监督专题

机器学习之监督学习(三)神经网络
机器学习之监督学习(三)神经网络基础 0. 文章传送1. 深度学习 Deep Learning深度学习的关键特点深度学习VS传统机器学习 2. 生物神经网络 Biological Neural Network3. 神经网络模型基本结构模块一:TensorFlow搭建神经网络 4. 反向传播梯度下降 Back Propagation Gradient Descent模块二:激活函数 activ

(感知机-Perceptron)—有监督学习方法、非概率模型、判别模型、线性模型、参数化模型、批量学习、核方法
定义 假设输入空间(特征空间)是 χ \chi χ ⊆ R n \subseteq R^n ⊆Rn,输出空间是y = { + 1 , − 1 } =\{+1,-1 \} ={+1,−1} 。输入 x ∈ χ x \in \chi x∈χ表示实例的特征向量,对应于输入空间(特征空间)的点;输出 y ∈ y \in y∈y表示实例的类别。由输入空间到输出空间的如下函数: f ( x ) = s

【机器学习-监督学习】决策树
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,依赖于强大的开源库如Scikit-learn、TensorFlow和PyTorch。本专栏介绍机器学习的相关算法以及基于Python的算法实现。

监督学习、半监督学习和无监督学习
在机器学习领域,数据标注是一个至关重要的因素。根据标注数据的使用情况,机器学习可以分为三种主要的学习范式:监督学习、半监督学习和无监督学习。每种学习方法都有其适用的场景和技术实现,下面将详细介绍这些方法的原理、应用场景以及技术实现细节。 1. 监督学习(Supervised Learning) 1.1 原理 监督学习是一种基于标注数据集进行训练的机器学习方法。在这种学习模式下,数据集中的每一

基于中心引导判别学习的弱监督视频异常检测
WEAKLY SUPERVISED VIDEO ANOMALY DETECTION VIA CENTER-GUIDED DISCRIMINATIVE LEARNING 基于中心引导判别学习的弱监督视频异常检测 abstract 由于异常视频内容和时长的多样性,监控视频中的异常检测是一项具有挑战性的任务。在本文中,我们将视频异常检测看作是一个弱监督下视频片段异常分数的回归问题。因此,我们提出了
机器学习算法:监督学习中的线性回归
在机器学习领域,线性回归是一种经典的监督学习算法,用于预测连续数值型的目标变量。它假设输入特征和输出结果之间存在线性关系。线性回归模型的目标是找到一条直线(在二维空间中)或一个平面(在三维空间中),使得这条直线或平面尽可能地接近所有的训练数据点。 线性回归的数学表达 线性回归模型可以表示为: [ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \ldots
强化学习和监督学习的一些区别
强化学习要求agent去探索环境,然后对状态进行evaluate,在每一个状态下agent可以选择多种action,每次选择的依据可以是贪婪或者softmax等,但是得到的reward是无法表明当前的选择是正确的还是错误的,得到的只是一个score,监督学习的labels可以给agent简洁明了的correct or wrong,并且在agent 在对环境充分的探索前即在每一种状态下选择的每个ac

机器学习之监督学习(二)二元逻辑回归
机器学习之监督学习(二)逻辑回归(二元分类问题) 1. 分类 classification2.二元分类逻辑回归 binary-classified logistic regression模块1: sigmoid 激活函数 sigmoid function模型公式模块2: 决策边界 decision boundary代价函数梯度下降欠拟合与过拟合、正则化模块3:评价指标数据集的平衡性平衡数据集

谷歌提出新型半监督方法 MixMatch
事实证明,半监督学习可以很好地利用无标注数据,从而减轻对大型标注数据集的依赖。而谷歌的一项研究将当前主流的半监督学习方法统一起来,得到了一种新算法 MixMatch。该算法可以为数据增强得到的无标注样本估计(guess)低熵标签,并利用 MixUp 来混合标注和无标注数据。实验表明,MixMatch 在许多数据集和标注数据上获得了 STOA 结果,展现出巨大优势。例如,在具有 250

机器学习-算法-半监督学习:半监督学习(Semi-supervised Learning)算法
人工智能-机器学习-算法-半监督学习:半监督学习(Semi-supervised Learning)算法 一、半监督学习算法提出的背景1、监督学习算法2、无监督学习算法3、监督学习的特征选择方法4、无监督学习的特征选择方法5、问题的提出 二、学术名词区分1、主动学习(active learning)2、归纳式学习(inductive learning)3、直推式学习(transductive

NLP-信息抽取:关系抽取【即:三元组抽取,主要用于抽取实体间的关系】【基于命名实体识别、分词、词性标注、依存句法分析、语义角色标注】【自定义模板/规则、监督学习(分类器)、半监督学习、无监督学习】
信息抽取主要包括三个子任务: 实体抽取与链指:也就是命名实体识别关系抽取:通常我们说的三元组(triple)抽取,主要用于抽取实体间的关系事件抽取:相当于一种多元关系的抽取 一、关系抽取概述 关系抽取通常在实体抽取与实体链指之后。在识别出句子中的关键实体后,还需要抽取两个实体或多个实体之间的语义关系。语义关系通常用于连接两个实体,并与实体一起表达文本的主要含义。常见的关系抽取结果
机器学习-有监督学习-分类算法:最大熵模型【迭代过程计算量巨大,实际应用比较难;scikit-learn甚至都没有最大熵模型对应的类库】
最大熵模型(maximum entropy model, MaxEnt)也是很典型的分类算法了。 它和逻辑回归类似,都是属于对数线性分类模型。在损失函数优化的过程中,使用了和支持向量机类似的凸优化技术。而对熵的使用,让我们想起了决策树算法中的ID3和C4.5算法。 理解了最大熵模型,对逻辑回归,支持向量机以及决策树算法都会加深理解。本文就对最大熵模型的原理做一个小结。 一、熵和条件熵 熵
机器学习-有监督学习-集成学习方法(六):Bootstrap->Boosting(提升)方法->LightGBM(Light Gradient Boosting Machine)
机器学习-有监督学习-集成学习方法(六):Bootstrap->Boosting(提升)方法->LightGBM(Light Gradient Boosting Machine) LightGBM 中文文档 https://lightgbm.apachecn.org/ https://zhuanlan.zhihu.com/p/366952043

求解组合优化问题的具有递归特征的无监督图神经网络
文章目录 ABSTRACT1 Introduction2 Related Work3 QRF-GNN方法4 数值实验4.1 MAX-CUT ABSTRACT 介绍了一种名为QRF-GNN的新型算法,有效解决具有二次无约束二进制优化(QUBO)表述的组合问题。依赖无监督学习,从最小化的QUBO放松导出的损失函数。该架构的关键组成部分是中间GNN预测的递归使用、并行卷积层以

sheng的学习笔记-AI-半监督聚类
AI目录:sheng的学习笔记-AI目录-CSDN博客 半监督学习:sheng的学习笔记-AI-半监督学习-CSDN博客 聚类:sheng的学习笔记-AI-聚类(Clustering)-CSDN博客 均值算法:sheng的学习笔记-AI-K均值算法_k均值算法怎么算迭代两次后的最大值-CSDN博客 什么是半监督聚类 聚类是一种典型的无监督学习任务,然而在现实聚类任务中我们往往能获得
使用深度监督策略来优化模型
深度监督策略是一种模型优化的方法,旨在通过在模型的中间层添加辅助监督信号,来帮助模型在训练过程中更好地学习。它不仅仅是一个优化策略,更是一种训练方法,能够提供更多的监督信号,从而加速模型收敛,改善模型性能。 在你的 DSCNN-DS(深度可分离卷积神经网络-深度监督)中,深度监督策略具体表现为: 多级监督:在模型的中间层添加辅助分类器,为中间层的特征提供直接的监督信号,而不仅仅依赖于最后一层的

深度学习基础--监督学习
第二章 监督学习(Supervised Learning) 监督学习模型就是将一个或多个输入转化为一个或多个输出的方式。比如,我们可以将某部二手丰田普锐斯的车龄和行驶里程作为输入,预估的车辆价格则是输出。 这个模型其实只是个数学公式;当我们把输入放入这个公式进行计算,我们得到的结果就是所谓的“推理”。这个公式还包含一些参数。改变参数值会改变计算的结果;这个公式其实描述了输入和输出之间所有可能关

机器学习之监督学习(一)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 机器学习之监督学习(一) 1.监督学习定义2.监督学习分类2.1回归 regression2.2 分类 classification 3.线性回归 linear regression3.1 单特征线性回归补充一:梯度下降 3.2 多特征线性回归补充二:正规方程 normal equation 1.监督学习


sheng的学习笔记-AI-半监督SVM
AI目录:sheng的学习笔记-AI目录-CSDN博客 svm: sheng的学习笔记-AI-支持向量机(SVM)-CSDN博客 半监督学习: sheng的学习笔记-AI-半监督学习-CSDN博客 什么是半监督svm 半监督支持向量机(Semi-Supervised Support Vector Machine,简称S3VM)是支持向量机在半监督学习上的推广。 在不考虑未标记样本时,

【机器学习-监督学习】神经网络与多层感知机
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,依赖于强大的开源库如Scikit-learn、TensorFlow和PyTorch。本专栏介绍机器学习的相关算法以及基于Python的算法实现。

sheng的学习笔记-AI-半监督学习
AI目录:sheng的学习笔记-AI目录-CSDN博客 基础知识 什么是半监督学习 我们在丰收季节来到瓜田,满地都是西瓜,瓜农抱来三四个瓜说这都是好瓜,然后再指着地里的五六个瓜说这些还不好,还需再生长若干天。基于这些信息,我们能否构建一个模型,用于判别地里的哪些瓜是已该采摘的好瓜?显然,可将瓜农告诉我们的好瓜、不好的瓜分别作为正例和反例来训练一个分类器 但如果瓜农无法提供大量的好瓜/不
机器学习概述,深度学习,人工智能,无监督学习,有监督学习,增量学习,预处理,回归问题,分类问题
一、人工智能课程概述 1. 什么是人工智能 人工智能( Artificial Intelligence )是计算机科学的一个分支学科,主要研究用计算机模拟人的思考方式 和行为方式,从而在某些领域代替人进行工作 . 2. 人工智能的学科体系 以下是人工智能学科体系图: 机器学习( Machine Learning ):人工智能的一个子
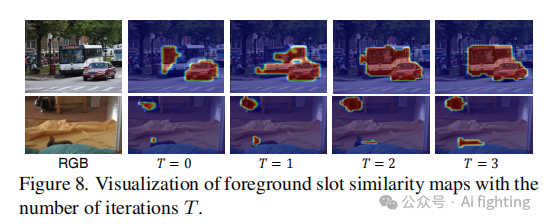
GSANet:使用无监督学习实现视频对象分割
Abstract 无监督视频对象分割的目标是在视频序列中分割出最显著的对象。然而,复杂背景的存在和多个前景对象的出现使这一任务充满挑战。为了解决这个问题,我们提出了一种引导槽注意力网络,以增强空间结构信息并获得更好的前景与背景分离。通过查询引导初始化的前景和背景槽,基于与模板信息的交互对其进行迭代优化。此外,为了改进槽与模板的交互并有效融合目标和参考帧中的全局和局部特征,我们引入了K-近邻过滤
深度学习--自监督学习
自监督学习是一种无需大量人工标注的数据驱动方法,在生成模型中应用广泛。自监督学习通过利用数据中的固有结构或属性创建“伪标签”,使模型在没有人工标签的情况下进行学习。这种方法既提高了模型的训练效率,又降低了对标注数据的依赖。 概念 自监督学习:自监督学习是一种半监督学习的形式,模型通过从未标注的数据中创建自己的监督信号来进行学习。常见的方法包括通过预测数据的一部分来学习(例如,给定图像的部分,预
Google Earth Engine(GEE)——随机森林函数的监督分类使用案例分析
函数: ee.Classifier.smileRandomForest(numberOfTrees, variablesPerSplit, minLeafPopulation, bagFraction, maxNodes, seed) Creates an empty Random Forest classifier. Arguments: numberOfTrees (Integer):