行人专题
用opencv的traincascade.exe训练行人的HAAR、LBP和HOG特征的xml文件,并对分类器进行加载和检测
看到一篇论文上讲到可以用adaboost分类器进行行人检测,就想自己动手训练一下分类器,折腾了两周终于训练成功了。。。 opencv中有两个函数可以训练分类器opencv_haartraining.exe和opencv_traincascade.exe,前者只能训练haar特征,后者可以用HAAR、LBP和HOG特征训练分类器。这两个函数都可以在opencv\build\x86\vc10\bin

基于matlab的行人和车辆检测系统
基于matlab的行人和车辆检测系统 【目标检测】基于计算机视觉,含GUI界面 算法:二帧差分法,三帧差分法,混合高斯建模,ViBe算法。 功能:对视频中出现的动态目标进行逐帧作差分析或ViBe算法检测,使运动的行人或汽车与背景分割出来,达到检测目的。 代码结构清晰,含有注释,运算速度快,可扩展。 项目介绍:基于MATLAB的行人和车辆检测系统 项目概述 随着智能监控技术的发展,行人
基于yolov8的行人跌倒检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的行人跌倒检测系统是利用先进的深度学习技术,特别是YOLOv8模型,来实现高效、准确的行人跌倒行为检测。YOLOv8作为YOLO系列的最新版本,通过改进的网络架构和训练策略,在保持高检测速度的同时,显著提升了检测精度。 该系统首先通过收集并标注大量跌倒行为的数据集,利用YOLOv8模型进行训练,使其能够准确识别视频中的跌倒行为。训练过程中,采用数据增强技术提升模型

OpenCV与AI深度学习 | 基于改进YOLOv8的景区行人检测算法
本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。 原文链接:基于改进YOLOv8的景区行人检测算法 作者:贵向泉,刘世清,李立等 来源:《计算机工程》期刊 编辑:陈萍萍的公主@一点人工一点智能 原文:https://www.ecice06.com/CN/rich_html/10.19678/j.issn.1000-3428.0068125 摘要:针对当前

<数据集>车内视角行人识别数据集<目标检测>
数据集格式:VOC+YOLO格式 图片数量:6470张 标注数量(xml文件个数):6470 标注数量(txt文件个数):6470 标注类别数:1 标注类别名称:['pedestrian'] 序号类别名称图片数框数1pedestrian647029587 使用标注工具:labelImg 标注规则:对类别进行画水平矩形框 图片示例: 标注示例:

行人检测(haar+adaboost 与 hog+SVM)
最近在做行人检测,而最流行,也是最老的两种方法就是haar+adaboost 与 hog+SVM。两种我都尝试了,效果并不如想象的好,所以要想有更好的效果,一是要有预处理,二是要有更大量的正负样本。 下面现总结一下自己应用的 haar+Adaboost 进行的行人检测: 我分别训练了两个分类器,训练数据库均来自NICTA(澳大利亚信息与通讯技术研究中心),用其中的2000张

城市行人感知新方法:基于音频的行人检测与预测
智慧城市的重要组成部分之一是部署传感器技术来监控和控制城市的各种服务和功能。城市使用各种传感器来评估城市服务的提供和获取方式,这有助于缓解瓶颈问题,并提前预警潜在的服务中断。了解城市服务需求的时间和空间变化有助于更好的资源利用、更公平的服务提供以及更大的可持续性和弹性。目前,各种传感器已经部署在城市环境中,特别是在交通领域,也用于监测环境条件、能源、水和废物的流动,以及追踪犯罪活动。
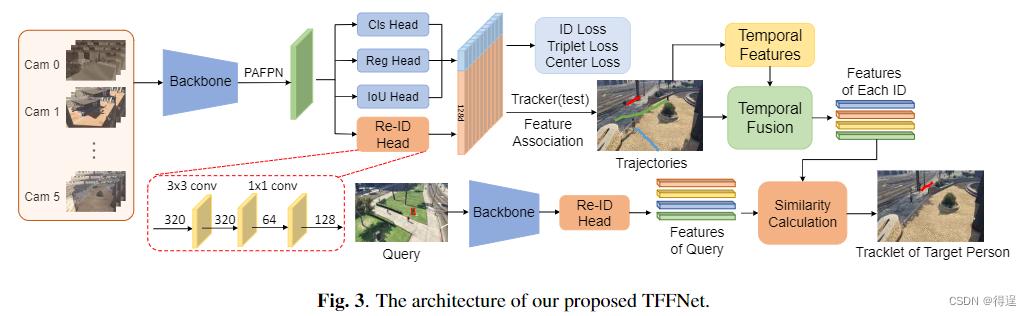
视频行人搜索 (Person Search in Videos)
文章目录 视频行人搜索 (Person Search in Videos)图像行人搜索存在问题Video PS 定义MTA-PS数据集First person search dataset in videosComplicated ambient conditions and realistic monitoring scenariosPrivacy insensitivity 方法

基于YOLO系列算法(YOLOv5、YOLOv6、YOLOv8以及YOLOv9)和Streamlit框架的行人头盔检测系统
摘要 本文基于最新的基于深度学习的目标检测算法 (YOLOv5、YOLOv6、YOLOv8)以及YOLOv9) 对头盔数据集进行训练与验证,得到了最好的模型权重文件。使用Streamlit框架来搭建交互式Web应用界面,可以在网页端实现模型对图像、视频和实时摄像头的目标检测功能,在网页端用户可以调整检测参数(IoU、检测置信度等)。本数据集标注了行人头盔目标,且已转换成YOLO格式的标注文件。本


行人重识别基础系统学习
罗浩 https://zhuanlan.zhihu.com/p/31921944 学习视频 https://www.bilibili.com/video/BV1Pg4y1q7sN?p=12

ReID(BoT)行人重识别
接下来,我会为大家无死角的解析fast-reid(BoT-行人重识别),之前的文章,如下(以下是我工作的所有项目,每一个项目都是,我都做了百分百的详细解读,随着项目增多,为了方便不臃肿,所以给出以下链接)视觉工作项目-为后来的你,提供一份帮助! 我相信,关于fast-reid(BoT)的讲解,我的这一系列博客或许不是国内最早的,但是肯定是最详细的,该网络对应的论文为: Bag of Tricks

###好好好###将 TensorFlow 移植到 Android手机,实现物体识别、行人检测和图像风格迁移详细教程
2017/02/23 更新 贴一个TensorFlow 2017开发者大会的Mobile专题演讲 移动和嵌入式TensorFlow 这里面有重点讲到本文介绍的三个例子,以及其他的移动和嵌入式方面的TF相关问题,干货很多 2017/01/17 更新 今天上 Github,发现 Tensorflow 的 android demo又更新了,除了基本的修改以外,又增加了一个图像风格迁移的安卓


行人检测根据检测结果标注框图
clc; clear; %imgpath='D:\dd\tu\ff\';%图像存放文件夹 imgpath='E:\..\fasterrcnn\testing\image_2\';%图像存放文件夹 txtpath='D:\dd\1.txt';%txt文件 fidin=fopen(txtpath,'r'); while ~feof(fidin) %文件指针到达文件末尾时 该表达
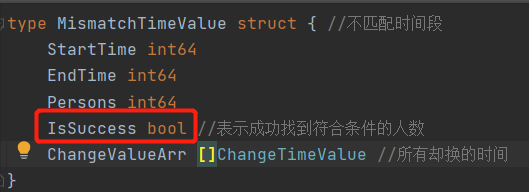
TSINGSEE青犀视频行人检测后端代码出现保存json数据错误的处理
大家知道前段时间我们在某景区内进行了行人检测功能的测试,同时也将这一功能和景区的票务系统进行了对接。当我们将行人分析的结果和景区票务系统的数据进行对比时,后端代码出现保存的json数据错误。Json数据错误是:第一个“Persons”的字段为0(就是人数为0),不应该“ChangeValueArr”有值;而“ChangeValueArr”的数组中有很多要替换的视频源信息(需要替换的人数)。
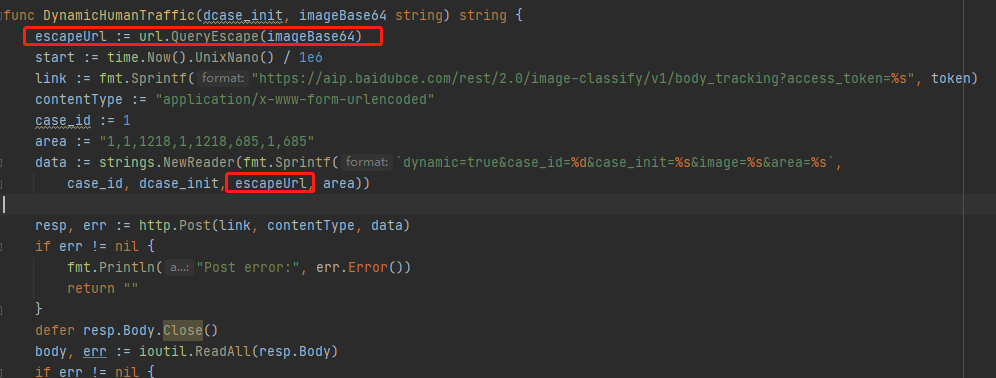
TSINGSEE青犀视频开发景区AI行人识别调用动态行人识别失败问题排查及解决
前段时间我们的景区行人检测功能一直在项目中进行测试,但是检测的AI算法没有达到我们的理想效果,因此我们考虑使用百度AI算法(动态行人识别)来进行调整。在使用GO调用百度AI接口的过程中出现调用失败的情况: 错误信息如下: 此错误的信息表示:传入的图片格式错误。 文档中image传入的是base64编码: 所以是直接传入的base64编码,还验证此编码是否正确(在html中验证)
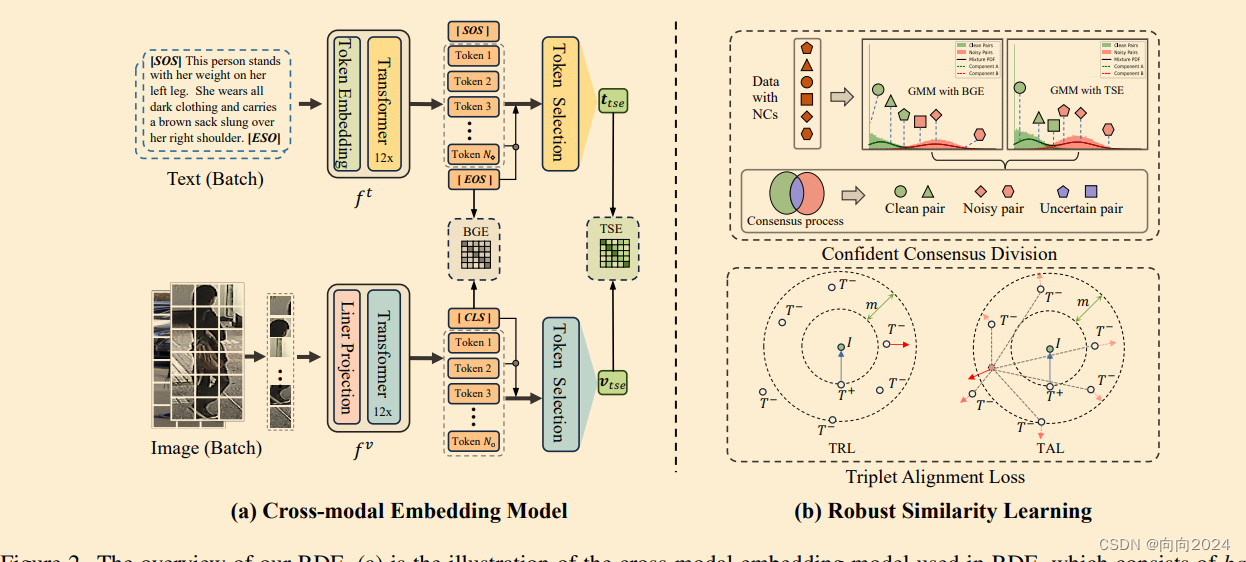
【CVPR2024】文本到图像的行人再识别中的噪声对应学习
这篇论文的标题是《Noisy-Correspondence Learning for Text-to-Image Person Re-identification》,作者是来自中国四川大学、英国诺森比亚大学、新加坡A*STAR前沿人工智能研究中心和高性能计算研究所的研究人员。论文主要研究了文本到图像的行人再识别(Text-to-Image Person Re-identification, TIR

目标跟踪——行人检测数据集
一、重要性及意义 目标跟踪和行人检测是计算机视觉领域的两个重要任务,它们在许多实际应用中发挥着关键作用。为了推动这两个领域的进步,行人检测数据集扮演着至关重要的角色。以下是行人检测数据集的重要性及意义的详细分析: 行人检测数据集的重要性 提供真实世界的样本:行人检测数据集包含了大量从真实场景中捕获的行人图像,这些图像反映了行人在各种条件下的外观和姿态。这使得算法能够在各种实际环境中进行测试和
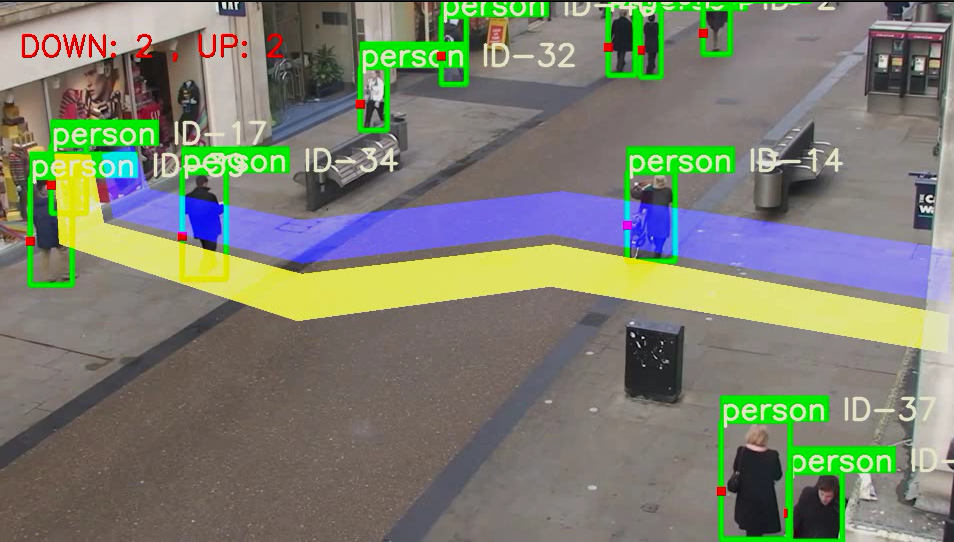
DeepSort行人车辆识别系统(实现目标检测+跟踪+统计)
文章目录 1、前言2、源项目实现功能3、运行环境4、如何运行5、运行结果6、遇到问题7、使用框架8、目标检测系列文章 1、前言 1、本文基于YOLOv5+DeepSort的行人车辆的检测,跟踪和计数。 2、该项目是基于github的黄老师傅,黄老师傅的项目输入视频后,直接当场利用cv2.imshow(),查看识别的结果, 无法当场保存检测完视频,而且无法在服务器上跑,本文实现保

番外篇 | 手把手教你如何用YOLOv8实现行人/车辆等过线统计
前言:Hello大家好,我是小哥谈。目标检测行人/车辆等过线统计是一种常见的视频分析任务,用于统计行人/车辆等在指定区域内过线的次数。这个任务通常需要使用目标检测算法来识别行人/车辆等,并使用计数器算法来统计过线的次数。🌈 目录 🚀1.本文介绍 🚀2.实现步骤
运用YOLOv5实时监测并预警行人社交距离违规情况
YOLO(You Only Look Once)作为一种先进的实时物体检测算法,在全球范围内因其高效的实时性能和较高的检测精度受到广泛关注。近年来,随着新冠疫情对社交距离管控的重要性日益凸显,研究人员开始将YOLO算法应用于社交距离检测,以实现公共场所人员间距的智能化监控。 YOLO社交距离检测系统的核心原理是通过训练过的YOLO模型,如YOLOv3、YOLOv4或YOLOv5,对视频流或图
行人重识别Reid(一):Person_reID_baseline_pytorch
行人重识别Reid(一):Person_reID_baseline_pytorch 文章目录 行人重识别Reid(一):Person_reID_baseline_pytorch前言一、reid 定义1、什么是reid2、reid_baseline 二、准备工作1、环境2、code3、数据 三、训练1、生成训练数据2、开始训练 四、测试1、特征提取2、评测 五、简单的可视化六、总结
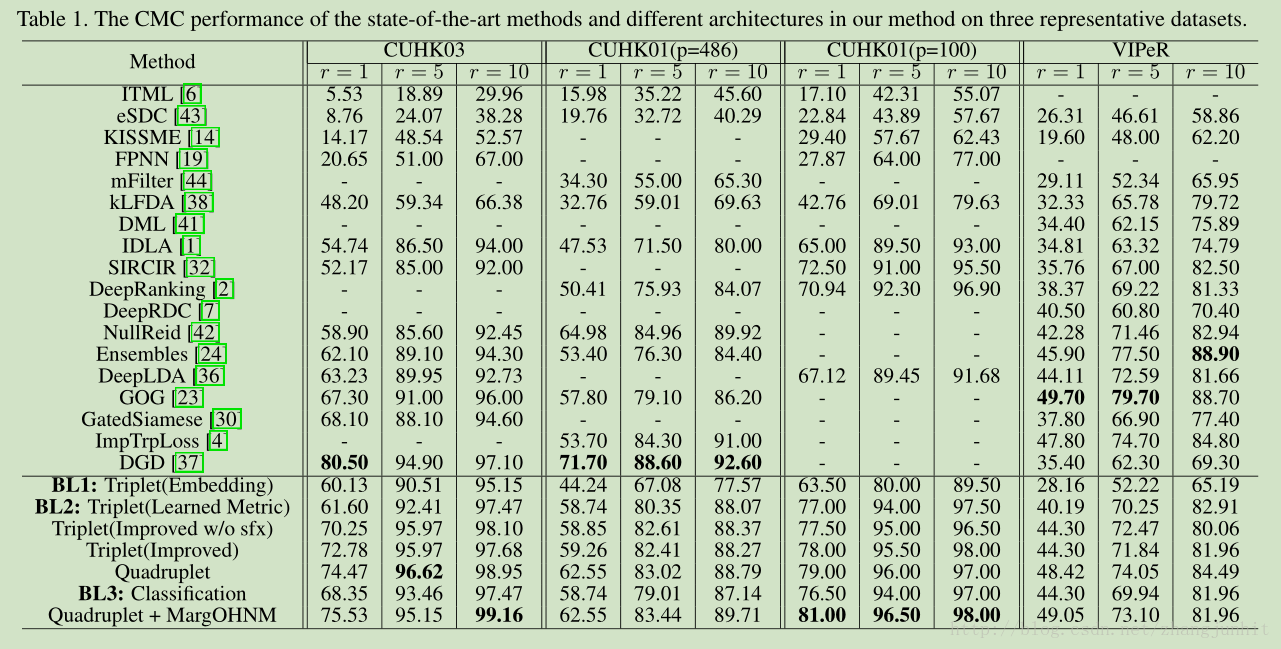
行人检索--Beyond triplet loss: a deep quadruplet network for person re-identification
Beyond triplet loss: a deep quadruplet network for person re-identification CVPR2017 https://arxiv.org/abs/1704.01719 本文使用深度学习进行行人检索,侧重点主要在损失函数的改进,提出了 quadruplet loss 用于减小类内方差 和 增加类间方差 上图显示,在我们新
[数据集][目标检测]雾天行人车辆检测数据集VOC+YOLO格式4415张5类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4415 标注数量(xml文件个数):4415 标注数量(txt文件个数):4415 标注类别数:5 标注类别名称:["bicycle","bus","car","motorbike","person"] 每个类别标

OpenCV实战--利用级联分类器检测眼睛、行人、车牌等等
1、前言 opencv 提供级联分类器除了识别人脸外,还可以检测其他的物体 级联分类器的介绍:OpenCV实战--人脸跟踪(级联分类器) 检测人脸,戴上眼镜的演示: 这里只演示几个,更多的级联分类器文件可以百度自行查看 2、眼睛跟踪 haarcascade_eye.xml 检测眼睛的级联分类器文件 使用该文件可以追踪眼睛 下面将演示利用 haarcascade_eye