本文主要是介绍视频行人搜索 (Person Search in Videos),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 视频行人搜索 (Person Search in Videos)
- 图像行人搜索
- 存在问题
- Video PS 定义
- MTA-PS数据集
- First person search dataset in videos
- Complicated ambient conditions and realistic monitoring scenarios
- Privacy insensitivity
- 方法
视频行人搜索 (Person Search in Videos)
MTA-PS: TOWARDS PRACTICAL PERSON SEARCH IN VIDEOS论文已被 ICIP2024 接收。
代码地址:MTA-PS
论文和数据集链接将会更新。
图像行人搜索
Person Search(行人搜索,PS)旨在从自然的、未经裁剪的图像中同时定位和识别目标人物。
存在问题
-
图像与现实的差距:现有的PS数据集和研究工作大多基于个人图像,在现实世界中的监控场景实用性有限。尽管行人搜索在两个广泛使用的数据集(即 CUHK-SYSU 和 PRW)上取得了显着进展,但它们都仅由图像组成,导致与现实世界视频监控场景的偏差,以及在实际视频监控系统中需要克服更多挑战。
-
视频相对图像的优势:与静态图像相比,视频提供额外的时间信息,可以更好的克服遮挡形变等图像难以解决的问题,使从视频中搜索目标人物的轨迹更真实、更准确。
-
视频数据集的缺失:为了促进视频行人搜索的发展,数据集需要提供全面的GT,特别是在所有摄像机上一致的id。这样的数据不仅难以注释,而且可能违反当前或未来的数据保护权利。例如,杜克大学在2014年提出的一个流行的数据集DukeMTMC作为校园监控视频数据集,在2019年因隐私问题而被禁用。
Video PS 定义
给定目标人的查询图像,我们的目标是搜索目标人物在视频图库中出现的位置,并获得目标人物沿视频序列的完整时间轨迹。
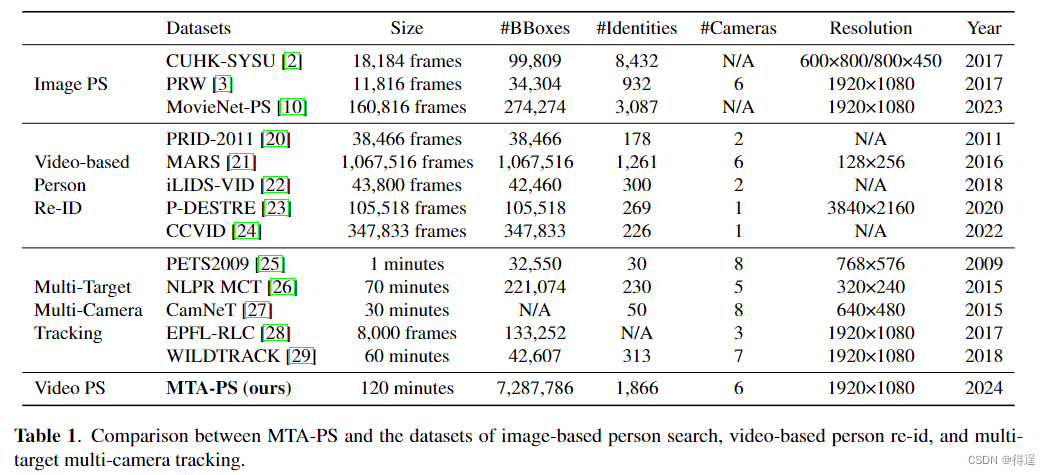
MTA-PS数据集
一个标准的基于视频的人物搜索数据集应该满足以下要求:首先,这些摄像机应该在同一个大场景中,摄像机之间有一些重叠。其次,我们需要确保绝大多数人至少出现在两个摄像头中。通过这种方式,我们可以为出现在多个摄像机中的每个人从其中一个摄像机中选择一个帧作为查询。

First person search dataset in videos
在这里,我们介绍一个新的数据集,名为MTA-PS,这是第一个视频行人搜索数据集。我们的MTA- ps数据集是基于一个大规模的虚拟数据集MTA中的视频帧和身份标签构建的。MTA数据集记录在侠盗猎车手5 (GTA5)虚拟世界的一小部分,提供了高度的真实感和细节。
Complicated ambient conditions and realistic monitoring scenarios
因此,我们新引入的MTA-PS数据集包含295.2K图像帧,7.2M边界框和1.8K身份,这些图像帧来自6台摄像机和41 FPS的60个视频。MTA-PS考虑了重叠和非重叠摄像机、夜间和白天、室内和室外区域以及不同程度的拥挤,这使得数据集更具挑战性。与现有广泛使用的视频数据集相比,我们的MTAPS数据集在各方面覆盖的多样性程度更高,更具挑战性,更接近实际应用场景,如表1所示。我们将MTA-PS数据集的关键特征总结如下。
Privacy insensitivity
虚拟数据集克服隐私问题。
方法
为了验证视频行人搜索的有效性,并充分利用我们数据集上的时间信息,我们还通过无缝集成人物检测、跟踪和重新识别三个子任务,提出了一个新的框架。
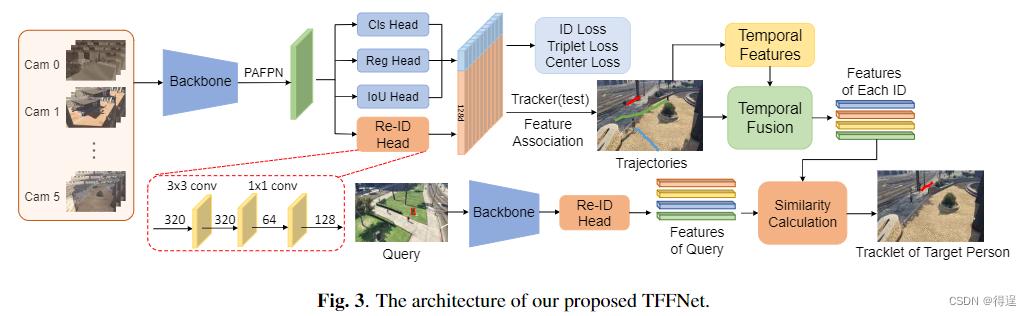
由于性能优异,我们采用了最近提出的ByteTrack作为我们的基网。首先,将由多个视频组成的视频库馈送到主干。然后,分类头、回归头、IoU头和re-ID头共同工作,得到每帧中每个人的边界框和re-ID特征。然后进行数据关联和运动预测,将视频库中的每个行人边界框进行关联,得到每个人的轨迹和相应的特征。同时,保留视频中每个人的时间特征,并与每个人的re-ID特征融合,得到每个人ID对应的特征。然后,我们计算这些特征与查询人特征之间的相似度。最后,从视频库中提取目标人物在不同摄像机下的运动轨迹。
这篇关于视频行人搜索 (Person Search in Videos)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





