本文主要是介绍行人检索--Beyond triplet loss: a deep quadruplet network for person re-identification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Beyond triplet loss: a deep quadruplet network for person re-identification
CVPR2017
https://arxiv.org/abs/1704.01719
本文使用深度学习进行行人检索,侧重点主要在损失函数的改进,提出了 quadruplet loss 用于减小类内方差 和 增加类间方差
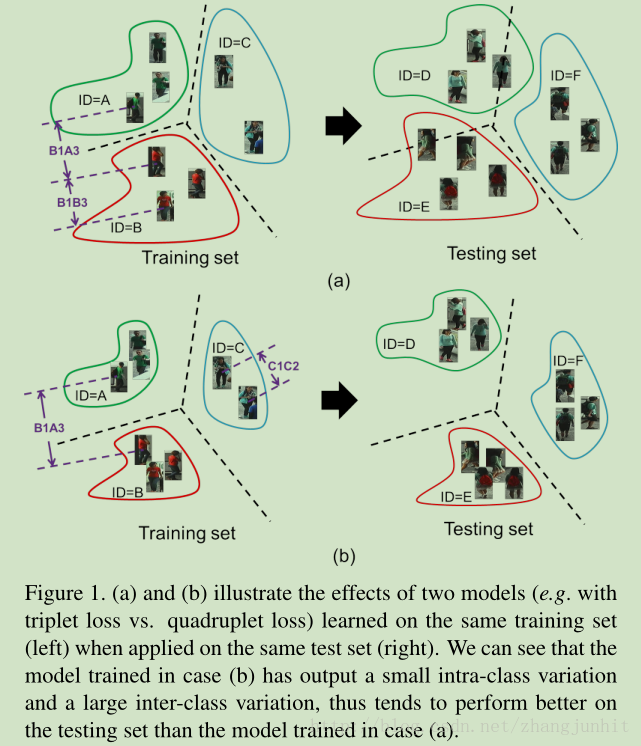
上图显示,在我们新的 quadruplet loss 作用下,对于训练数据的每个类别,我们减小了同类别方差,增加异类方差。
本文的网络结构:
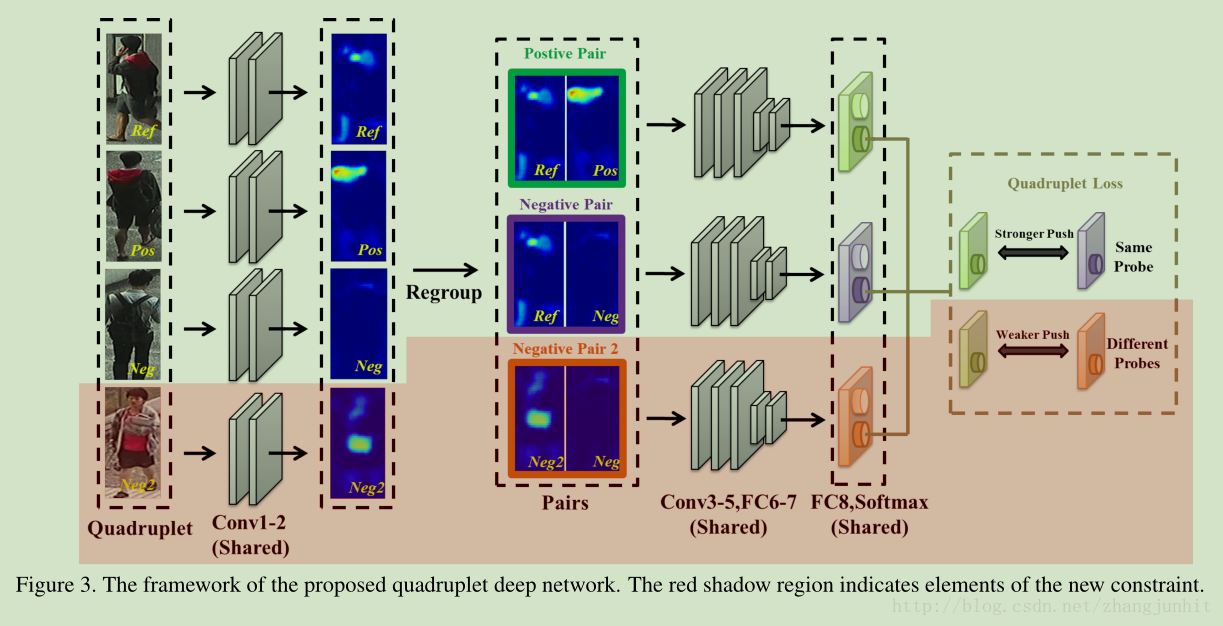
上图红色部分是重点,加入了第二个类别的负样本。
这里的 positive pair negative pair negative pair2 三个损失函数计算值中 positive pair 是最小的。这么做减小了同类别方差 。
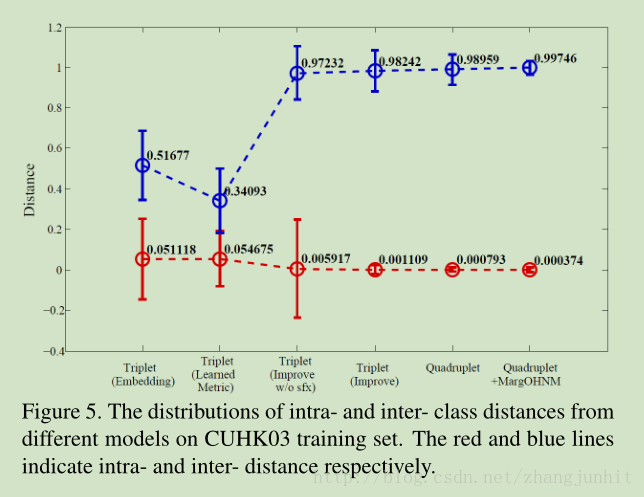
为了增加异类方差,这里我们设计了一个自动最大阈值采样策略,
Margin-based online hard negative mining
Thus the margin threshold is self-adaptive based on the two distributions of the trained model.
通过这个采样策略,使得我们的损失函数中边界阈值自适应得到
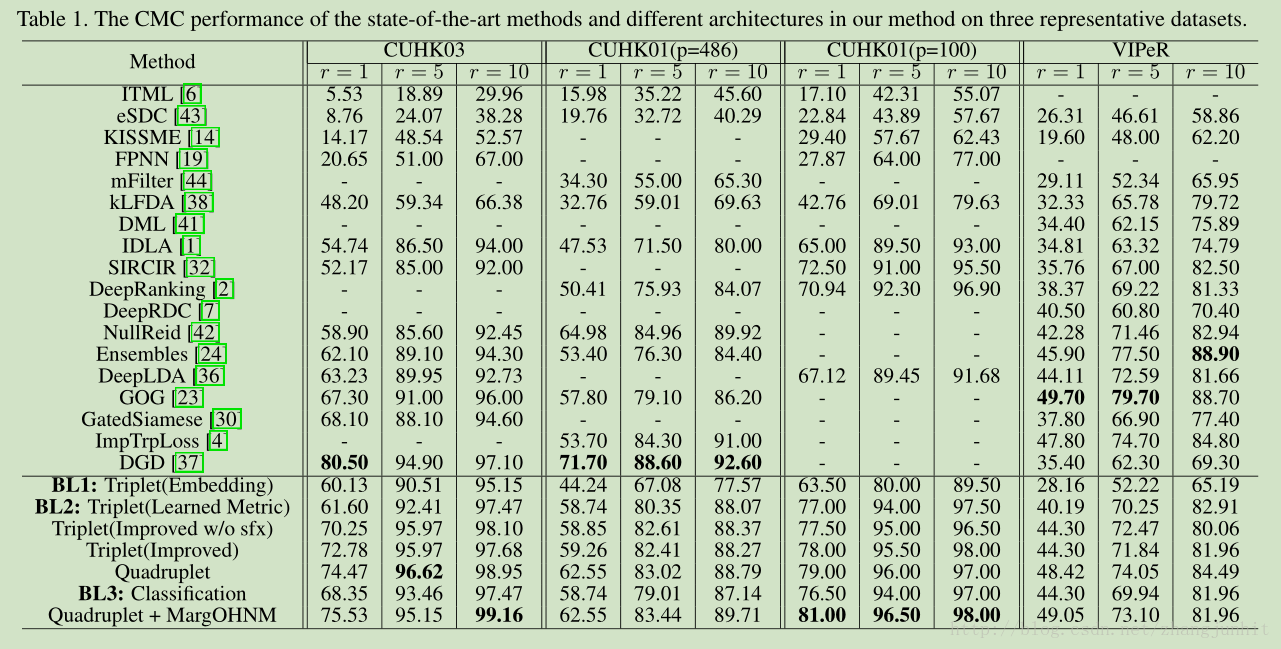
实验结果对比:
这篇关于行人检索--Beyond triplet loss: a deep quadruplet network for person re-identification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








