grounding专题

Visual grounding-视觉定位任务介绍
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍+点赞👍+评论📝+收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活! 前言 为了解决多模态人工智能系统中语言理解与视觉感知之间的交互与融合问题,以实现更智能、更灵活的多模态数据处理和理解能力。视觉定位通过将自然语言描述与图像内容相匹配,实现了对图像中对

AAAI-2024 | Mono3DVG:首个基于单目RGB图像实现3D Visual Grounding的方法
关注公众号,发现CV技术之美 本文分享论文Mono3DVG: 3D Visual Grounding in Monocular Images,该论文已被 AAAI 2024 接收,数据集和代码已开源。 详细信息如下: 单位:西北工业大学光电与智能研究院iOPEN、慕尼黑工业大学论文链接:https://arxiv.org/abs/2312.08022项目链接:https://github.co

【EAI 011】SayCan: Grounding Language in Robotic Affordances
论文标题:Do As I Can, Not As I Say: Grounding Language in Robotic Affordances 论文作者:Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana

EMNLP 2020 Beyond Instructional Videos: Probing for More Diverse Visual-Textual Grounding on YouTube
动机 从无标签的网络视频中进行预训练已经迅速成为在许多视频待处理任务中实际获得高性能的的手段。通过预测语音内容和自动语音识别(ASR) token之间的grounded关系来学习特征。然而,先前的训练前工作仅限于教学录像;作者希望这个领域是相对“容易”的:在教学视频中,演讲者通常会引用文字描述的目标/动作。即期望视频帧和ASR token中的语义信息在教学视频中可以很容易地关联起来。相似模型是否

UI Grounding 学习笔记
学习资料 【OpenMMLab社区开放麦讲座】《颠覆性创新:多模态对话与精准区域分割 - VPGTrans & NExT-Chat》 1. 学术关键字 LLM Detection 2. 相关论文 InstructBLIP:指令微调RT-DETRVPGTrans: Transfer Visual Prompt Generator across LLMs (NeurIPS 2023):模态对

用于3D Visual Grounding的多模态场景图
文章目录 引言方法1. Language Scene Graph Module Paper:《Free-form Description Guided 3D Visual Graph Network for Object Grounding in Point Cloud》【ICCV’2021】 Code:https://github.com/PNXD/FFL-3DOG
用于3D Visual Grounding的多模态场景图
文章目录 引言方法1. Language Scene Graph Module Paper:《Free-form Description Guided 3D Visual Graph Network for Object Grounding in Point Cloud》【ICCV’2021】 Code:https://github.com/PNXD/FFL-3DOG

(Visual Grounding 论文研读) Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding, 2022 CVPR
最近在看关于visual grounding的文章,对于文章中理解不恰当的内容欢迎批评指正,本文将根据论文的结构来组织结构并且展开一定的拓展。 Abstract visual grounding(VG),即根据自然语言查询在图像中定位对象,是视觉语言理解中的一个重要课题。visual grounding类似于图像处理中的目标检测,知识此时目标的确定需要通过language分析获得。 im

OV-VG: A Benchmark for Open-Vocabulary Visual Grounding
OV-VG: A Benchmark for Open-Vocabulary Visual Grounding 一、Abstract 写在前面 又是一周周末,光调代码去了,都没时间看论文了,汗。 这是一篇关于开放词汇定位的文章,也是近两年的新坑,但是资源也是需要不少。 论文地址:OV-VG: A Benchmark for Open-Vocabulary Visua
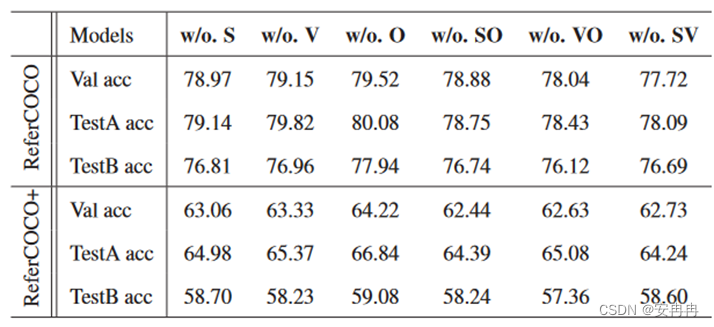
CVPR 2018 基于累积注意力的视觉定位 Visual Grounding via Accumulated Attention 详解
Abstract: VG面临的主要挑战有3个:1 )查询的主要焦点是什么;2 )如何理解图像;3 )如何定位物体。 在本文中,我们将这些挑战形式化为三个注意力问题,并提出了一个累积注意力( A-ATT )机制来共同推理其中的挑战。我们的A - ATT机制可以循环累积图像、查询和对象中有用信息的注意力,而噪声则逐渐被忽略。我们在四个流行的数据集(即: ReferCOCO, ReferCOCO+, R
CVPR 2018 基于累积注意力的视觉定位 Visual Grounding via Accumulated Attention 详解
Abstract: VG面临的主要挑战有3个:1 )查询的主要焦点是什么;2 )如何理解图像;3 )如何定位物体。 在本文中,我们将这些挑战形式化为三个注意力问题,并提出了一个累积注意力( A-ATT )机制来共同推理其中的挑战。我们的A - ATT机制可以循环累积图像、查询和对象中有用信息的注意力,而噪声则逐渐被忽略。我们在四个流行的数据集(即: ReferCOCO, ReferCOCO+, R

Language Adaptive Weight Generation for Multi-task Visual Grounding 论文阅读笔记
Language Adaptive Weight Generation for Multi-task Visual Grounding 论文阅读笔记 一、Abstract二、引言三、相关工作3.1 指代表达式理解3.2 指代表达式分割3.3 动态权重网络 四、方法4.1 总览4.2 语言自适应权重生成语言特征聚合权重生成 4.3 多任务头4.4 训练目标 五、实验5.1 数据集和评估指标数据

RIS 系列 TransVG++: End-to-End Visual Grounding with Language Conditioned Vision Transformer 论文阅读笔记
RIS 系列 TransVG++: End-to-End Visual Grounding with Language Conditioned Vision Transformer 论文阅读笔记 一、Abstract二、引言三、相关工作3.1 视觉定位两阶段方法单阶段方法视觉编码器的融合 3.2 Transformer视觉任务中的 Transformer视觉-语言任务中的 Transform

CVPR 2019 《Cross-Modal Relationship Inference for Grounding Referring Expressions》论文笔记
目录 简介动机方法实验 简介 下载链接 动机 已有方法不能准确地、一致地表示两种模态(referring expressions、object proposals)的上下文关系,具体为: 要么不能准确建模,要么不能达到跨模态的高阶一致性。计算出的pairwise visual differences只能代表同类对象之间、instance-level的差异。要么不支持关系建模