loss专题

Face Recognition简记1-A Performance Comparison of Loss Functions for Deep Face Recognition
创新点 1.各种loss的比较 总结 很久没见到这么专业的比较了,好高兴。 好像印证了一句话,没有免费的午餐。。。。 ArcFace 和 Angular Margin Softmax是性能比较突出的

【读论文】MUTUAL-CHANNEL LOSS
论文题目:《The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification》 链接:https://arxiv.org/abs/2002.04264 来源:IEEE TIP2020 细粒度分类的主要思想是找出各个子类间的可区分特征,因此文章指出要尽早在通道上进行钻研,而不是从合并
![[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization](/front/images/it_default.jpg)
[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization
引言 为了理解CoSENT的loss,今天来读一下Circle Loss: A Unified Perspective of Pair Similarity Optimization。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 这篇论文从对深度特征学习的成对相似度优化角度出发,旨在最大化同类之间的相似度 s p s_p s

Focal Loss实现
一、序言 Focal Loss是分类常用到的损失函数,面试中也经常容易考,所以这里记录一下。 二、公式和代码 公式: Focal Loss = -alpha*(1-pt)**gamma*log(pt) 其中alpha用来调节类别间的平衡,gamma用来平衡难例和简单例的平衡。 代码: import tor
pytorch Loss Functions
1. pytorch中loss函数使用方法示例 import torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.autograd import Variable# 定义网络时需要继承nn.Module并实现它的forward方法,将网络中具有可学习参数的层放在构造函数__init__中# 不具有可学习参

PyTorch训练中 Loss为负数,且不断减小
在To.Tensor()中会将图像归一化,但是对于一些数据不会归一化,看看标签和数据是否在一个范围内 Pytorch1.01中ToTensor解释 Convert a PIL Image or numpy.ndarray to tensor. Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a
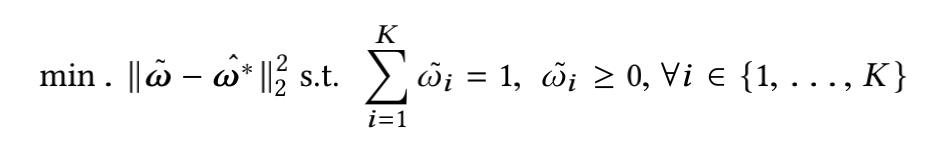
多任务学习MTL模型:多目标Loss优化策略
前言 之前的文章中多任务学习MTL模型:MMoE、PLE,介绍了针对多任务学习的几种模型,着重网络结构方面的优化,减缓task之间相关性低导致梯度冲突,模型效果差,以及task之间的“跷跷板”问题。 但其实多任务学习还存在另外一些棘手的问题: 1、不同task的loss量级不同,可能会出现loss较大的task主导的现象(loss较大的task,梯度也会较大,导致模型的优化方向很大程度上由该

Triplet-Loss原理及其实现、应用
本文个人博客地址: 点击查看欢迎下面留言交流 一、 Triplet loss 1、介绍 Triplet loss最初是在 FaceNet: A Unified Embedding for Face Recognition and Clustering 论文中提出的,可以学到较好的人脸的embedding为什么不适用 softmax函数呢,softmax最终的类别数是确定的,而Triplet

caffe绘制训练过程中的accuracy、loss曲线
训练模型并保存日志文件 首先建立一个训练数据的脚本文件train.sh,其内容如下,其中,2>&1 | tee examples/mnist/mnist_train_log.log 是log日志文件的保存目录。 #!/usr/bin/env sh set -e TOOLS=./build/tools $TOOLS/caffe train --solver=examp
【Keras】keras model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])
讲解了各种loss https://www.cnblogs.com/smuxiaolei/p/8662177.html

神经网络算法 - 一文搞懂Loss Function(损失函数)
本文将从损失函数的本质、损失函数的原理、损失函数的算法三个方面,带您一文搞懂损失函数 Loss Function 。。 损失函数 机器学习“三板斧”: 选择模型家族,定义损失函数量化预测误差, 通过优化算法找到最小化损失的最优模型参数。 机器学习 vs 人类学习 定义一个函数集合(模型选择) 目标:确定一个合适的假设空间或模型家族。 示例:线性回归、逻辑回归、神经网络、决
超分中的GAN总结:常用的判别器类型和GAN loss类型
1. 概述 在真实数据超分任务上,从SRGAN开始,Loss函数基本是Pixel loss + GAN loss + Perceptual loss的组合。 与生成任务不同,对于超分这种复原任务,如果只使用Gan loss或者GAN loss的权重比较大的话,效果就比较差。 SRGAN成功的两个关键点:1. 引入了感知损失函数(Perceptual Loss),它是让生成图像产生细节的关键,

YOLOv9改进策略【损失函数篇】| Slide Loss,解决简单样本和困难样本之间的不平衡问题
一、本文介绍 本文记录的是改进YOLOv9的损失函数,将其替换成Slide Loss,并详细说明了优化原因,注意事项等。Slide Loss函数可以有效地解决样本不平衡问题,为困难样本赋予更高的权重,使模型在训练过程中更加关注困难样本。若是在自己的数据集中发现容易样本的数量非常大,而困难样本相对稀疏,可尝试使用Slide Loss来提高模型在处理复杂样本时的性能。 文章目录 一、本文介绍

2-D CTC Loss
2D-CTC for Scene Text Recognition,1-D CTC Loss参考CTC Loss和Focal CTC Loss Motivation 普通的CTC仅支持1-d,但是文字识别不像语音识别,很多时候文字不是水平的,如果强行“压”到1d,对识别影响很大,如下图所示 Review 1-D CTC 首先对alphabeta进行扩充,加入blank符号,然后定义

CTC Loss和Focal CTC Loss
最近一直在做手写体识别的工作,其中有个很重要的loss那就是ctc loss,之前在文档识别与分析课程中学习过,但是时间久远,早已忘得一干二净,现在重新整理记录下 本文大量引用了- CTC Algorithm Explained Part 1:Training the Network(CTC算法详解之训练篇),只是用自己的语言理解了一下,原论文:Connectionist Temporal

CV-笔记-RetinaNet和Focal Loss
目录 1 Focal Loss1.1 之前目标检测中解决样本不平衡的方法1.2 Focal loss1.2.1 普通的加权方式1.2.2 focal loss 2 RetinaNet2.1 FPN2.2 anchor2.3 打label2.4 分类分支2.5 回归分支2.6 推理阶段 Inference阶段 也就是预测阶段2.5 训练阶段2.5.1 参数初始化 网络训练细节 结果引用
【深度学习】Focal Loss 损失函数
Focal Loss 损失函数 1. Focal Loss 介绍2. 背景3. Focal Loss 定义(1) 交叉熵损失(2) 平衡因子 α t \alpha_t αt(3) 焦点因子 γ \gamma γ 4. 使用场景5. Focal Loss代码实现(Pytorch)6. 总结 1. Focal Loss 介绍 Focal Loss 是一种专门设计用于处理类别不平衡
深度学习:关于损失函数的一些前置知识(PyTorch Loss)
在之前进行实验的时候发现:调用 Pytorch 中的 Loss 函数之前如果对其没有一定的了解,可能会影响实验效果和调试效率。以 CrossEntropyLoss 为例,最初设计实验的时候没有注意到该函数默认返回的是均值,以为是总和,于是最后计算完 Loss 之后,手动做了个均值,导致实际 Loss 被错误缩放,实验效果不佳,在后来 Debug 排除代码模型架构问题的时候才发觉这一点,着实花费了
损失函数 (loss function)
损失函数 损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计(parametric estimation),在宏观经济学中被用于风险管理(risk
FAT:一种快速的Triplet Loss近似方法,学习更鲁棒的特征表示,并进行有噪声标签的提纯...
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 导读 Triplet的两大问题,计算复杂度和噪声敏感,看看这篇文章如何用一种对Triple的近似的方法来解决这两大问题。 摘要 三元组损失是ReID中非常常用的损失, 三元组损失的主要问题在于其计算上非常贵,在大数据集上的训练会受到计算资源的限制。而且数据集中的噪声和离群点会对模型造成比较危险的影响。这篇文章要解决的就是这两个问题,
Generalized Focal Loss:Focal loss魔改以及预测框概率分布,保涨点 | NeurIPS 2020
为了高效地学习准确的预测框及其分布,论文对Focal loss进行拓展,提出了能够优化连续值目标的Generalized Focal loss,包含Quality Focal loss和Distribution Focal loss两种具体形式。QFL用于学习更好的分类分数和定位质量的联合表示,DFL通过对预测框位置进行general分布建模来提供更多的信息以及准确的预测。从实验结果来看,GF

人脸识别-Crystal loss
简介 the Crystal loss gains a significant improvement in the performance. It achieves new state-of-the-art results on IJB-A, IJB-B, IJB-C and LFW datasets, and competitive results on YouTube Face datas

【Python/Pytorch - 网络模型】-- TV Loss损失函数
文章目录 文章目录 00 写在前面01 基于Pytorch版本的TV Loss代码02 论文下载 00 写在前面 在医学图像重建过程中,经常在代价方程中加入TV 正则项,该正则项作为去噪项,对于重建可以起到很大帮助作用。但是对于一些纹理细节要求较高的任务,加入TV 正则项,在一定程度上可能会降低纹理细节。 对于连续函数,其表达式为: 对于图片而言,即为离散的数值,求每一
Caffe学习:使用pycaffe绘制loss、accuracy曲线
直接使用pycaffe进行网络训练与测试无法得到loss、accuracy的直观信息,用下面代码可以实现loss、accuracy曲线绘制: #!/usr/bin/env python# 导入绘图库from pylab import *import matplotlib.pyplot as plt# 导入"咖啡"import caffe# 设置为gpu模式caffe.set_devic

Center-Loss
摘要 这篇博客是对论文A Discriminative Feature Learning Approach for Deep Face Recognition的总结。这篇论文中,作者提出了一种新的辅助损失函数(center loss),结合 softmax交叉熵损失函数,在不同数据及上提高了识别准确率。 简介 卷积神经网络在许多领域都取得了state-of-the-art的结果,包括检测,识