pseudo专题

Light OJ 1054 Efficient Pseudo Code 求n^m的约数和
题目来源:Light OJ 1054 Efficient Pseudo Code 题意:求n的m次这个数的所有的约数和 思路:首先对于一个数n = p1^a1*p2^a2*p3^a3*…*pk^ak 约束和s = (p1^0+p1^1+p1^2+…p1^a1)(p2^0+p2^1+p2^2+…p2^a2)…(pk^0+pk^1+pk^2+…pk^ak) 然后就是先求素数表 分解因子 然后求
a pseudo class
被点击访问过的超链接样式不在具有hover和active了,解决方法是改变CSS属性的排列顺序: L-V-H-A <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http:/

jenkins报错:Pseudo-terminal will not be allocated because stdin is not a terminal
jenkins的流水线部分代码如下 sh'''ssh root@192.168.2.234 << remotesshcd /var/lib/jenkins/workspace/txkc/usr/local/maven/apache-maven-3.8.6/bin/mvn clean package -Ulsremotessh''' 执行流水线出现报错:Pseudo-termin

论文阅读:A Novel Graph based Trajectory Predictor with Pseudo Oracle
A Novel Graph based Trajectory Predictor with Pseudo Oracle 摘要1 引言2 相关工作3 PROPOSED METHODIV. EXPERIMENTAL RESULTSV. CONCLUSION AND DISCUSSION 带有 Pseudo Oracle的新型基于图的轨迹预测器 作者:Biao Yang, Guoch
c# Avalonia 伪类 Pseudo Classes 改变样式
在Avalonia UI框架中,伪类是一种选择器,它们用于在XAML样式中更改控件的视觉状态,而不更改其逻辑状态。伪类经常用于描述控件的特定状态,如激活、禁用、焦点等,并且可以根据这些状态应用不同的样式规则。 使用伪类时,可以在样式中定义它们,并根据控件的状态设置其外观。伪类以冒号:开头,后跟伪类的名称。Avalonia支持多个伪类,例如:pointerover、:focus、:disabled等
Pseudo Terminal 写到master 里面的数据默认是回显的
今天上午调试蓝牙串口, 需要用到 Pseudo Terminal 碰到这位兄弟一样的问题 http://topic.csdn.net/u/20080110/16/3ca493af-09c5-441d-9a6e-381df51ef240.html int find_pts(char **slave) { int master; extern char *pts
PSEUDO-LIDAR++:自动驾驶中 3D 目标检测的精确深度
论文地址:PSEUDO-LIDAR++: ACCURATE DEPTH FOR 3D OBJECT DETECTION IN AUTONOMOUS DRIVING 论文代码:https://github.com/mileyan/Pseudo_Lidar_V2 摘要 3D 检测汽车和行人等物体在自动驾驶中发挥着不可或缺的作用。现有方法很大程度上依赖昂贵的激光雷达传感器来获取准确的深度信息。虽然最

【论文笔记:Unsupervised Domain Adaptation via Structured Prediction Based Selective Pseudo-Labeling】
Unsupervised Domain Adaptation via Structured Prediction Based Selective Pseudo-Labeling 基于结构化预测的选择性伪标记的无监督域自适应IntroductionRelated WorkProposed MethodExperiments and Results 基于结构化预测的选择性伪标记的无监

#每天一篇论文 Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud 单目伪激光雷达点云3D目标检测 摘要 单目3D场景理解任务,例如目标大小估计,车头角度估计和3D位置估计,非常具有挑战性。当前成功的三维场景理解方法需要使用三维传感器。另一方面,基于单一图像的方法性能明显较差。在这项工作中,我们的目标是通过增强基于激光雷达的算法来处理单个图

css的pseudo classes 伪类
请你注意一些CSS伪类属性不被所有浏览器支持,但有四个伪类可以安全使用在链接上 伪类像是指定选择器状态或关联选择器的门闩。它们的形式如:selector:pseudo class { property: value; },在选择器和伪属性之间使用冒号。 Example Source Code [www.52css.com] link 没有点击过的链接 visited以点击

(Visual Grounding 论文研读) Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding, 2022 CVPR
最近在看关于visual grounding的文章,对于文章中理解不恰当的内容欢迎批评指正,本文将根据论文的结构来组织结构并且展开一定的拓展。 Abstract visual grounding(VG),即根据自然语言查询在图像中定位对象,是视觉语言理解中的一个重要课题。visual grounding类似于图像处理中的目标检测,知识此时目标的确定需要通过language分析获得。 im

Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks学习笔记
Pseduo-Label 伪标签的介绍论文介绍核心思想相关流程相关函数Denoising Auto-Encoder模型整体的目标函数 伪标签有效的原因类间的低密度分离熵正则化 实验结果读后感思考存在不足 论文地址:Pseduo-Label 从DAFomer溯源到的论文 伪标签的介绍 伪标签的介绍可以参考:伪标签(Pseudo-Labelling)——锋利的匕首,详细介绍了什
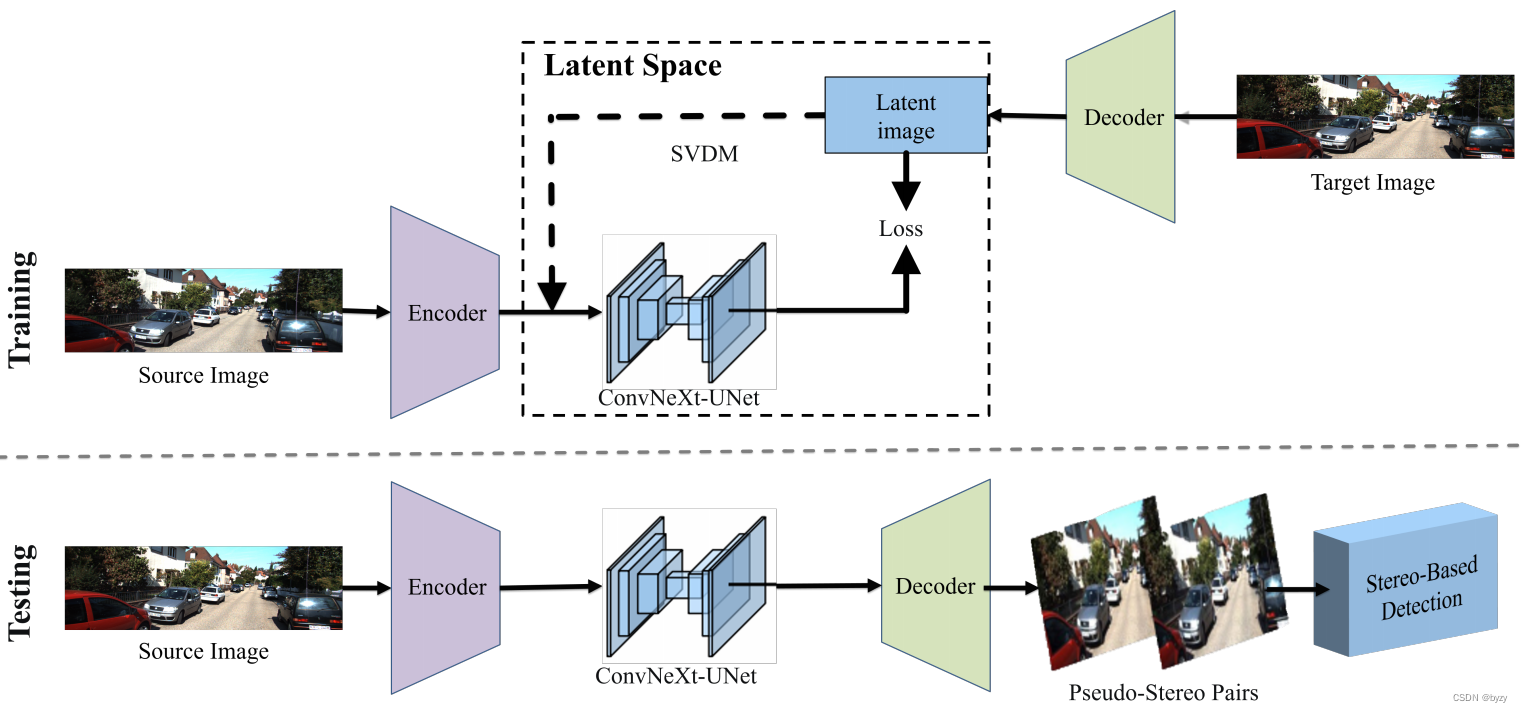
【论文笔记】SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
原文链接:https://arxiv.org/abs/2307.02270 1. 引言 目前的从单目相机生成伪传感器表达的方法依赖预训练的深度估计网络。这些方法需要深度标签来训练深度估计网络,且伪立体方法通过图像正向变形合成立体图像,会导致遮挡区域的像素伪影、扭曲、孔洞。此外,特征级别的伪立体图生成很难直接应用,且适应度有限。 那么如何绕过深度估计,在图像层面设计透视图生成器呢?和GA

【语义分割研究】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 不可靠伪标签的半监督语义分割
论文标题:Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 作者信息:商汤科技, 上海交通大学, 香港中文大学 录用信息:CVPR 2022 → arXiv:https://arxiv.org/pdf/2203.03884.pdf 代码开源:https://github.com/Haochen-Wang409/

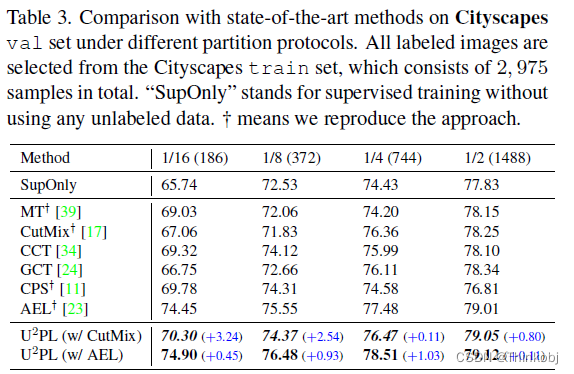
(2022 CVPR) U2PL Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
(2022 CVPR) U2PL Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels Motivation: 半监督语义分割的关键是为未标记图像的像素分配足够的伪标签。 即使是不可靠的预测结果,虽然无法打上确定的伪标签,但仍可以作为部分类别的负样本,从而参与到模型的训练,从而让所有的无标签样本都能在训练过程中
【CVPR2022】论文阅读笔记Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 使用不可靠伪标签的半监督语义分割 论文地址:https://arxiv.org/abs/2203.03884 代码地址 :https://haochen-wang409.github.io/U2PL. 摘要 半监督语义分割的关键是给无标签图像的像素分配

【弱监督学习】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
0.前言 这是一篇在2022年发表在CVPR上的有关弱监督语义分割的文章,文章关注使用图像级标签进行语义分割弱监督训练。现有方法通常产生伪标签,然后通过某种方法对伪标签进行过滤,仅仅使用可靠的像素来进行弱监督训练,然而这样通常会损失大量的像素,导致许多没有被判定为可靠的像素没有被使用,为了提高无像素级标签数据的使用率,本文提出了了U2PL框架。 1.介绍 全监督方法通常需要大量高质量的像素级

论文泛读:Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning
论文泛读:Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning
《Pseudo-dynamics model of a cantileverbeam for animating flexible leaves and branches in wind fiel》
读书报告下载链接: 风场中用于模拟柔性树叶和树枝的悬臂梁伪动力学模型 作者:Shaojun Hu, Tadahiro Fujimoto and Norishige Chiba 发表时间:2009 年 6 月 1 日 发表会议:Computer Animation and Virtual Worlds 1 引言 模拟树木在风场中的运动是自然现象动画领域最具挑战性的课题之

Pseudo Label Based on Multiple Clustering for Unsupervised Cross-Domain Person Re-Identification
Pseudo Label Based on Multiple Clustering for Unsupervised Cross-Domain Person Re-Identification 这次分享一下2020年3-7月份的工作量——一篇自己的paper。 文章链接 主要是基于cross-domain Re-ID基于聚类的方法上提出了一个小trick。 主要思路 基于聚类的跨域行人重识别