本文主要是介绍【论文通读】VideoGUI: A Benchmark for GUI Automation from Instructional Videos,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
VideoGUI: A Benchmark for GUI Automation from Instructional Videos
- 前言
- Abstract
- Motivation
- VideoGUI
- Pipeline
- Evaluation
- Experiments
- Main Results
- Analysis
- Conclusion
前言
数字智能体的探索又来到了新的阶段,除了常见的桌面工具如PPT,Word,Excel,对于专业工具的使用是一个值得探索的领域,此外,专业工具往往对应着复杂的操作,面对几十上百操作的任务,当前的智能体能否根据query来给出相应的回答呢,本篇VideoGUI为这些问题指明了方向。
| Paper | https://arxiv.org/pdf/2406.10227 |
|---|---|
| homepage | https://showlab.github.io/videogui/ |
Abstract
自动化GUI可以提高人类生产力,但是现有的工作只关注于简单的电脑任务。本文提出新的多模态benchmark VideoGUI,旨在评估以视觉为中心的GUI任务上的智能体。该数据集来源网络高质量教学视频,关注于专业和新颖软件的任务和复杂操作。评估从多角度进行:
- High-level Planning: 没有自然语言描述情况下从视觉角度重建子任务序列。
- Middle-level Planning: 根据截图和目标生成精确的动作描述。
- Atomic-level Execution: 特定的动作,比如准确点击。
Motivation
数字时代与计算机操作主要依赖GUIs,同时LLMs在GUI自动化上展现了潜力。但是:
- 但是现有基于LLMs的应用在领域和任务上受到限制。
- 人类熟悉基础操作,但是对新颖和高级任务上束手无策。
那么如何扩展LLMs的应用场景,同时帮助人类完成难以操作的digital任务?
- 当前有丰富的教学视频,用于教导普通用户执行新颖且复杂的GUI任务。
- 利用这些教学视频进行人工标注复现,获得高质量的标注。

VideoGUI
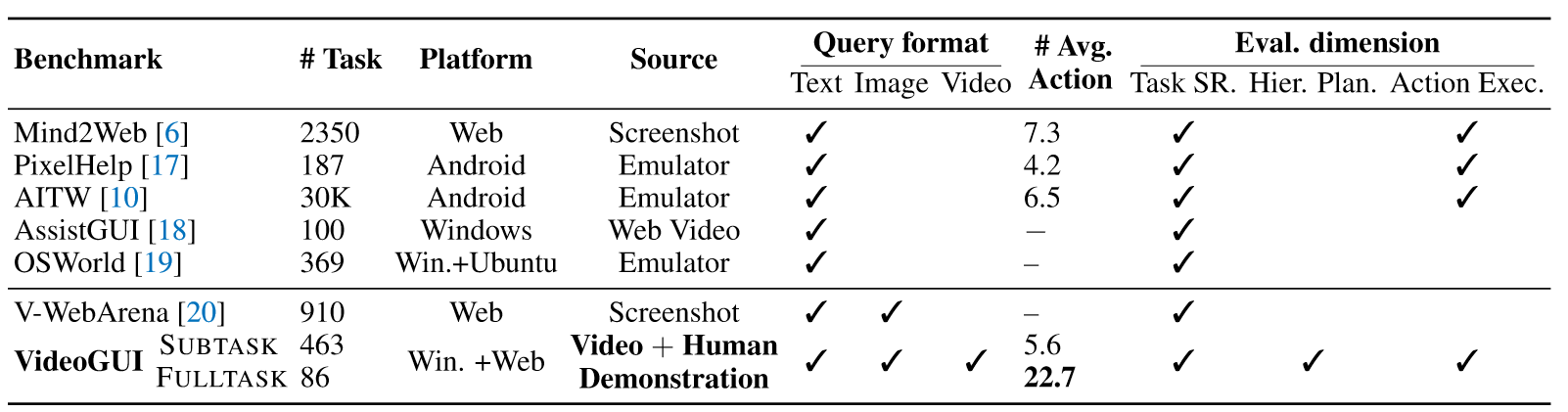
VideoGUI涵盖11个以视觉为中心的软件应用,具有86个复杂任务(平均每个22.7个操作)和463个子任务,以及分层的手动规划和2.7K个手动操作的注释。
应用软件类型:
- media creation: PPT,Runway,Stable Diffusion
- media editing: Adobe Photoshop,Premiere Pro,After Effects,CapCut,DaVinci Resolve
- media browsing: YouTube,VLC Player,Web Stock

Pipeline
- 手动选择配有高质量文字记录的教学视频。为了收集人类操作轨迹,构建仿真环境来监控用户行为。
- 邀请志愿者复现视频内容,用模拟器记录用户的操作。
- 用户操作完毕提供任务文本描述,并将任务分解子任务。此外还要识别操作的活动元素。
- 数据集校验。
下图是任务的分布:

Evaluation

只是简单通过成功率来衡量复杂操作任务是不合适的。任务可以分解为三个阶段(High-level Planning, Middle-level Planning, Atomic-action Execution)去解决,也就可以从三个维度(子任务,每个子任务操作叙述,每个具体操作)对任务完成情况进行测评。
**High-level Planning. **将给定的指令转换成子任务,输入包括三种类别,即视觉查询、详细文本查询、视觉+文本。评估采用GPT-4-Turbo,评分范围为0-5。
**Middle-level Planning. **对于每个给定的子任务,基于观察,智能体输出合适的UI动作。包含三种模式:视觉初始状态+文本查询,文本查询,视觉状态转换。同样采用LLM进行评估。
**Atomic-action Execution. **评估模型是否能够准确输出对应的动作。包括四种通用的动作分类:点击(metric:点到指定区域的recall)、拖拽(metric:开始点和结尾点与指定区域的recall)、滚动(目的让操作元素出现在视线内 metric:视为多跳问题,计算accuracy)、打字(沙盒方案,监听按键,recall+precision进行评估)。
Experiments
Main Results
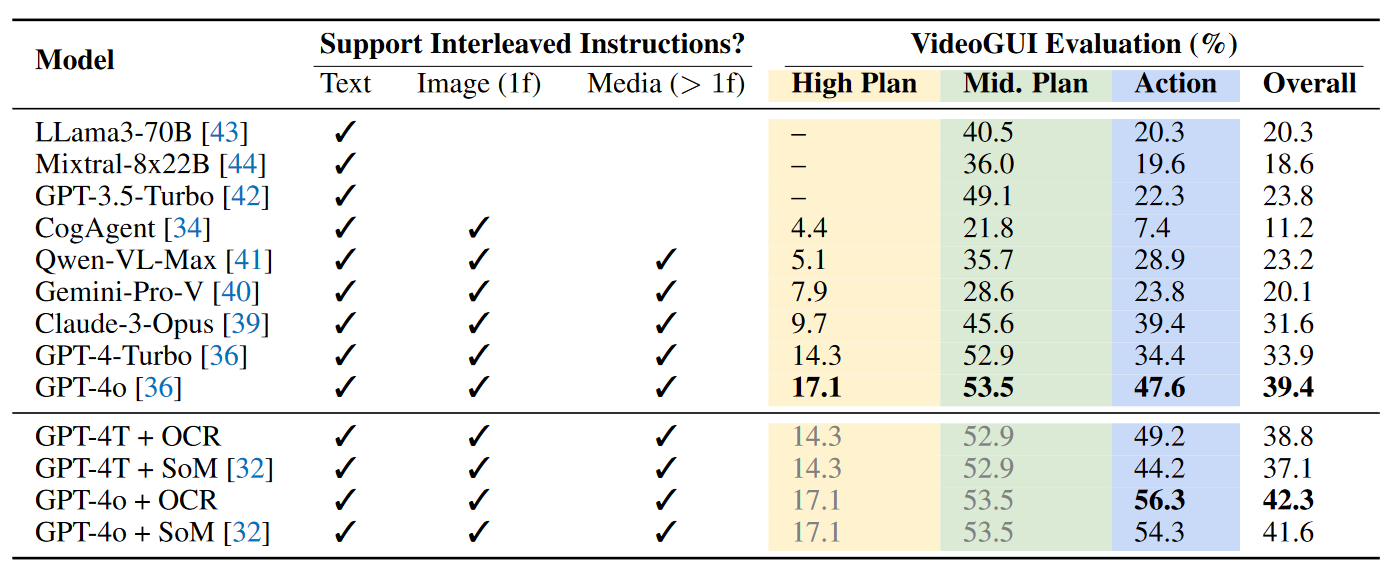
总体而言,GPT-4o取得了最好的表现。

上图研究了不同query类型对planning的影响:
- 对于高级和中级,仅视觉设置具有很大的挑战。
- 在纯文本输入上各个模型表现相似性能。说明在文本query下,文本LLM就可以满足需求。
- 文本+视觉并没有提升性能,说明要提升多模态的感知能力。
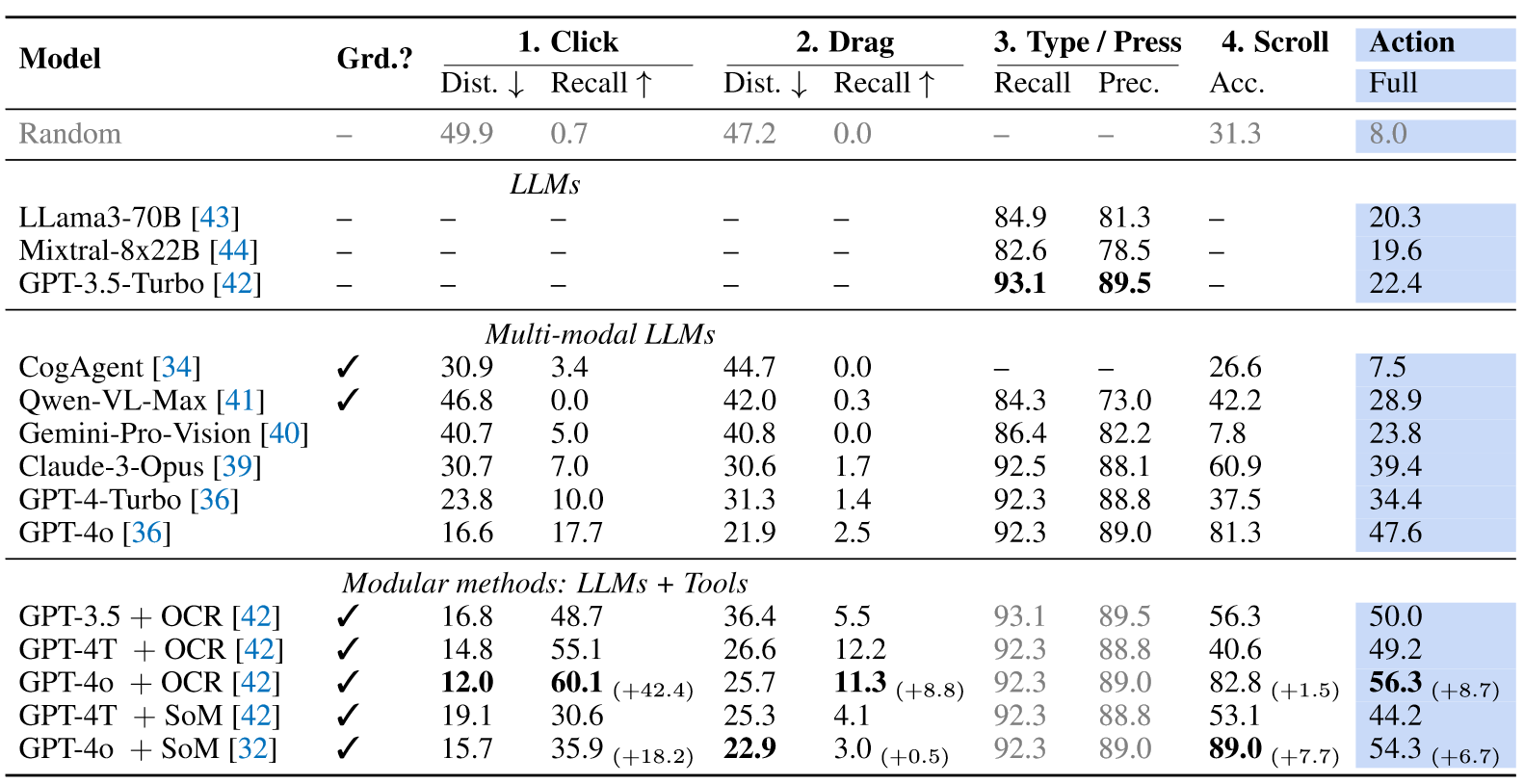
上图评估了不同模型在原子操作上的表现:
- 点击:可以做出正确的估计,但是召回率差。使用OCR等工具可以提升表现。
- 拖动:召回率都很低,OCR工具增益明显。
- 打字:表现优秀,可能因为编码能力不错。
- 滚动:GPT-4o表现最好。
Analysis
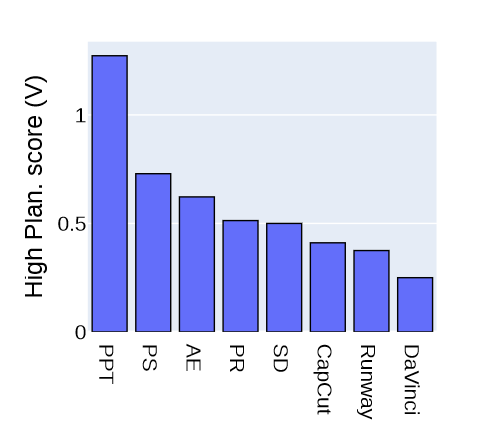
上图表明常见的应用(如PPT)表现更好,而专业软件上,模型性能显著下降。
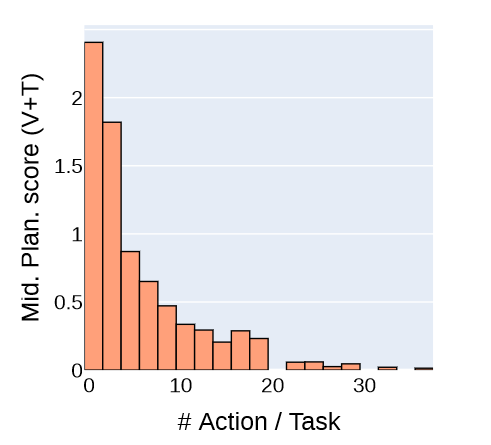
上图显示的是不同操作数量任务的得分分布。随着操作数据量增加,分数不断下降,表明长序列GUI任务的难度。

上图是模型可视化的成功和失败案例。
Conclusion
本文提出针对高级GUI任务的多模式benchmark VideoGUI,这些任务来源于高质量的教学视频。VideoGUI具有较长程序任务、分层手动注释和完善的评估指标,为现有领域指明了方向。通过对当前最先进模型的比较,强调了面向视觉的 GUI 自动化的挑战以及教学视频在推进 GUI 任务自动化方面的潜力。对于这篇工作,我也有一些自己的思考:
- 对高级软件的自动化探索是个有趣的方向,但是仅仅通过手动构建benchmark的方式不具有扩展性。
- 测评采用GPT-4-turbo的方式有些不公平,毕竟他会偏向于自己的输出,并且输出得分也是不稳定的。
- 如何自动化收集不同工具的复杂操作是一个值得探索的方向。
- 视频资源采用人类复现的方式感觉没有物尽其用,应该有更好的利用这些资源的方式。
这篇关于【论文通读】VideoGUI: A Benchmark for GUI Automation from Instructional Videos的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)