benchmark专题

uva 10916 Factstone Benchmark(打表)
题意是求 k ! <= 2 ^ n ,的最小k。 由于n比较大,大到 2 ^ 20 次方,所以 2 ^ 2 ^ 20比较难算,所以做一些基础的数学变换。 对不等式两边同时取log2,得: log2(k ! ) <= log2(2 ^ n)= n,即:log2(1) + log2(2) + log2 (3) + log2(4) + ... + log2(k) <= n ,其中 n 为 2 ^

论文翻译:arxiv-2024 Benchmark Data Contamination of Large Language Models: A Survey
Benchmark Data Contamination of Large Language Models: A Survey https://arxiv.org/abs/2406.04244 大规模语言模型的基准数据污染:一项综述 文章目录 大规模语言模型的基准数据污染:一项综述摘要1 引言 摘要 大规模语言模型(LLMs),如GPT-4、Claude-3和Gemini的快

论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes 优势 1、构建了一个用于监督原始视频去噪的基准数据集。为了多次捕捉瞬间,我们手动为对象s创建运动。在高ISO模式下捕获每一时刻的噪声帧,并通过对多个噪声帧进行平均得到相应的干净帧。 2、有效的原始视频去噪网络(RViDeNet),通过探

一键部署Phi 3.5 mini+vision!多模态阅读基准数据集MRR-Benchmark上线,含550个问答对
小模型又又又卷起来了!微软开源三连发!一口气发布了 Phi 3.5 针对不同任务的 3 个模型,并在多个基准上超越了其他同类模型。 其中 Phi-3.5-mini-instruct 专为内存或算力受限的设备推出,小参数也能展现出强大的推理能力,代码生成、多语言理解等任务信手拈来。而 Phi-3.5-vision-instruct 则是多模态领域的翘楚,能同时处理文本和视觉信息,图像理解、视频摘要

torch.backends.cudnn.benchmark和torch.use_deterministic_algorithms总结学习记录
经常使用PyTorch框架的应该对于torch.backends.cudnn.benchmark和torch.use_deterministic_algorithms这两个语句并不陌生,在以往开发项目的时候可能专门化花时间去了解过,也可能只是浅尝辄止简单有关注过,正好今天再次遇到了就想着总结梳理一下。 torch.backends.cudnn.benchmark 是 PyTorch 中的一个设置
![[Golang]Benchmark性能测试](/front/images/it_default.gif)
[Golang]Benchmark性能测试
前言 基准测试是测量一个程序在固定工作负载下的性能,Go语言也提供了可以支持基准性能测试的benchmark。 使用方法 下面展示一个基准测试的示例代码来剖析下它的使用方式: func Benchmark_test(b *testing.B) {for i := 0; i < b.N ; i++ {s := make([]int, 0)for i := 0; i < 10000; i++
了解基准测试(benchmark test)
1.基本概念 基准测试,也称之为性能测试,是一种用于衡量计算机系统,软件应用或硬件组件性能的测试方法。基准测试旨在通过运行一系列标准化的任务场景来测量系统的性能表现,从而帮助评估系统的各种指标,如响应时间、吞吐量、延迟、资源利用率等。 英文概念:"Benchmark (computing), the result of running a computer pro

拥挤场景多人姿态估计论文梗概及代码CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
姿态估计是视频动作分析识别的基础工作,我有一篇小综述讲了姿态估计相关技术路线的发展,可以点这个链接看。 本文是MVIG大佬们发表在CVPR2019上的一篇论文,上号交通大学,基于AlphaPose思路,进一步提升了拥挤情况下准度 代码:github点这,基于Pytorch,是实时多人姿态估计系统 论文:论文点这 论文第二版点这 Abstract 多人姿态估计是大量计算机视觉任务的基础,近年来也
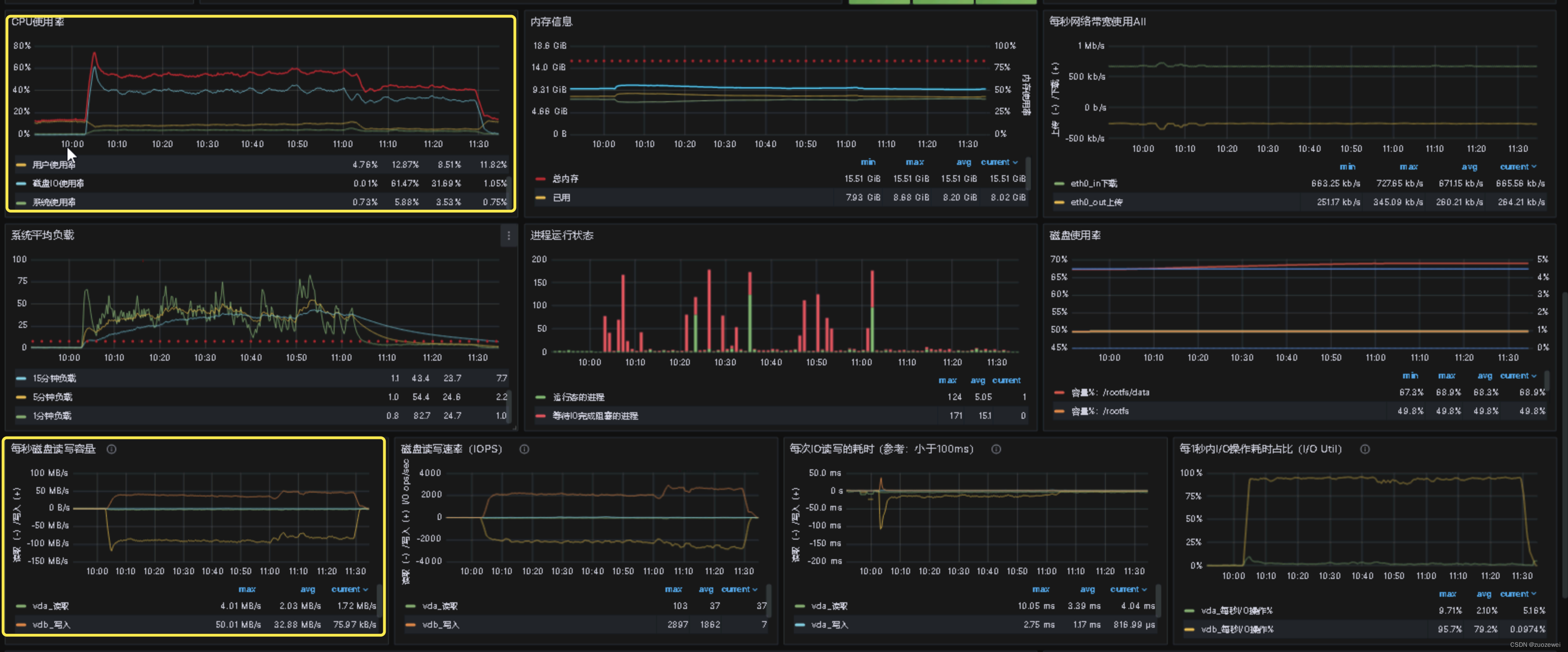
性能工具之 MySQL OLTP Sysbench BenchMark 测试示例
文章目录 一、前言二、测试环境1、服务器配置2、测试拓扑 三、测试工具安装四、测试步骤1、导入数据2、压测数据3、清理数据 五、结果解析六、最后 一、前言 做为一名性能工程师掌握对 MySQL 的性能测试是非常必要的,本文基于 Sysbench 对MySQL OLTP(联机事务处理) 的 BenchMark 测试案例详细介绍具体方法。 二、测试环境 1、服务器配置 数据库服

【论文通读】VideoGUI: A Benchmark for GUI Automation from Instructional Videos
VideoGUI: A Benchmark for GUI Automation from Instructional Videos 前言AbstractMotivationVideoGUIPipelineEvaluation ExperimentsMain ResultsAnalysis Conclusion 前言 数字智能体的探索又来到了新的阶段,除了常见的桌面工具如PPT,
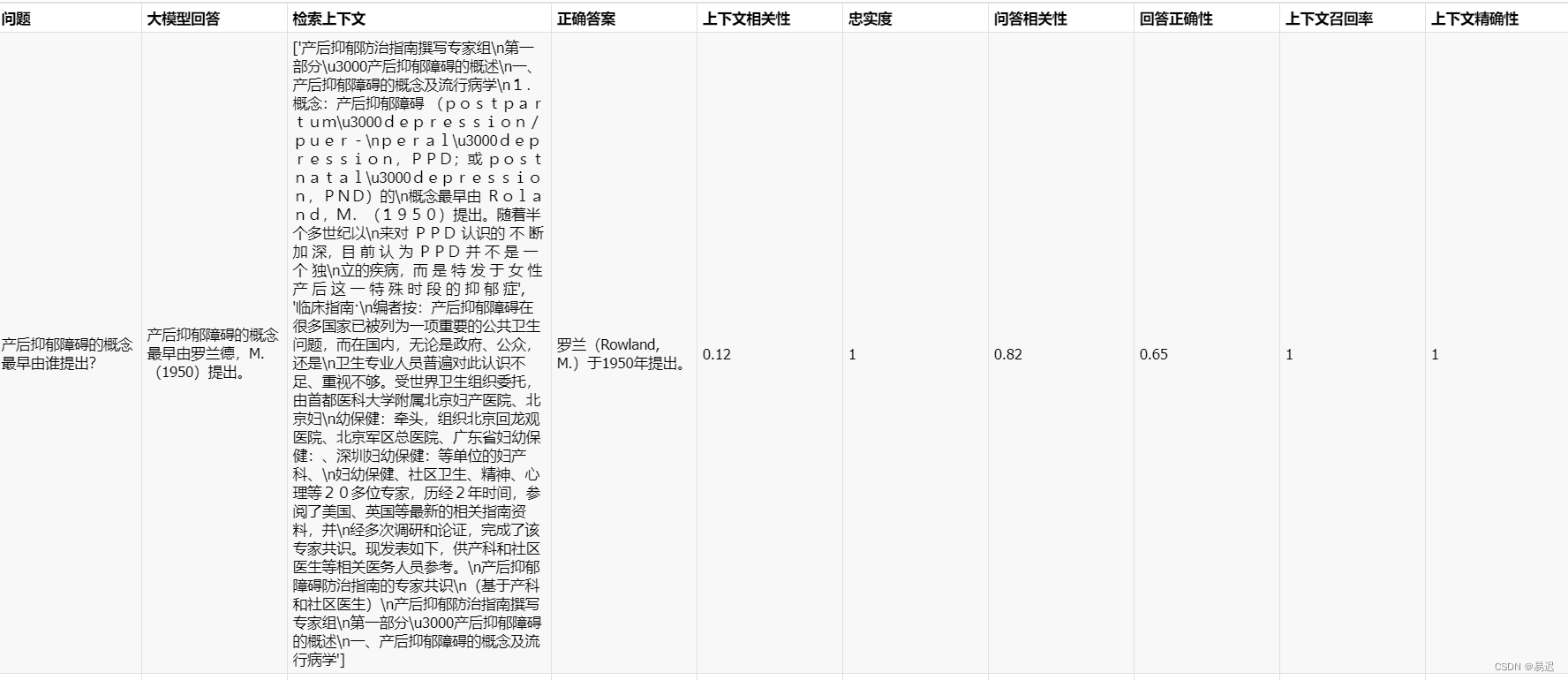
从 0 打造私有知识库 RAG Benchmark 完整实践
背景介绍 最近从 0 构建了一个大模型知识库 RAG 服务的自动化 Benchmark 评估服务,可以基于私有知识库对 RAG 服务进行批量自动化测试与评估。本文是对这个过程的详细记录。 本文实际构建的是医疗行业知识库,基于高质量的医学指南和专家共识进行构建。而实际的问答对也基础知识库已有文档生成,避免参考源不存在导致的大模型幻觉,可以更加客观反映 RAG 服务的能力。当然整体的构建流程是与行
autoML综述:Benchmark and Survey of Automated Machine Learning Frameworks
Benchmark and Survey of Automated Machine Learning Frameworks 文章链接 摘要: 1.当前autoML方法综述和流行automl框架在实际数据上的benchmark 2.总结重要automl搭建机器学习管线的重要技术 Introduction: ML管线需要: 1.有深厚ML算法和统计功底的数据科学家 2.在特定领域有长期经

027、工具_redis-benchmark
redis-benchmark可以为Redis做基准性能测试 1.-c -c(clients)选项代表客户端的并发数量(默认是50)。 2.-n -n(num)选项代表客户端请求总量(默认是100000)。 例如redis-benchmark-c100-n20000代表100各个客户端同时请求Redis,一 共执行20000次。 redis-benchmark会对各类数据结构的命令进行测试

facebook的maskrcnn-benchmark安装出现command '/usr/local/cuda/bin/nvcc' failed with exit status 1
1. 问题 在安装maskrcnn-benchmark的时候,需要安装apex,但是一直报错。 问题已经解决了,问题没有备份,这是copy的其他人的。 相似问题:Error “void *” is incompatible with parameter of type "long long * torch.__version__ = 1.2.0setup.py:43: UserWarni
Tensorflow benchmark测试Aborted (core dumped)错误
运行benchmark的tf_cnn_benchmarks测试时,运行如下命令时最后报core dumped的错误 #执行non_distribute测试python3 run_tests.py 使用secureCRT通过SSH连接服务器,获取log信息,从最后往上查找,发现log里有这样一条错误: .372805: I tensorflow/stream_executor/dso_l
基于图像特征的视觉跟踪系统(Feature-based visual tracking systems)--一篇Visual Tracking Benchmark (2013)综述
reference:http://blog.csdn.net/anshan1984/article/details/8866455 最近读到一篇关于视觉跟踪的综述性文章,“Evaluation of Interest Point Detectors and Feature Descriptors for Visual Tracking”,发表在2011年3月International Jour
redis-benchmark 基准测试
我们可以通过 redis 自带工具 redis-benchmark 来对 redis 服务器进行性能测试。 我们可以通过简单的 redis-benchmark 命令直接对本地部署的 redis 进行性能测试,不用输入任何的参数。默认情况下,redis-benchmark 会向 redis 服务器使用 50 个并发连接发送共 100000 个请求。 如果想指定参数可以参考下面命令: redis
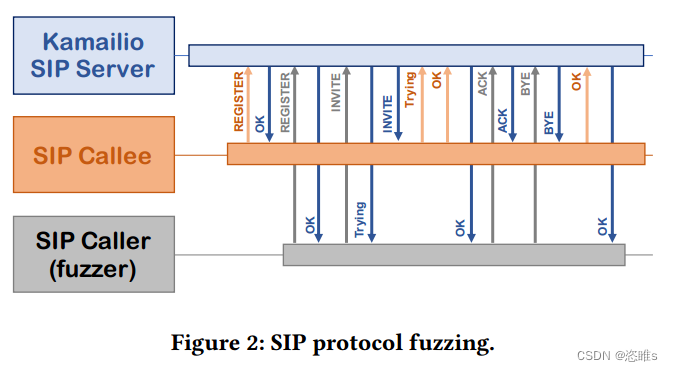
阅读笔记——《ProFuzzBench: A Benchmark for Stateful Protocol Fuzzing》
【参考文献】Natella R, Pham V T. Profuzzbench: A benchmark for stateful protocol fuzzing[C]//Proceedings of the 30th ACM SIGSOFT international symposium on software testing and analysis. 2021: 662-665.【注】
【PyTorch】torch.backends.cudnn.benchmark 和 torch.backends.cudnn.deterministic
1. torch.backends.cudnn.benchmark 在 PyTorch 中,torch.backends.cudnn.benchmark 是一个配置选项,用于在运行时自动选择最优的卷积算法,以提高计算效率。这个设置特别针对使用 CUDA 和 cuDNN 库进行的运算,并在使用具有变化输入尺寸的网络时有很大帮助。让我们更详细地解释这个设置的功能和应用场景。 什么是 cuDNN?
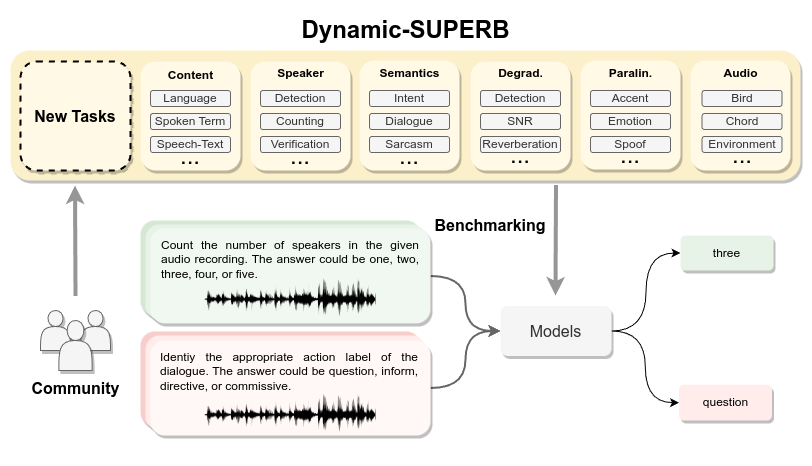
关于Speech processing Universal PERformance Benchmark (SUPERB)基准测试及衍生版本
Speech processing Universal PERformance Benchmark (SUPERB)是由台湾大学、麻省理工大学,卡耐基梅隆大学和 Meta 公司联合提出的评测数据集,其中包含了13项语音理解任务,旨在全面评估模型在语音处理领域的表现。这些任务涵盖了语音信号的各个方面,包括语言学、说话人、韵律和语义元素。 具体来说,SUPERB包含以下13项任

论文《FDDB: A Benchmark for Face Detection in Unconstrained Settings》导读
说到人脸检测,就要谈一谈FDDB,FDDB提供了人脸检测的一个标准,其检测结果可以作为业界内的一个标杆,关于FDDB的具体标准,在该论文中有详细叙述,在此记录下我的解读。 该论文共有八个章节和俩个附录,结构明晰内容清楚,接下来分章节解读论文内容: 第一章节提出了人脸检测的现状,也就是缺乏标准,各家各说各的好,但没有标准,也就没有比较,FDDB应运而生。 该节首先点评了一下

如何使用Go语言进行基准测试(benchmark)?
文章目录 一、基准测试的基本概念二、编写基准测试函数三、运行基准测试四、优化代码性能五、注意事项总结 在Go语言中,基准测试(benchmark)是一种评估代码性能的有效方式。通过基准测试,我们可以测量代码执行的时间、内存使用情况等关键指标,从而优化代码,提升性能。下面我们将详细探讨如何使用Go语言进行基准测试。 一、基准测试的基本概念 在Go语言中,基准测试是通过编
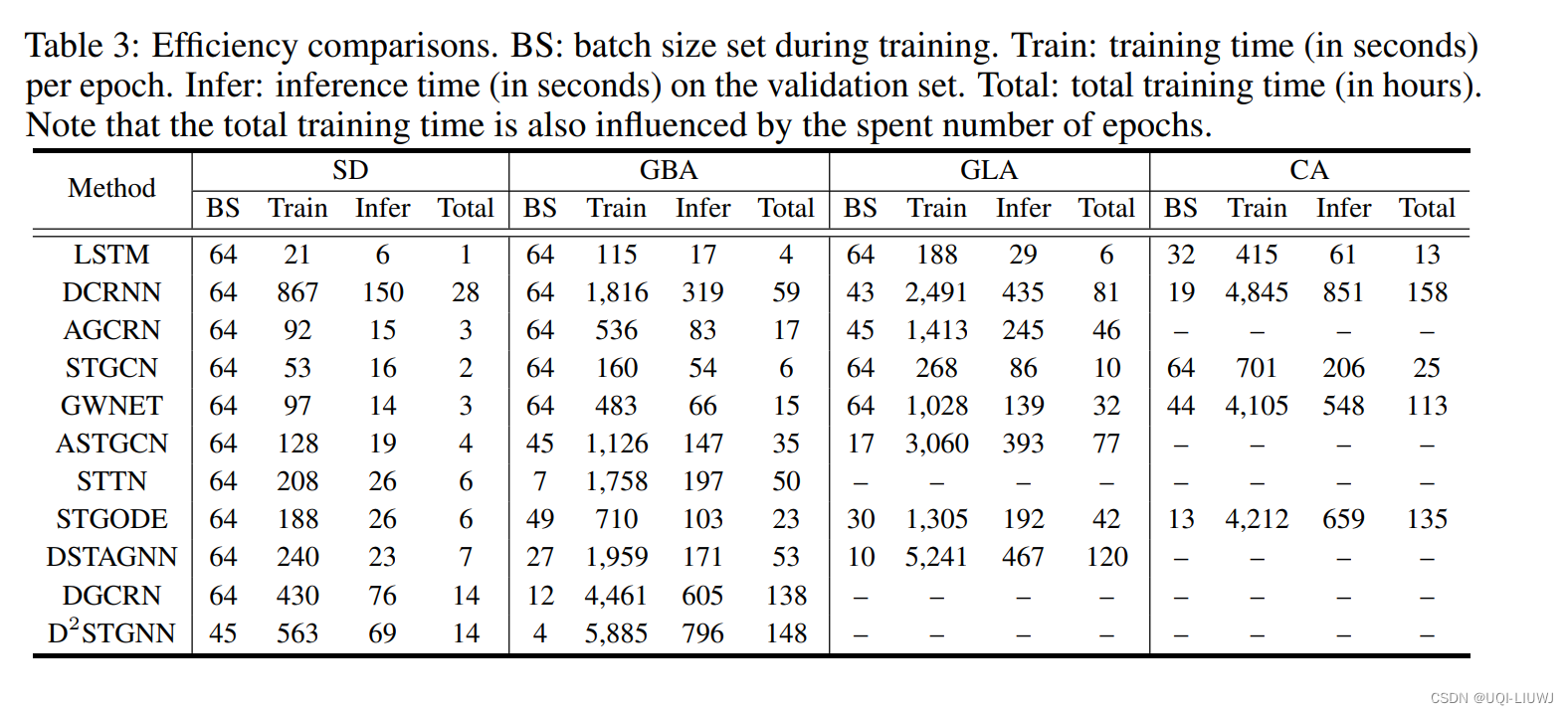
论文笔记;LargeST: A Benchmark Dataset for Large-ScaleTraffic Forecasting
Neurips 2023 1 intro 目前交通预测数据集的问题 规模小,通常只包含数百个节点和边在时间覆盖范围上存在严重不足,通常不超过6个月单个节点的元数据不足 ——> 提出了一个新的基准数据集LargeST 广泛的图大小,包括加利福尼亚州的8,600个传感器丰富的时间覆盖和丰富的节点信息——每个传感器包含5年的数据和全面的元数据liuxu77/LargeST: LargeST:
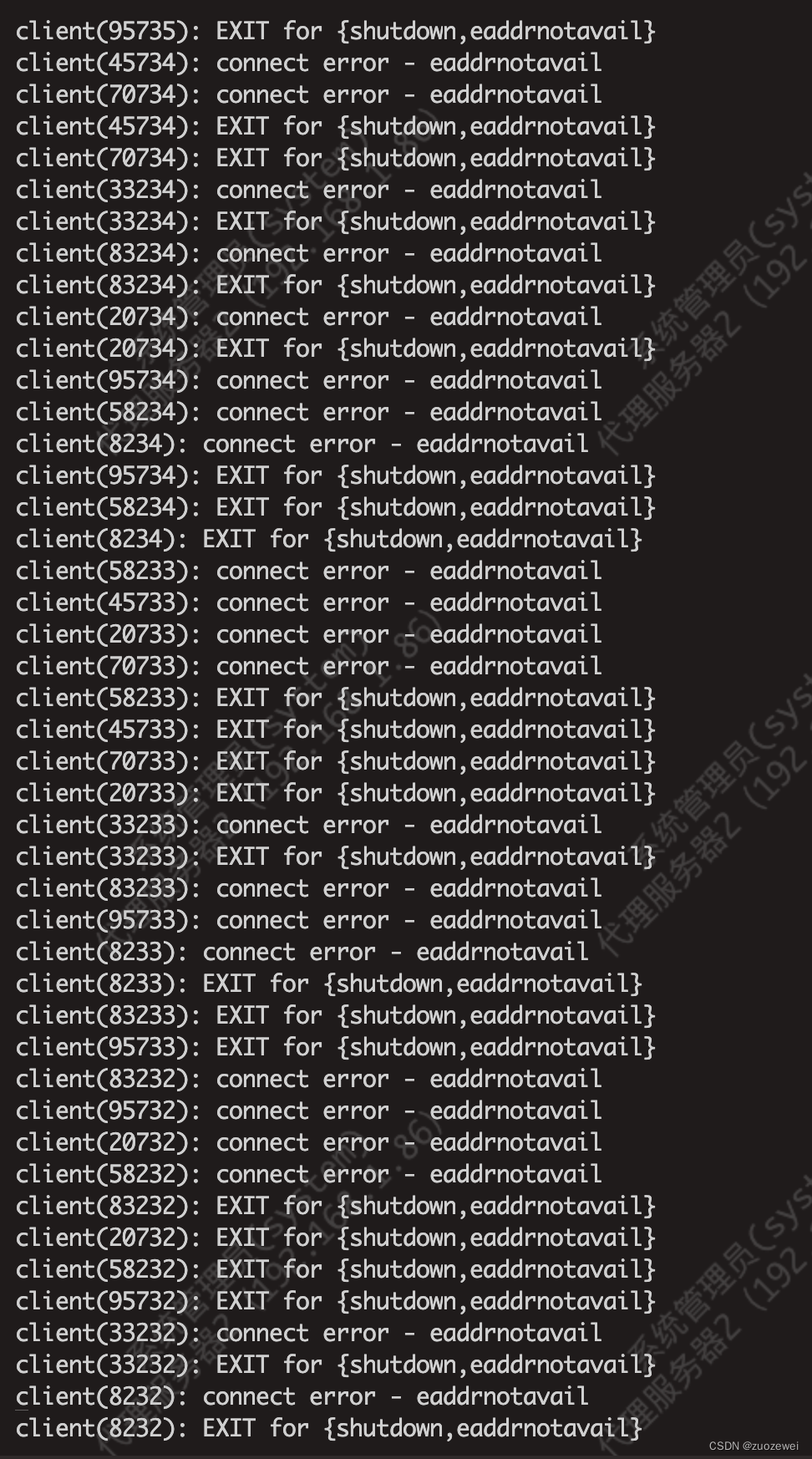
性能工具之emqtt-bench BenchMark 测试示例
文章目录 一、前言二、典型压测场景三、机器准备四、典型压测场景1、并发连接2、消息吞吐量测试2.1 1 对 1(示例)2.2 多对1(示例)2.3 1对多(示例) 五、遇到的问题client(): EXIT for {shutdown,eaddrnotavail} 六、附录:调优建议1、关闭交换分区2、Linux 操作系统参数3、TCP 协议栈网络参数3、测试客户端设置 一、前
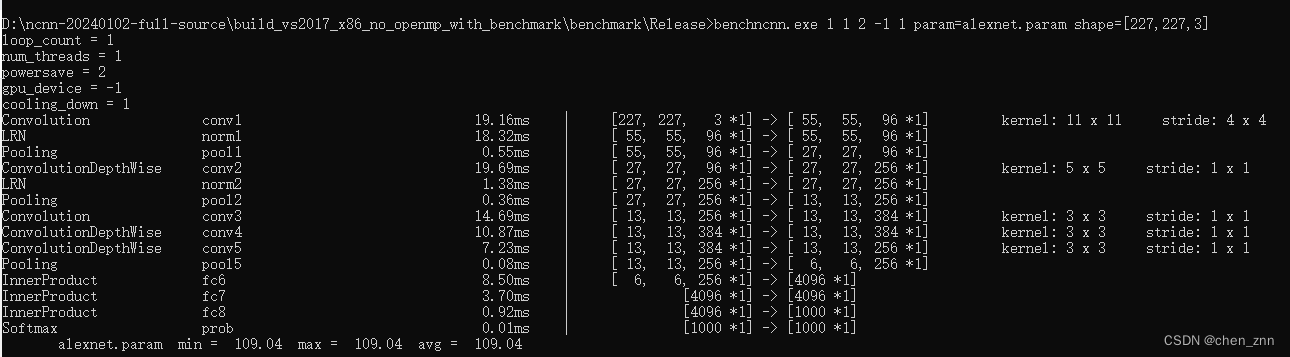
使用ncnn的benchmark来测试模型每层结构的推理耗时
一、编译protobuf-3.21.12 链接:Release Protocol Buffers v21.12 · protocolbuffers/protobuf · GitHub 下载并解压,然后执行以下指令, cd <protobuf-root-dir>mkdir build_vs2017_x86cd build_vs2017_x86## 假设编译的是32位的库cmake -A W
SPEC benchmark 测试程序使用教程
目录 1. 官方资料 1.1. 官方文档1.2. 官方文档阅读顺序1.3. 官方文档每个文档及每个benchmark的简介1.4. 获取官方文档已经有的测试结果 2. SPEC-CPU 应用及特点3. 测量指标4. SPEC 安装方法 4.1. 第一步: 安装4.2. 第二步: 配置环境变量4.3. 参考文档 5. 配置配置文件修改方法 5.1. 参考资料5.2. config语法包含三个部