本文主要是介绍(Visual Grounding 论文研读) Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding, 2022 CVPR,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在看关于visual grounding的文章,对于文章中理解不恰当的内容欢迎批评指正,本文将根据论文的结构来组织结构并且展开一定的拓展。
Abstract
- visual grounding(VG),即根据自然语言查询在图像中定位对象,是视觉语言理解中的一个重要课题。visual grounding类似于图像处理中的目标检测,知识此时目标的确定需要通过language分析获得。
image:

query:中间的人
visual grounding输出:

- 为了减少人工添加query注释,本模型采用预训练的object detector提取到的proposal利用query生成模块生成Pseudo-Query伪查询,使用Pseudo-Query代替人工query注释
- 为了提高准确性,针对Pseudo-Query设计了一种prompt模块,其中prompt的作用见: prompt介绍
- 图像模块进行object detector+语言模块进行query+prompt生成后,一起送入多层次跨模态注意机制的视觉-语言模型 multi-level cross-modality attention(ML-CMA)
- 论文代码详见github:论文代码
1. Introduction
- 现有的视觉接地方法可分为两类:全监督fully-supervised(利用区域和query对来进行监督学习)和弱监督 weakly-supervised(仅采用query来进行监督学习),而本文采用无监督学习,query由模块生成然后再将整体模型转化为有监督学习。

- query中常使用的关系:空间(左和右),介词(在和与),动作(投掷),以及比较(越来越大)等,这些关系都是生成query的关键。
- 本文的查询主要分为三个部分进行组合:
(1)名词:最容易被查询的显著对象,由object detector根据置信度选取
(2)属性:被查询对象所具有的内在属性,attribute classifier识别公共属性
(3)空间关系:对象之间的重要空间关系,通过比较同类对象的面积和相对坐标获取(由propsal提供坐标和面积信息) - 本文使用的数据集有: RefCOCO, RefCOCO+ , RefCOCOg 介绍链接
ReferItGame介绍链接 、Flickr30K Entities 介绍链接
2.Method
本文中的模型主要包括三个部分:
(1)伪查询生成模块( pseudo-query generation)
(2)查询提示模块和( query prompt)
(3)图像语言模型( visual-language)
训练阶段训练visual-language model,推理阶段测试visual-language model的能力

2.1 Pseudo-Query Generation
-
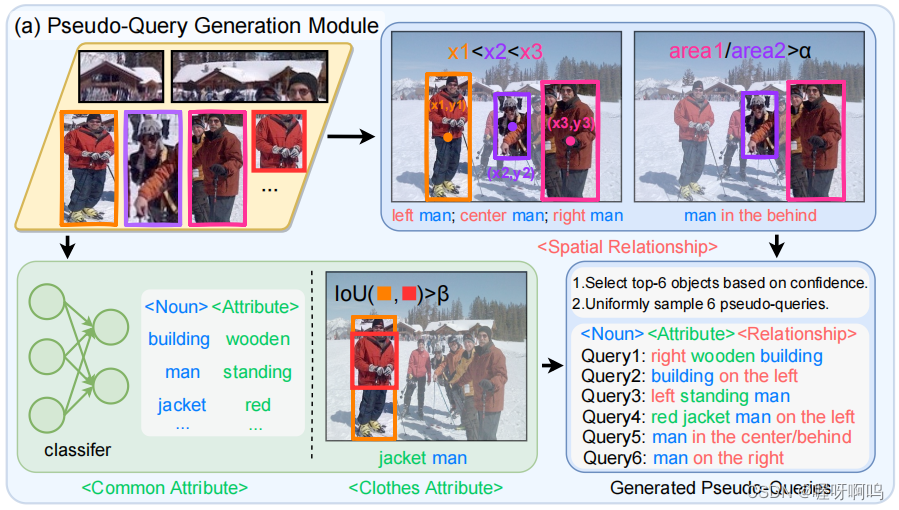
使用object detector识别object 获得object propsal,并分类器和object propsal的坐标关系判断对象的类别:名词、属性和关系,下图为Pseudo-Query Generation模块的模型图。
-
名词:将object识别到的object propsal送入预先训练好的分类器Classifer对其进行分类,使用检测置信度作为一个标准;生成query之前移除较小的物体(一般选取top-N置信度的物体,如在RefCOCO数据集上就选择了top-3置信度的物体)
-
属性:常见的属性有:颜色、大小、材质以及人的状态等等。采用属性分类器:保留最高置信度和超过预先定义阈值的属性为最为最终建议,衣服也是一个重要属性,可以计算IOU来确定,IOU比较大时可以采用该属性。
-
关系:其中最重要的关系为空间关系。空间关系被分为了三个维度:
水平:左中右等;垂直:上下等;深度:前后等
生成的对象由一组空间坐标表示,通过比较两个维度的中心坐标确定物体的空间位置关系为了增强鲁棒性,两坐标在某一维度上的差值必须大于预定义的阈值才认为两个物体之间存在某种关系。物体之间的前后关系,由同类物体所占区域的比率确定,如果比率大于某一阈值,则认为大的在前,小的在后。 -
生成Pseudo-queries,获得名词、属性和关系之后,按照下面的模板生成query

2.2 Query Prompt Module
本文为visual grounding任务设计的prompt模板
“find the region that corresponds to the description {pseudo-query}”
“which region does the text {pseudo-query} describe?”.
2.3 Visual-Language Model
visual-language model由三部分组成:
①Visual encoder
②Language encoder
③Cross-modality fusion module
(其中visual encoder和language encoder的设计遵循TransVG)
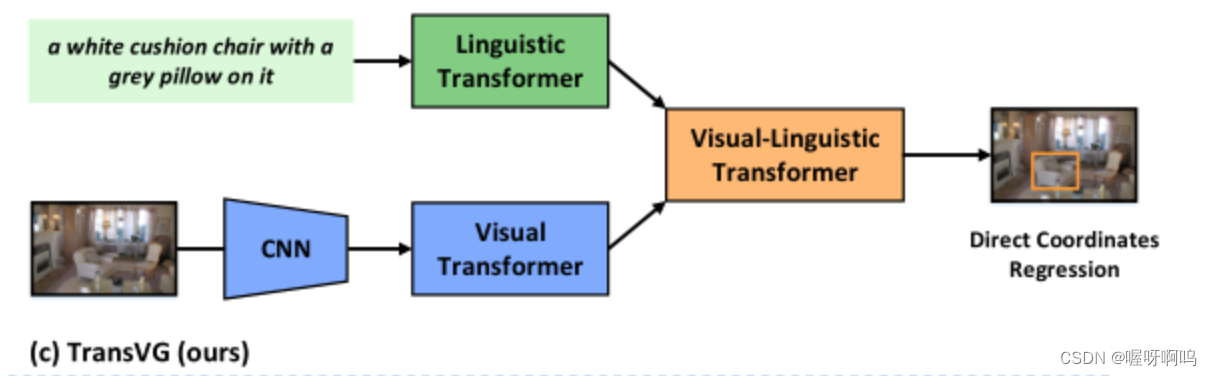
Visual encoder:CNN+Visual Transformer用于图像特征提取:
CNN主干是在ImageNet 上预训练的ResNet- 50模型,Visual Transformer是DETR网络的encoding,由6个transformer layer组成。
DERT介绍博客
Language encoder:token embedding layer+Linguistic Transformer用于文本特征提取:
token embedding layer将离散的词转换为连续的语言向量,Linguistic Transformer采用具有12个transfomer layer的Bert网络。
Bert介绍博客

Cross-modality fusion module
Cross-modality fusion module是整篇文章比较重要的部分,而个人认为文章主要的创新点也在此,训练阶段也主要是对这部分的训练和测试验证。
创新点:传统的方法使用visual encoder和language encoder获得的最终图像和文字的特征来进行特征融合,事实上作者发现不同层次的特征会侧重于不同的信息,低层具有更加粗粒度的信息如形状边缘等,高层具有更加细粒度的信息如内在的对象属性。如果仅仅使用最后的特征来进行融合,无疑会损失一些信息,为了对每一层的信息都加以利用,作者提出了multi-level cross-modality attention (ML-CMA)多层次跨模态注意力机制。
ML-CMA
具体的模型示意图如下图所示:

Visual Encoder共有6层transformer layer,将每一层的特征输出与Language Encoder的最终特征输出进行跨模态自注意力计算,将来自不同层次的所有更新后的视觉特征或文本特征分别连接起来,并利用一个完全连接的层将它们映射到原始维度中。最后,将所有特征连接并输入一个回归头,以预测参考的对象区域。回归头由三个完全连接的层组成。
3.Experiments
论文官方代码github地址
3.1:数据集
本文一共使用了5个数据集用于实验,分别是:
RefCOCO:
使用 ReferitGame 收集的。在这个双人游戏中,第一个玩家被看到一个带有分割目标对象的图像,并要求他们编写一个引用目标对象的自然语言表达式。第二个玩家仅显示图像和引用表达式,并要求单击相应的对象。如果玩家正确地完成他们的工作,他们将获得积分并交换角色。如果没有,它们将显示一个新的对象和图像进行描述。选择这些集合中的图像以包含同一对象类别的两个或多个对象。在 RefCOCO 数据集中,对引用表达式中使用的语言类型没有限制。RefCOCO 由 142,209 个引用表达式组成,用于 50,000 张图像中的 19,994 个对象

RefCOCO+:在这个名为RefCOCO+的数据集版本中,不允许玩家通过向ReferItGame添加“禁忌”词来在其引用表达式中使用位置词。收集该数据集是为了获得一个纯粹基于外观的描述的引用表达数据集,例如,“穿着黄色波点衬衫的男人”而不是“左起第二个男人”,从基于计算机视觉的角度来看,这往往更有趣,并且独立于观众的角度。RefCOCO+ 包含 141,564 个表达式,用于 49,856 张图像中的 19,992 个对象。
RefCoco 和 RefCoco+ 中的 “testA” 和 “testB” 集仅包含人员 并且分别是非人。映像被划分为各种 分裂。

RefCOCOg:RefCOCOg是在非交互式环境中收集的。平均而言,RefCOCOg每个表达式有8.4个单词。RefCOCOg中,谷歌拆分没有规范测试集,验证集,通常在论文中报告为“val”。

ReferItGame:包含130525个表情的数据集,涉及19894张自然场景照片中的96654个不同物体。
RefCOCO、RefCOCO+、RefCOCOg和ReferItGame下载地址:
https://drive.google.com/file/d/1N1Mf3zgYMWI8K_SpIgG1QFBoL13T2wRu/view?usp=sharing
其中下载文件中的other为RefCOCO、RefCOCO+、RefCOCOg的数据集,referit为ReferItGame的数据集。
Flickr30K Entities:在Flickr30k数据集成为被广泛接受的可视化问题回答任务基准之后,Flickr30k entities得到了扩充,以便训练和测试。Flickr30k entities包含31783张图片,主要聚焦于人和动物,每张图片平均有5个英文注释。它识别出相同图像的哪些注释指向同一组实体。因此,生成了244,035个会议链和275,775个提取图像中实体的边界框。
Flickr30K Entities下载地址:
链接:https://pan.baidu.com/s/1I2_YsgINsav-Wzrpkfjj9g
提取码:kepl
本文中五个数据集训练图像的数目分别是16994、16992、24698、8994和29779。
数据集的目录结构如下:

3.2 实施和训练细节
对于每一张图片,分别选取置信度top-N的物体和M个pseudo-queries:
| 数据集 | N | M | epochs | schedule |
|---|---|---|---|---|
| RefCOCO | 3 | 6 | 10 | cosine learning rate schedule |
| RefCOCO+ | 3 | 12 | 20 | cosine learning rate schedule |
| RefCOCOg | 2 | 4 | 10 | cosine learning rate schedule |
| ReferItGame | 6 | 15 | 10 | cosine learning rate schedule |
| Flickr30K Entities | 7 | 28 | 20 | exponential decay schedule |
本文中准确性的判定:如果预测边界和真实边界之间的 Jaccard overlaps大于0.5,则认为是准确的预测。
3.3 实验结果


3.4 消融实验

希望这篇文章对你有帮助!
这篇关于(Visual Grounding 论文研读) Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding, 2022 CVPR的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)