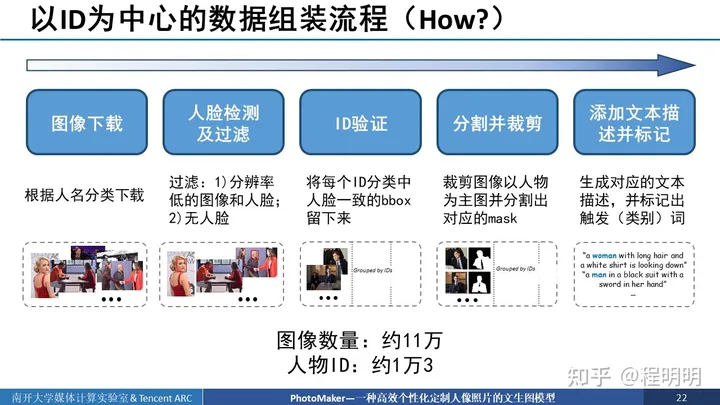
具体来说,我们首先根据人名的列表对人物图像进行分类下载,然后每个文件夹中包含了多个同一ID的图像。接着我们对图像的质量进行过滤,过滤掉分辨率低的图像和人脸以及没有人脸的图像。由于每一个文件夹中包含了可能不属于同一ID的图像,那么我们需要进行ID的验证,就是将每个ID分类中人脸一致的bounding box留下来。在进行完ID验证后,我们筛选出了同一ID的bounding box和图像。然后我们对筛选出的图像进行裁剪以使人物为主体,与此同时,分割出当前ID对应的mask,以方便训练时使用。我们给每个图像都生成对应的文本描述。并标记出对应的触发词即类别词。





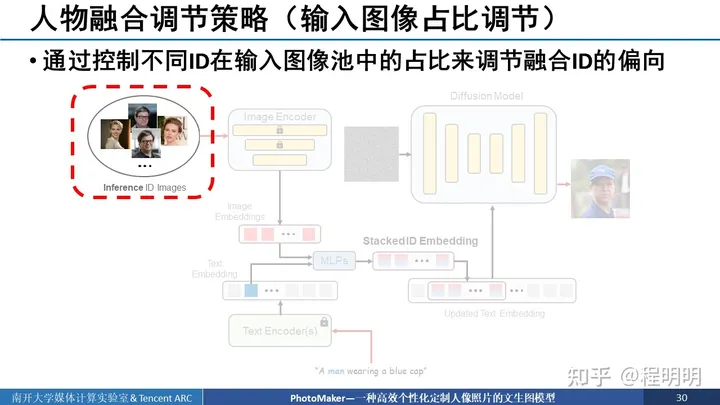
接下来我们展示两种我们方法进行人物融合的调节策略以展示我们方法的灵活性。第一种是我们可以控制不同ID在输入图像池中的占比来调节融合ID的偏向。比如说,我们可以让LeCun的照片在输入图像池中占比更多一些,以使生成的图像更像LeCun,反之亦然。

在接下来两个例子中,我们可以看到,我们的方法可以控制奥巴马和或者拜登在整个输入图像池中的占比,来控制输入输出的ID更像奥巴马还是更像拜登。其中,50%的意思就是输入的10张图像中5张图像是奥巴马5张图像是拜登。可以看到随着奥巴马的占比更多,生成的ID更像奥巴马,反之更像拜登。可以看到这个变化是非常平滑的。再者,就是斯佳丽和奥巴马夫人进行混合的例子,可以看到发色、肤色等有都有一个平滑的过渡。

第二种人物融合调节策略,就是通过prompt weighting来调节。具体来说就是通过控制不同ID在stack ID embedding中的权重来调节融合ID的偏向。就比如说我要使输出图像长得更像LeCun,就把LeCun对应的embedding权重调大一些。而长得更像斯佳丽,就把斯佳丽对应的embedding的权重调大一些。

接下来的例子中我们可以看到,我们固定这个拜登对应的embedding权重为1.0,调大奥巴马的对应的embedding的权重,可以看到图像长得会更加像奥巴马。在安妮海瑟薇的例子中可以看到,随着这个Elsa公主的权重调大,她的发色和服装以及背景都有相应的平滑改变。

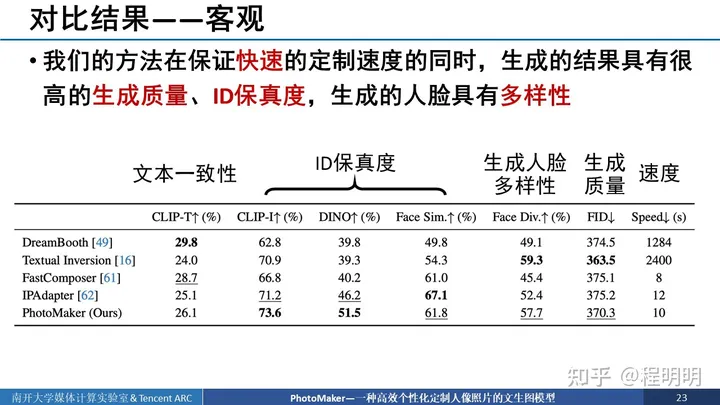
我们文章的核心观点就是通过多个图像的ID嵌入得到stacked ID embedding。如果我们送入更多的图像,得到更多的embedding,会带来怎样的增益呢?首先是客观指标展示,所有有关ID保真度的指标,随着输入的图像增多都增加了,但是文本一致性降低了。

在视觉结果展示中可以看到,我们在输入一张图像时输出的图像不像拜登或斯嘉利,但是随着输入图像增多,输出的图像会长得更加像拜登和斯嘉丽。对于强森,我们输入prompt是“一个女人的照片”,那可以看到,刚开始他还是有女性的特征的,但随着输入图像增多,虽然更像强森了但输出ID的男性特征越来越明显。


代码:
pipe = PhotoMakerStableDiffusionXLPipeline.from_pretrained(base_model_path,...)
pipe.load_photomaker_adapter(ckpt)->
- id_encoder = PhotoMakerIDEncoder()->CLIPVisionModelWithProjection
-- visual_projection_2 = nn.Linear(1024,1280,bias=False)
-- fuse_module = FuseModule(2048)
- id_encoder.load_state_dict(state_dict(['id_encoder']))
- id_image_processor = CLIPImageProcessor()
- load_lora_weights(state_dict['lora_weights'],adapter_name="phototmaker")
- self.tokenizer_2.add_tokens([trigger_word],special_tokens=True)
pipe.scheduler = EulerDiscreteScheduler.from_config()
pipe.fuse_lora()generate_image()->
input_ids = pipe.tokenizer.encode(prompt)->
output_w, output_h = aspect_ratios[aspect_ratio_name]->
prompt, negative_prompt = apply_style(style_name, prompt, negative_prompt)->
generator = torch.Generator(device=device).manual_seed(seed)->images = pipe(prompt=prompt,width=output_w,height=output_h,input_id_images=input_id_images,negative_prompt=negative_prompt,num_images_per_prompt=num_outputs,num_inference_steps=num_steps,start_merge_step=start_merge_step,generator=generator,guidance_scale=guidance_scale,).images->
- 1.check inputs->self.check_inputs()
- 3.encode input prompt->prompt_embeds = self.encode_prompt_with_trigger_word()->
- 4.encode input prompt without the trigger word for delayed conditioning encode,remove trigger word token,then decodetokens_text_only = self.tokenizer.encode(prompt, add_special_tokens=False)trigger_word_token = self.tokenizer.convert_tokens_to_ids(self.trigger_word)tokens_text_only.remove(trigger_word_token)prompt_text_only = self.tokenizer.decode(tokens_text_only, add_special_tokens=False)
(prompt_embeds_text_only,negative_prompt_embeds,pooled_prompt_embeds_text_only, # TODO: replace the pooled_prompt_embeds with text only promptnegative_pooled_prompt_embeds,
) = self.encode_prompt(prompt=prompt_text_only,prompt_2=prompt_2,device=device,num_images_per_prompt=num_images_per_prompt,do_classifier_free_guidance=do_classifier_free_guidance,negative_prompt=negative_prompt,negative_prompt_2=negative_prompt_2,prompt_embeds=prompt_embeds_text_only,negative_prompt_embeds=negative_prompt_embeds,pooled_prompt_embeds=pooled_prompt_embeds_text_only,negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,)
- 5. Prepare the input ID images
id_pixel_values = id_pixel_values.unsqueeze(0).to(device=device, dtype=dtype) # TODO: multiple prompts
- 6. Get the update text embedding with the stacked ID embedding,标识词和image mlp融合,再和text_prompt_encode组合
prompt_embeds = self.id_encoder(id_pixel_values, prompt_embeds, class_tokens_mask)
- 7. prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
- 8. prepare latent variables
latents = self.prepare_latents(batch_size * num_images_per_prompt,num_channels_latents,height,width,prompt_embeds.dtype,device,generator,latents,)
- 10. Prepare added time ids & embeddingsif self.text_encoder_2 is None:text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])else:text_encoder_projection_dim = self.text_encoder_2.config.projection_dimadd_time_ids = self._get_add_time_ids(original_size,crops_coords_top_left,target_size,dtype=prompt_embeds.dtype,text_encoder_projection_dim=text_encoder_projection_dim,)add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
-11.
....
这篇关于photomaker:customizing realistic human photos via stacked id embedding的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






