本文主要是介绍论文笔记;LargeST: A Benchmark Dataset for Large-ScaleTraffic Forecasting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Neurips 2023
1 intro
- 目前交通预测数据集的问题
- 规模小,通常只包含数百个节点和边
- 在时间覆盖范围上存在严重不足,通常不超过6个月
- 单个节点的元数据不足
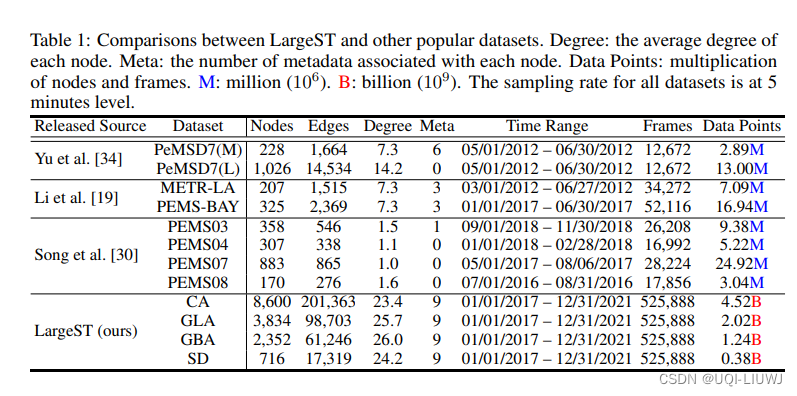
- ——> 提出了一个新的基准数据集LargeST
- 广泛的图大小,包括加利福尼亚州的8,600个传感器
- 丰富的时间覆盖和丰富的节点信息——每个传感器包含5年的数据和全面的元数据
- liuxu77/LargeST: LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting (NeurIPS 2023 DB Track) (github.com)

2 LargeST数据集
2.1 数据收集和组织
- PeMS提供来自加州州际公路系统中18,954个传感器的实时交通数据。
- 为确保LargeST数据集代表整个系统的整体交通状况,论文特意选择标记为“主线”的传感器,还排除了缺少坐标信息或与其他传感器距离极远的传感器。
- ——>获得了一个包含8,600个传感器的数据集(CA)
- 为了对加州不同地区的交通模式进行更细致的分析,论文通过选择CA内的三个代表性区域构建了三个CA子集
- GLA,包括大洛杉矶地区5个县的3,834个传感器:洛杉矶、橙县、河滨、圣贝纳迪诺和文图拉
- GBA,包括大湾区11个县的2,352个传感器:阿拉米达、康特拉科斯塔、马林、纳帕、圣贝尼托、旧金山、圣马特奥、圣克拉拉、圣克鲁斯、索拉诺和索诺马
- SD,仅包括圣迭戈县的716个传感器
- 除了县信息,还为每个节点提供其他元数据,包括它们的坐标、在PeMS中的区域、所在的高速公路、行驶方向和车道数
- 为了构建传感器图的邻接矩阵,论文利用Open Source Routing Machine,一个在OpenStreetMap数据上运行的高性能路由引擎,查询基于坐标的传感器之间的最短驾驶距离
- 然而,计算成对的道路网络距离在处理大量节点时可能非常耗时
- ——>首先计算传感器之间的测地线距离,这比计算它们之间的最短路径要快得多
- ——>然后,限制每个节点只查询与其相距4公里半径内的其他节点的道路网络距离
- ——>最后,通过设置一个小阈值来规范化邻接矩阵,该阈值消除了弱节点连接
- LargeST包含五年(2017年至2021年)的交通流量数据,时间间隔为5分钟(与PeMS相同),总共有525,888个时间帧
- 论文选择不移除具有高缺失交通流量值的节点,以便用户可以自行决定是否填补缺失值
2.2 数据分析
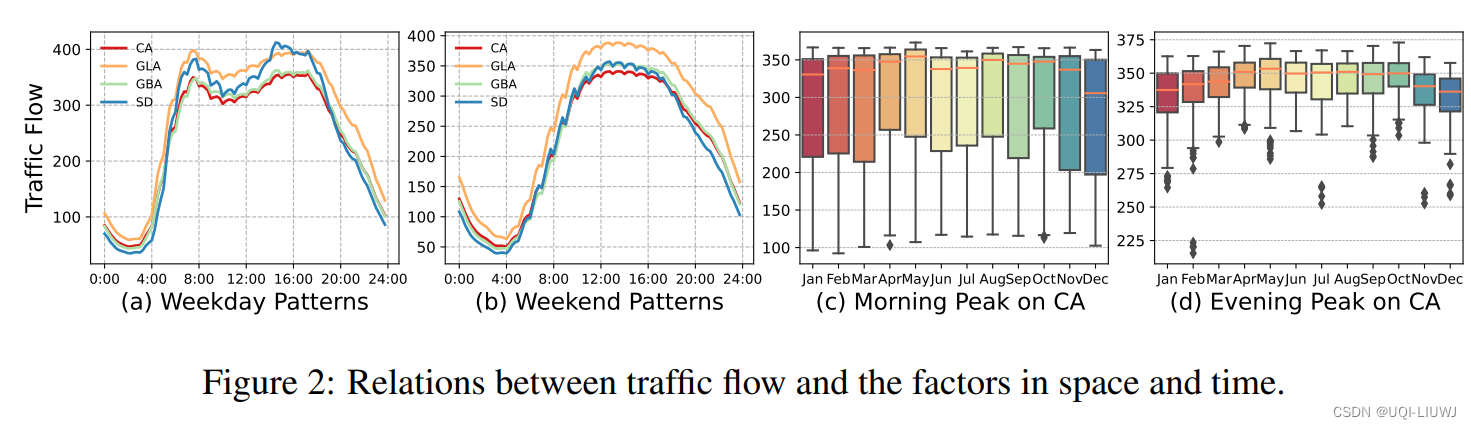
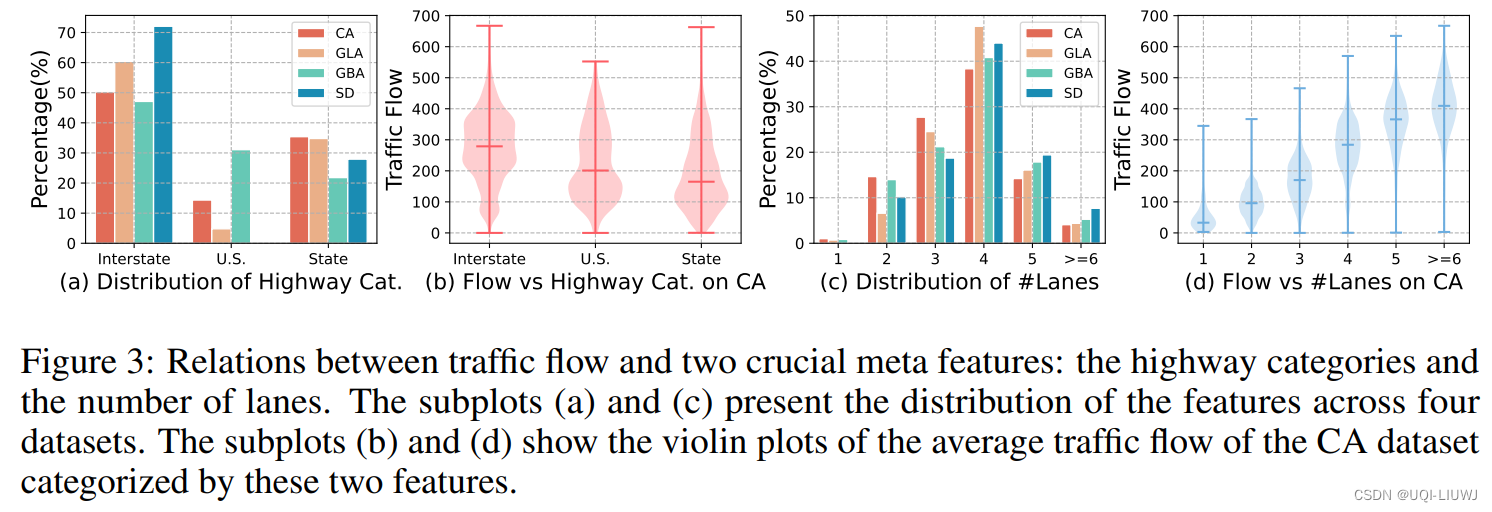
3 实验
- 基于12步历史数据预测未来12步
- 训练集、验证集和测试集的比例为6:2:2
3.1 实验结果
3.1.1 各模型效果
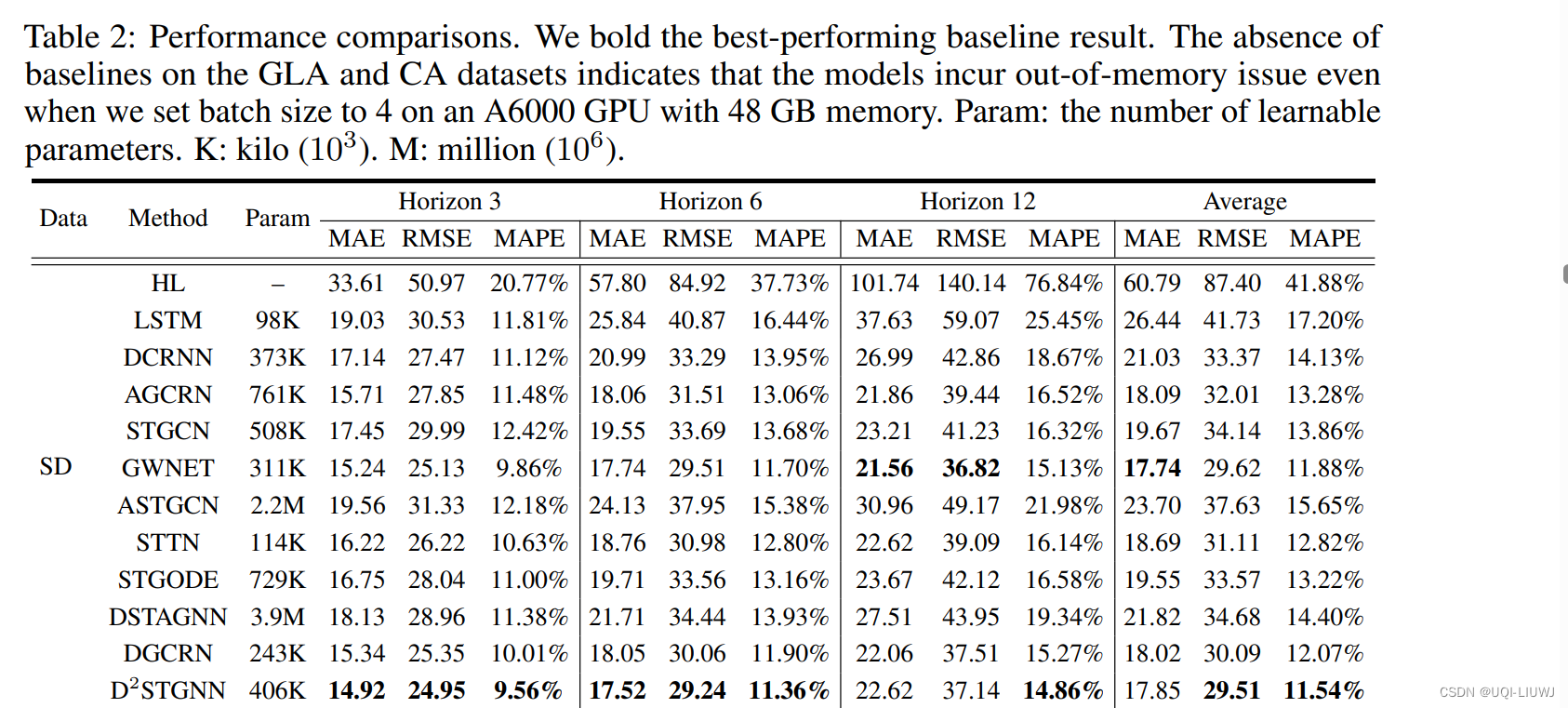
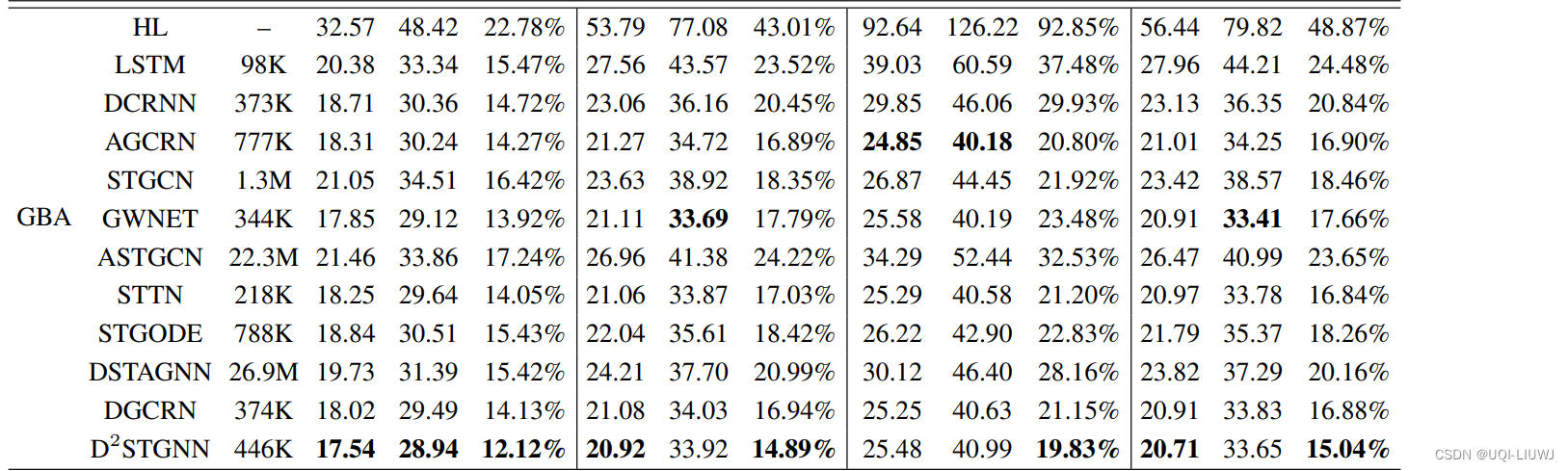

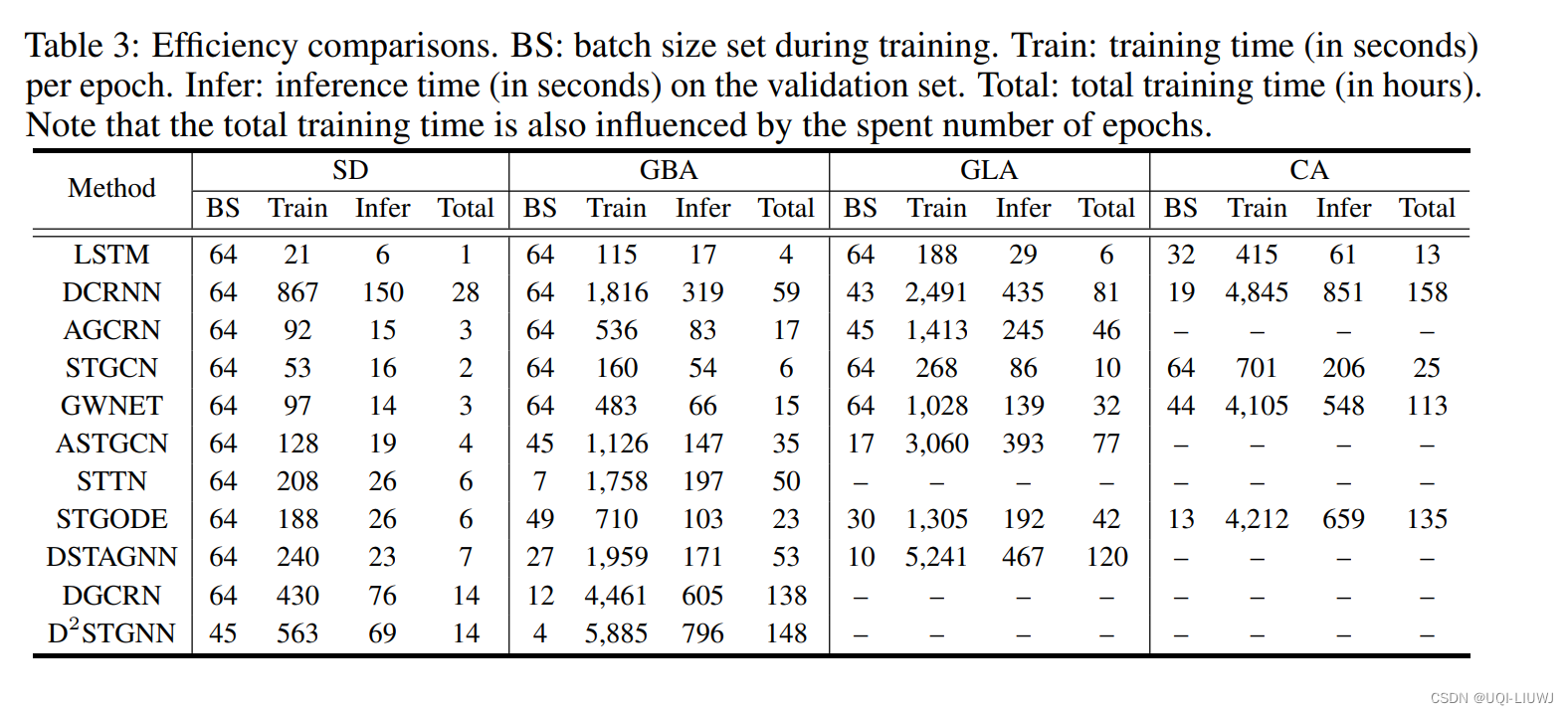
3.1.2 效率比较
4 未来研究中的机会
- 空间、时间和元数据特征的利用。
- 时间分布转移挑战的有价值试验场。
- 数据集提供了一个独特的视角来观察时间分布转移或分布外挑战。
- 例如,研究人员探索非常事件对预测模型的影响时,可以利用该数据集作为一个测试场,以开发处理突然分布转移的策略。
- 简单而有效方法的开发。
- 通过分析表2和表3,显而易见的是,尽管提出的方法在近年来展示了越来越高的准确性,但它们的模型也变得越来越复杂,这对它们在更大传感器网络中的效率和可扩展性有重大影响。
- 因此,开发简单而有效的交通预测方法是至关重要的,以便在现实世界应用中实际实施和部署。
- 基础预测模型的开发。
- 最近,开发基础模型在多个领域引起了广泛兴趣,例如自然语言处理中的ChatGPT和计算机视觉中的Segment Anything。拥有数十亿精选数据点的我们的数据集可能成为在交通预测或时间序列预测领域培训基础模型的宝贵资源。
这篇关于论文笔记;LargeST: A Benchmark Dataset for Large-ScaleTraffic Forecasting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







