本文主要是介绍阅读笔记——《ProFuzzBench: A Benchmark for Stateful Protocol Fuzzing》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

- 【参考文献】Natella R, Pham V T. Profuzzbench: A benchmark for stateful protocol fuzzing[C]//Proceedings of the 30th ACM SIGSOFT international symposium on software testing and analysis. 2021: 662-665.
- 【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。
目录
摘要
1、Introduction
2、Benchmark targets
3、Automation
4、Discussion
摘要
- 本文为有状态的网络协议模糊测试提供了一个基准。该基准包括了一套流行协议的代表性开源网络服务器。
1、Introduction
- 模糊测试研究进展的关键因素之一是基准的可用性,即能够代表性和明确定义的实验目标,用于应用启发式技术并获得可重复和量化的评估。
- 然而,关于如何基准化模糊测试工具仍存在争议。例如,如何衡量模糊测试的进展和深度、如何避免偏见,以及这些目标是否具有代表性真实漏洞系统的特征。
- 现有的模糊测试基准提案包括:
- LAVA-M,一个注入了合成生成漏洞的开源程序集;
- Google FuzzBench,一个在来自OSS-Fuzz项目的目标程序集上运行模糊测试工具的云服务;
- DARPA Cyber Grand Challenge语料库;
- Magma,一个具有手动策划漏洞的目标基准。
- 然而,现有的基准主要关注无状态库和程序(例如多媒体文件格式解析器、数据压缩工具、操作系统实用程序等),但对状态软件的支持有限或没有支持,而状态软件对于促进适用于协议测试的模糊测试技术进步将是有用的。
- 本文提出了一个新的网络协议状态模糊测试基准(ProFuzzBench)。该基准测试提供了一套实现流行网络协议的开源程序,以及用于完全自动化执行模糊测试实验的工具。我们选择了具有代表性的程序,这些程序在以前的有状态模糊测试研究中采用,以及商业和开源模糊测试针对的网络协议。
2、Benchmark targets
- 表1列出了为基准测试选择的协议和相关软件实现。我们总共选择了10个协议,每个协议都有一个软件实现。FTP是唯一的例外,我们在基准测试中包含了两个实现。

- 对于每个协议,表格提供了协议目标和协议状态特性的简要描述。
- 在许多情况下,协议状态跟踪客户端和服务器之间通信会话的进展。例如,FTP协议规定了用于认证的初始状态,包括提供用户名和密码的消息;然后,认证后跟随一个或多个文件传输命令;最后,会话以注销结束。
- 同样,对于安全通信协议(如SSH、TLS、DTLS),协议状态跟踪认证过程中的步骤顺序,包括公钥交换和其他加密信息的交换。
- 在某些协议中,协议状态反映了服务器进程的当前状态及其与客户端交互的历史记录。例如,在SMTP和DAAP中,服务器会将要传输的电子邮件和要播放的歌曲加入队列;在它们被处理的同时,服务器继续通过进一步的消息与客户端互动。
- 基准中还包括DNS协议,尽管原则上它是一个无状态协议。我们仍然选择将此协议纳入基准,因为它是一个流行的模糊测试目标,并且其实现仍可能提供有状态行为,例如缓存过去查询的记录。
3、Automation
- 协议模糊测试基准已经作为一组实用程序发布,用于自动化目标软件的编译、配置、执行和分析(图1)。

- Bulid
- 第一阶段是构建容器镜像。
- 目标软件和一组协议模糊测试工具首先从它们的开源代码库中克隆。目前基准中包含的工具有AFLnwe(AFL的一个基本变体,支持通过网络套接字进行模糊测试)和AFLnet(一个基于AFL的协议感知模糊测试工具)。
- 基准附带了一组针对每个目标软件的补丁,这些补丁在此阶段应用。
- 对于大多数目标软件,这些补丁使程序去随机化,例如,通过在源代码中嵌入固定的种子。去随机化对于获得可重复的行为很重要,即,如果程序再次用相同的输入执行,那么将覆盖相同的执行路径。可重复的行为是正确应用覆盖驱动模糊测试技术的隐含假设。此外,去随机化支持不同模糊测试技术的比较,因为它减少了模糊测试工具因偶然因素而表现优于其他工具的可能性,而更多地体现其自身的优点。
- 在某些情况下,补丁减少或移除了程序中的延迟(例如,使用sleep()),这些延迟用于网络设置中的同步,但在本地进行模糊测试时会不必要地拖慢进程。
- 其他补丁使程序与模糊测试工具兼容。例如,AFL使用UNIX信号来管理目标进程并检测其故障。因此,任何自定义的信号处理程序都应被禁用,以避免干扰基于AFL的模糊测试工具。
- 基准中的一些补丁支持专门为协议模糊测试设计的工具进行实验。例如,AFLnet以一组网络流量跟踪作为输入,其中每个模糊输入由一个跟踪表示,该跟踪由与目标软件交换的一系列消息组成。为了测试协议的更多状态,工具可能需要专注于序列中的特定消息进行模糊测试。因此,AFLnet通过识别各个消息的位置来解析流量跟踪。AFLnet包含了几个支持协议的解析器。若解析器可用,它们会寻找标记字符来分割消息,例如FTP中的字符0x0D0A。一些协议实现没有提供此类标记(例如,消息在连接关闭时结束,没有显式标记)。在这些情况下,补丁会引入此类字符以简化消息解析器的实现。
- 此外,这些补丁支持协议模糊测试工具跟踪协议状态,以最大化状态覆盖率。一些协议(例如FTP)在服务器向客户端的响应消息中提供了独特的状态代码(例如,登录成功时返回的代码是230,表示服务器等待命令,创建新文件夹成功时返回的代码是257)。然而,并非所有协议都是如此。例如,RTSP协议对所有成功的请求都使用相同的响应代码200,而不管当前的服务器状态。为了使有状态模糊测试更有效,我们的基准为目标(Live555服务器)打上补丁,使其在处理不同命令时发送不同的状态代码,例如,处理PLAY命令时返回201,处理PAUSE命令时返回203。
- 然后,在容器镜像内编译(打过补丁的)目标软件。首先使用AFL编译器包装器(即afl-clang-fast/afl-clang-fast++)进行编译,以包含AFL基于覆盖驱动模糊测试工具所需的动态插桩。这个二进制文件将作为模糊测试的目标。目标软件第二次编译时支持gcov:此二进制文件将在基准的最后阶段使用,以便在模糊测试后计算覆盖率指标。基准的构建阶段通过添加特定于目标的文件(例如配置文件、媒体资源)来完成容器镜像的制作。最后,将模糊测试工具和自动化脚本复制到容器镜像中。
- Run
- 在第二阶段,基准使用容器镜像在目标软件上运行选定的模糊测试工具。
- 为了以严格的方式比较不同的模糊测试工具,同样的模糊测试实验应重复进行多次。通过这种方式,可以使用统计技术分析多次重复实验的结果,从而确信一个模糊测试工具确实优于另一个工具。因此,基准提供的实用工具允许用户利用多核架构并行运行多个相同容器的实例。最后,将模糊测试工具生成的原始数据从容器复制到主机。原始数据包括模糊测试工具生成的覆盖了程序新路径的输入(例如,AFL中的“有趣输入”);发现协议状态机中新状态转换的输入(例如,AFLnet中的情况);以及导致目标软件崩溃或挂起的输入。
- Analyze
- 最后阶段分析原始数据以生成关于模糊测试实验的统计信息。
- 它使用支持gcov编译的目标软件再次运行这些输入,以获取每个输入的行级和分支级覆盖信息。然后,根据生成输入的时间戳,生成行覆盖率和分支覆盖率的CSV格式时间序列,用于绘图和比较不同的模糊测试工具。
4、Discussion
- Configuration and multi-party protocols
- 网络协议的模糊测试需要配置其软件实现。选择特定配置决定了通过模糊测试可以测试网络服务器的哪些部分。对于真实世界的网络服务器来说,配置空间可能非常复杂,但这个问题尚未被研究过。之前的研究主要集中在无状态程序上,如库和命令行工具,主要挑战来自于输入的复杂性及其到达深层执行路径的约束。由于配置影响攻击面,它间接成为模糊测试需要关注的问题。
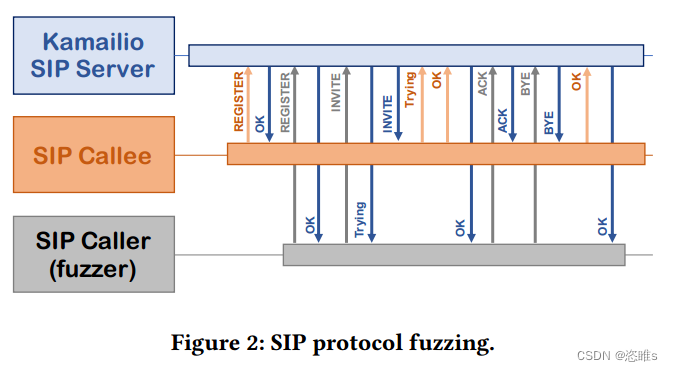
- 值得注意的是,某些协议可能需要运行多于两方的实体。现有的模糊测试技术仅采用客户端-服务器方案,其中模糊测试工具充当客户端。然而,在SIP协议的情况下,至少需要三方:被测试的服务器、一个“呼叫者”和一个“被呼叫者”。一个或多个“被呼叫者”和“呼叫者”必须首先在服务器上注册;然后,呼叫者可以通过指明被呼叫者的名字来联系服务器;服务器将充当呼叫者和被呼叫者之间的代理,以建立他们之间的通信(例如,VoIP通话)。在这个过程中,服务器将处理“振铃”、被呼叫者可能忙线等情况。
- 图2显示了模糊测试工具与Kamailio SIP目标软件之间交互的示例。为了模糊测试一个建立呼叫者和被呼叫者之间通话的SIP会话,模糊测试工具应扮演其中一个角色(在我们的基准中,它扮演呼叫者)。除了模糊测试工具之外,还需要另一个进程来扮演另一个角色。因此,基准附带了脚本,用于自动执行SIP服务器和使用SIP客户端的被呼叫者;在被呼叫者注册后,模糊测试工具可以重放和模糊测试来自语料库的消息序列。语料库已根据进程配置进行准备,即语料库中引用的端口号和客户端名称与SIP客户端和模糊测试工具所使用的一致。
- 对于更复杂的协议,例如IP路由和网络管理,可能需要更多方参与才能进行有意义的测试。当设置多个方时,为目标找到合适的配置变得更加具有挑战性。此外,这些协议超出了当前模糊测试工具的支持范围,因为它们主要关注对服务器单个数据流的模糊测试。
- Deterministic execution
- 模糊测试完整的网络服务器面临的另一个挑战是由于广泛使用线程和基于事件的I/O而导致的非确定性行为。
- 当将相同的输入应用于目标软件时,其非确定性会导致程序路径覆盖率的变化,从而妨碍覆盖驱动的模糊测试。出于这个原因,AFL模糊测试工具对每个扩展覆盖范围的新输入执行“校准”,以评估执行是否确定,并报告异常新输入的百分比(稳定性指标)。
- 在基准中,我们遵循了AFL建议的最佳实践,在可能的情况下禁用线程;或者,将内核级线程(如pthreads)替换为用户级线程(如GNU Pth)及相关的I/O API,就像我们在forked-daapd目标中所做的那样。尽管采取了这些对策,但由于目标软件调用的库中使用了线程和I/O,报告的稳定性在几个基准中仍低于50%。此外,用户级线程增加了测试设置的复杂性(例如,在forked-daapd中,它阻碍了覆盖数据的保存)。
- Test execution speed
- 网络服务器的模糊测试执行速度可能非常慢。与模糊测试库和命令行工具相比(在AFL中可以达到每秒数千次执行),网络服务器的模糊测试因复杂的进程初始化(例如,初始化缓存或数据库)、网络开销(由于进程之间的通信和上下文切换)以及测试用例中长消息序列而变慢。例如,在模糊测试SIP时,由于模糊测试工具与其他进程(服务器和SIP被呼叫者)之间的同步,初始化速度变慢,每秒执行次数不到5次。特别是,在模糊测试DAAP时,被测试的服务器需要大约2秒钟才能可靠地完成初始化,因此模糊测试速度显著下降。
- State identification
- 协议模糊测试的目标是生成覆盖协议状态的测试。一个重要的研究领域是当协议状态机的正式规范不可用时(例如,使用模型推理技术,通过反复试验逆向分析协议)进行模糊测试。在我们的基准中,当协议在消息中没有明确编码当前状态时(例如RTSP协议),我们也面临着在运行时识别协议当前状态的问题。
这篇关于阅读笔记——《ProFuzzBench: A Benchmark for Stateful Protocol Fuzzing》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







