本文主要是介绍EMNLP 2020 Beyond Instructional Videos: Probing for More Diverse Visual-Textual Grounding on YouTube,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
动机
- 从无标签的网络视频中进行预训练已经迅速成为在许多视频待处理任务中实际获得高性能的的手段。
- 通过预测语音内容和自动语音识别(ASR) token之间的grounded关系来学习特征。然而,先前的训练前工作仅限于教学录像;作者希望这个领域是相对“容易”的:在教学视频中,演讲者通常会引用文字描述的目标/动作。即期望视频帧和ASR token中的语义信息在教学视频中可以很容易地关联起来。
- 相似模型是否可以在更多样化的视频语料库上进行训练?如果是,哪些类型的视频“grounded”,哪些类型不“grounded”?
方法
简介
在寻找更普遍的表征时,作者的主要问题是:video-ASR预训练对于更多样化的预训练语料库是否“起作用”?某些类别的非教学性视频是否“有根据”,从而使不同的表征学习得以实现?还是有些类型太难,只充当训练噪音?作者的结论是:
1)在YouTube的大量视频类别中,例如,走遍、车辆、技术评论等,grounding确实是可能的,有些比其他的更难;
2)可转移表征可以通过在更多样的集合上进行训练而成功地学习,这可能提供更多的通用性。
模型
作者考虑一个包含这两个假设的模型:
- 假设ASR token平均地与同一视频内时间上共发生的视频帧具有某种对应关系;
2)忽略缺少ASR的剪辑。
虽然更复杂的模型是可能的,但作者的目标是对一个简单的、有代表性的模型进行错误分析,而不一定要达到最先进的结果。
该模型是对HowTo100M方法的略微简化。其中一个嵌入为视觉内容和ASR token学习。尽管基于self-attention模型的更复杂的方法已经被研究过,但联合嵌入模型仍然是有效的,并且提供了更好的解释性,从而使作者能够进行后面的错误分析。
模型细节:通过计算剪辑i和ASR caption j,si,j在联合空间中对应嵌入的余弦相似度来估计它们之间的相似度。联合嵌入模型采用门控、多层前馈网络的参数化方法。作者用作输入的视觉特征是:为目标检测预训练好的帧式2D Inception-v1和为动作识别预训练好的3D CNN S3D-G特征。语言特征输入为每个单词类型的300维向量;这些都是在训练过程中进行微调的。最大池化用于token嵌入和每帧视觉特征,以实现每个剪辑的单一视觉和文本嵌入。在YouTube-600K上进行训练时,词汇量是61K。
具体包括:
-
Video-ASR预训练。在训练期间,对时间上对应的(剪辑、ASR caption)对进行采样(正例)。对于每一个正例,一组不匹配的负例也是从其他视频和从相同的视频中取样的。与Miech等人相反。作者控制剪辑长度,并采样时间固定长度的片段。在最初的变长片段实验中,作者发现作者的模型能够通过将较长(和较短)的片段与较长(和较短)的ASR caption对齐来“cheating”grounding任务,这些caption大多忽略内容。因此,这种简化的选择使作者的错误分析更加直接,性能变化最小。作者使用5秒的片段,但结果是和10或30秒窗口相似的。为了生成片段,作者首先对每个视频随机采样256个片段,然后丢弃那些没有伴随时间的ASR的片段。尽管结果相似但没有重叠,片段可能重叠。以下hinge损失最小化边际δ:
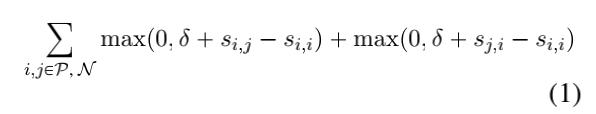
作者采用Adam训练,学习率为.001,设定值为δ=0.1,但未得到显著的超参数优化。作者在300k步后终止训练。
1)CrossTask复制。为了验证作者的模型简化没有显著地阻碍性能,作者复制了HowTo100M方法的关键实验。特别地,作者寻求收集他们使用的预训练语料库——HowTo100M,它由122万个视频组成。例如,由于用户删除视频,作者只能收集原始集合的87%的特征,1.06M个视频。作者通过CrossTask定位任务验证了模型的性能。当作者将细节推迟到原论文时,CrossTask的目标是在描述该任务的未加标签/未分段视频中对该任务的一组过程步骤进行时间定位。算法的性能通过召回度量(越高越好)来评估。作者遵循HowTo100M方法给出的评估程序过程。不同的是,作者嵌入了视频剪辑的5秒滑动窗口,而不是单独嵌入每一帧。
与HowTo100M方法相比,作者的简化模型在较少的数据基础上进行训练。作者实现32.6的召回率,而他们报告了33.6的召回率;作为参考,一个没有预训练的监督上限达到31.6的召回率。
2)测量视觉-文本对齐。通过在真正共现的(剪辑,ASR)对之间的链接预测的镜头来看,公式(1)可以看做为AUC的可微近似值。因此,作者建议使用视频内AUC来操作地测量groundedness:给每个视频分配一个分数,如果模型能够成功地对齐同一视频内的时间对,则奖励模型(如果不能对齐,则惩罚模型)。视频内AUC度量:单个视频中剪辑和ASR caption之间的模型得分全部可能链接;该模型以更高的相似度被奖励给时间对齐的片段,否则,以更高的相似度被奖励给不匹配的片段。图1给出了这种方法的可视化。与其他链接预测度量相比,AUC的一个显著优点是它对标签分布不敏感:短视频不会仅是因为其存在更少的不正确的链接而被系统地分配更高的分数。

-
更多样的语料库。
1)YouTube-600K。YouTube8M是一个包含6.1M的YouTube视频的数据集(数据集v3小于v1/v2,这是由于视频随着时间的推移变得不可用以及其他改进。),其中每个视频都有3K个类别的标签,从“cooking”到“games”再到“nature”。这是YouTube视频中最大、最多样化的公开数据集。由于用户删除和视频没有检测到口语,作者能够通过YouTube API收集1.4M(29%)的视频的ASR;作者进一步筛选了817K个带有英文ASR标签的视频(作者预计非英语视频也将同样成为视觉-文本基础训练数据的极好来源,特别是对于资源不足的语言。作者把重点放在英语上,以简化错误分析。但在今后的工作中,作者期望不会施加这样的限制。)。每个类别的ASR可用性差异极大,例如,74%的“BBC”视频(通常包含广播公司的新闻视频)具有ASR,而几乎没有“Military band”视频具有ASR(表1)。虽然在许多教学视频类别中ASR可用视频的百分比更高,例如“cooking”为31%、“cosmetics”为44%等,但YouTube上的许多非教学视频类别都有ASR可用(例如“silver”为65%;大多数是关于硬币的视频)。原始数据发布的训练/验证split生成639K训练视频(以下称为YouTube-600K)和167K验证集视频。

2)“是教学性”的人性化诠释。虽然对YouTube8M的定性研究显示了与领域限制语料库相比明显的主题和文体多样性,但作者可以肯定的是,YouTube8M并不主要由教学视频组成。作者从验证集中采样带有英文ASR的6.8K的视频,用于人类标签。每段视频都要给三个付费的标注员看,每个标注员都对“这是不是”这个问题给出一个是/否的答案:“这段视频是否关注真实世界中的人类行为,并辅以程序语言,以合理的细节解释屏幕上发生的事情?”。注意,作者对”指导性“的定义意在包含通常的”如何操作“视频,但也试图捕捉更普遍的”指导性“概念。例如,一个未包装的视频(其中产品的部分被取出并与相应的叙述一起组装)应该得到“是”,而一个仅从不同角度显示产品的视频应该得到“否”,这是因为缺少叙述的人类动作。
在对指导方针和示例进行了几次反复的试点研究之后,标注员达成了高度一致:在96%的案例中,所有三位判定都是一致的。从这些标注中,作者发现YouTube-600K语料库中约有74%的视频不是指导性的,即使是广义的“指导性”概念。对从HowTo100M(构建的目的是关注如何操作视频)的100个视频进行了分析,估计其中71%是指导性的。
标注的i3-video语料库(is-it-instructional-video)可供下载。一个潜在的用例:考虑一个专门为教学视频设计的自动化工具。在作者的带标签的语料库上训练的分类器可以用来确定对于未带标签的输入视频应用自动化工具是否合适。
3)哪些类别最容易/最难?作者在YouTube-600K上训练作者的模型,并为每一个178K的验证视频计算视频内AUC。首先,作者对所有标有个别类别的视频进行平均,以产生每个类别的AUC分数。在绝大多数类别中的表现大于50 AUC(随机)基线,范围从51(“Mixtape”)到76(“Muffin”)。为了确保模型不是简单地因为一个类别在数据集中出现频率而成功,作者注意到类别AUC和类别频率之间的相关性基本上为零(ρ=0.02,p大于0.58)。这表明,大多数类别的视频至少在某些方面是基于视觉文本的。

接下来,作者将YouTube8M分类粗略地聚合成元分类,这些元分类被称为"verticals”,并通过YouTube8M发行。例如“Food and Drink.”。图2中给出了4个流行元分类相对于整体AUC分布的AUC分布。一般来说,grounding成功最容易在makeup/hair 视频实现(如“Eye liner”AUC=74、“Updo”AUC=68等)和cooking视频(如“Vegetarian cuisine”AUC=71)上进行,这些领域已普遍用于视频grounding工作。除了这些已经研究过的领域之外,还有其他一些得分较高的类型出现(表2)。相反,一些类别对于模型来说更困难,例如,视频games类别,如“RunEscape"AUC=54和“First-person shooter”AUC=55;这些视频中的演讲者经常提到与games本身无关的各种话题。非视频games类型也可能是困难的,例如“Unidentified flying object”AUC=56、“Dashcam”AUC=54。

接下来作者要问:教学视频真的更容易操作吗?虽然人类对教学性的判断和视频内的AUC呈正相关(ρ=0.20,p不超过0),但这种相关性的低幅度提供了其他类型的视频也有前景的附加经验证实。
4)类内观察。在这一点上,作者已经确定了YouTube视频的广泛类别,这些视频比其他视频更有根据。然而,目前还不清楚为什么算法在“Action Figure”上获得64个AUC,或者在“Call of Duty”(一个第一人的射击比赛)上获得55的AUC。作者现在定义了一个片段级AUC度量,类似于之前定义的视频内AUC度量:它量化了单个ASR caption在时间上被同一视频内的模型定位的可能性。

在考察基于内容的特征和片段级AUC之间的关系之前,必须考虑上下文因素。图3明确了以下关系:
1)视频中ASR caption的安排与片段AUC之间的关系(在视频的开头和结尾处的片段更容易);
2)ASR caption中的token数与片段AUC之间的关系。对于“Action Figure”来说,包含更多单词的ASR片段更容易(这是大多数类别的情况),但对于“Call of Duty”来说,情况恰恰相反。
在控制上下文变量后,作者训练OLS回归模型,从词法的一元模型特征预测片段AUC,同时控制时间/长度特征。词汇特征增加了预测能力(p不超过0.01,F检验)。当作者发现两个类别的部分AUC的一些预测模式时,例如into/outro(例如"hey”,“welcome”,“peace”),作者也观察到主题模式,例如与特定action figure身体部位(“knee”,“shoulder”,“joint"等)相关联的几个一元模型与片段AUC正相关。
-
对预训练的影响。虽然作者已经证明了自grounding对于不同的域集是可能的,但作者通过在一个更多样化的语料库里训练是否获得了什么?或者难以ground的视频引入噪音,降低下游任务的表征?
作者比较了作者模型的两个版本:使用从多样化YouTube-600K语料库(mDiversity)的训练中学习的参数,以及从1M的教学视频的特定领域语料库(MInstructional)中学习的参数。
首先,作者评估每个模型在CrossTask数据集上定位引导步骤的能力。MDiversity的表现令人钦佩,即使存在显著的领域不匹配和较少的预训练视频:当从MInstructional切换到MDiversity时,召回率仅下降了15%(32.6→27.4)。
接下来,作者评估了每个模型在相同视频剪辑对齐任务上的性能:来自YouTube8M验证集的6.8K人工标注视频样本。在视频内AUC方面,MDiversity在59%的视频上优于MInstructional。如果作者将数据划分为“是否具有指导性”的人判断,并在每个子集中比较两个模型,则在57%的指导性视频中,MInstructional“获胜”,而MDiversity“获胜”的非指导性案例则为65%。
简而言之:两种模型在训练/测试领域不匹配和非训练/测试领域不匹配的情况下都达到了合理的性能。综合来看,这对于未来使用更多样化语料库的预训练工作来说是一个有希望的结果:至少对于这些评估来说,在领域转移下,在教学视频grounding任务上的良好表现仍然是可能的。虽然视频内部AUC的比较不一定是确定的,但它表明不同的语料库可能提供更多的通用性,作者期待在未来的工作中进一步探索这一点。
小结
作者将一个具有代表性的预训练模型应用于双向YouTube8M数据集,并对其成功和失败案例进行了研究。作者发现视觉-文本基础在以前未被探索的视频类别中确实是可能的,并且在一个更多样化的集合上的预训练导致了对非教学领域和教学领域的概括的表征。
这篇关于EMNLP 2020 Beyond Instructional Videos: Probing for More Diverse Visual-Textual Grounding on YouTube的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[VC] Visual Studio中读写权限冲突](/front/images/it_default2.jpg)
