本文主要是介绍【弱监督学习】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0.前言
这是一篇在2022年发表在CVPR上的有关弱监督语义分割的文章,文章关注使用图像级标签进行语义分割弱监督训练。现有方法通常产生伪标签,然后通过某种方法对伪标签进行过滤,仅仅使用可靠的像素来进行弱监督训练,然而这样通常会损失大量的像素,导致许多没有被判定为可靠的像素没有被使用,为了提高无像素级标签数据的使用率,本文提出了了U2PL框架。
1.介绍
全监督方法通常需要大量高质量的像素级标签才能完成像素级语义分割,然而现实中,我们通常使用弱监督的方法来减少训练对于像素级标签的依赖。目前的一个比较通用的方法就是生成伪标签,来使用伪标签进行监督训练。这里通常会有一个过滤机制,保证最后生成的伪标签是比较准确的。然而,由于伪标签的过滤机制,通常最后剩下的可靠的伪标签的像素非常有限,往往仅是整个图像的一小部分,这就造成了有些像素在训练过程中从来就没有被使用过,从而导致了模型在某些类上的性能退化。当然,直接使用不可靠的伪标签,也会导致性能退化。
为了避免上面的问题,本文提出了一个U2PL框架。为了避免所有不好的伪标签只来自于一小部分类的问题,本文应用一个对于每一类的队列,确保每一类的负样本平衡起来。同时因为伪标签的质量会在训练过程中变得越来越好,本文还引入了一个动态自适应阈值的策略来区分可靠和不可靠标签。
2.方法
2.1 整体框架
整体框架如下图:
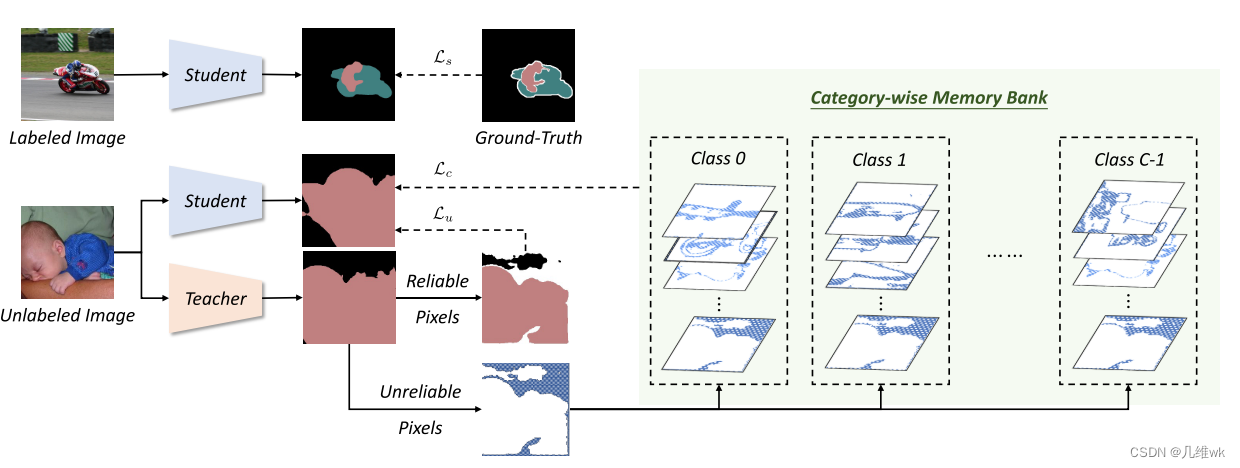
整个框架中包含一个学生网络和一个教师网络,他们的结构相同,唯一不同的是他们权重的更新方式。优化的整体损失如下:
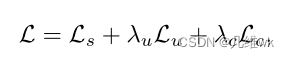
L s L_s Ls的定义如下:
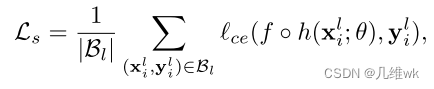
里面的f和h分别代表编码器和分割头,也就是网络结构,这个损失使用的是学生网络预测的结果与人工标注的结果y之间计算的交叉熵。
L u L_u Lu的定义如下:
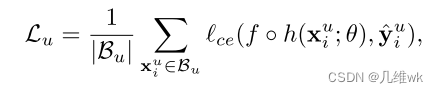
这里实际上是根据教师网络的可靠分割结果与学生网络的预测结果计算交叉熵。
L c L_c Lc是像素级的InfoNCE损失,定义如下:

M是锚点像素的个数(锚点像素具体是什么在2.3小节中会有提及),C是类别总数。每个锚点像素(这里可以理解锚点像素为关注的像素)会有一个正样本和N个负样本,这里面计算的是cosine相似度,z表示的是特征表示,是通过一个表示头(就是一个网络结构)来获得的。具体的内容,在2.3小节中会详细讲解。
2.2 伪标记生成
为了能够生成更加准确的伪标签,本文采用熵来评价伪标签的好坏程度,熵越大,伪标签越差,熵越小,伪标签越小,熵的计算如下式所示:
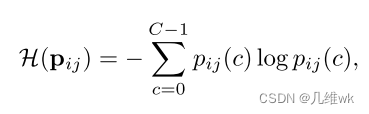
这里的下标i和j表示第i个图像的第j个像素。
给熵卡个阈值,大于阈值就判别为不可靠的伪标签:
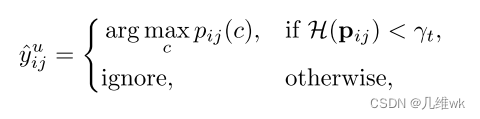
阈值的计算如下:
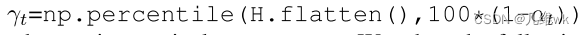
当然,为了能够更好地根据训练过程动态更新阈值,本文采用了一些自适应的策略:
-
动态分区适应
也就是动态的去随着epoch的改变而改变 α t \alpha_t αt,如下:
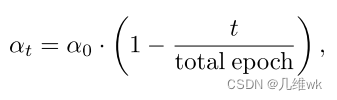
-
权值自适应
这个就是自适应的改变权值 λ u \lambda_u λu,如下:
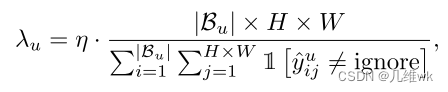
这里面那个像是数字1一样的大写符号1[.]表示指示函数,它是在时间发生时取1,时间不发生的时候取0.
2.3 使用不可靠的伪标签
接下来就到了本文的重头戏了,如何使用到不可靠的伪标签。为了利用不可靠的伪标签,本文引入了三种样本点:(1)锚点像素;(2)正样本像素;(3)负样本像素。
2.3.1 锚点像素
其实锚点像素的选择就是设置一个阈值 δ p \delta_p δp,文中设置为0.3,对于有标签数据,锚点像素的特征表示如下:
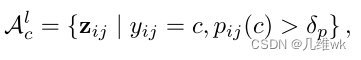
对于无标签数据,只需要利用其伪标签来选锚点数据即可,如下:
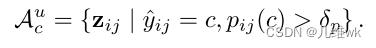
当然,锚点像素在伪标签上也只是那些经过熵过滤留下的可靠标签中选出来的,最后无标签和有标签的取个交集,就变成这样:
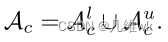
这里面的z也就对应之前2.1小节中计算infoNCE中的z。
2.3.2 正样本像素
正样本像素特征在这里被定义为所有锚点像素特征的中心:
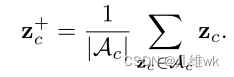
这里面的z+也就对应之前2.1小节中计算infoNCE中的z+。
2.3.3 负样本像素
首先,先生成二值化MASK:

想定义对于c类的一个有标签数据像素为负样本,实际上它应该满足两个条件(两个条件必须同时满足),第一就是它不属于这个类,第二就是它很难与这一类和背景区分开来(容易和背景混淆)。
根据这两个条件,对于有标签的数据: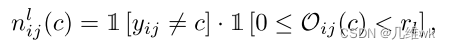
这个式子第第一项也就是这个像素如果不属于这个类,这一项就为1,如果属于这一类,这项就为0。第二项对应的其实是上面的的条件二,但是没看懂具体是啥意思,还是卡了个阈值,以下为没太看懂的部分:
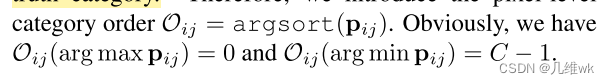
对于这个 O i j O_{ij} Oij,文中说代表类别顺序, p i j p_{ij} pij表示的应该是第i个图像的第j个像素的softmax的结果,它应该是一个长度为C的向量,第0类是背景类,那么如果 p i j p_{ij} pij的第一个元素一定是一个比较大的值,这个 O i j ( a r g m a x ( p i j ) ) = 0 O_{ij}(argmax(p_{ij}))=0 Oij(argmax(pij))=0就比较好理解,但是后面这个 O i j ( a r g m i n ( p i j ) ) = C − 1 O_{ij}(argmin(p_{ij}))=C-1 Oij(argmin(pij))=C−1就理解不了了,我做了一个仿真:
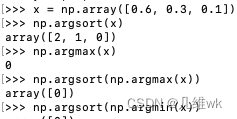
所以对于第二个条件,还是不太明白。治好索性接受了,这里面这个 r l r_l rl是一个阈值,设为3.
类似地,想定义一个无标签数据的像素为负样本,也需要满足两个条件:(1)是不可靠的(经过熵计算过滤下来的);(2)可能不属于类别c的
所以定义式如下:
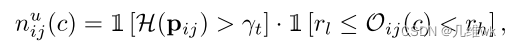
最终的负样本特征表示如下:
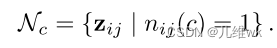
这里面的z也就对应之前2.1小节中计算infoNCE中的z-。
2.4 类别级存储库
这部分就是文中后面的尾巴结构,引入的目的是因为每一个batch里面生成的负样本可能有限,所以把所有生成的负样本都存起来,待到不够用的时候再拿出来用。整个的算法更新流程如下:

3.结论
至此,整个方法都介绍完了,主要的创新之处在于损失函数 L c L_c Lc的设计与使用,它定义了锚点像素、正样本和负样本,从而实现了对unreliable数据的使用,并且实现了比较好的性能。
这篇关于【弱监督学习】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









