labels专题
![[LeetCode] 763. Partition Labels](/front/images/it_default.jpg)
[LeetCode] 763. Partition Labels
题:https://leetcode.com/submissions/detail/187840512/ 题目 A string S of lowercase letters is given. We want to partition this string into as many parts as possible so that each letter appears in at mo

论文学习—Efficient Multi-label Classification with Many Labels
论文学习:Efficient Multi-label Classification with Many Labels 摘要2. 多标签分类相关工作2.1 Label Transformation1. **降维(Dimensionality Reduction)**2. **回归模型(Regression Model)**3. **逆变换(Inverse Transformation)** 2
OpenCV的setTo函数及Mat mat=labels==1详解
opencv的setTo函数是将图像设置为某个值,比如有一个Mat src,想将他的值全部设置成0,则可以src.setTo(0) 另外,setTo还有更为高级的用法: 1.对于一个已知的src,我们要将其中大于或者小于某个值的像素值设置为指定的值,则可以如下:src.setTo(0,src < 10);这句话的意思是,当src中的某个像素值小于10的时候,就将该值设置成0. 2.

【Pytorch】18.创建自定义数据集并根据文件名或对应文件名的文本文件获取labels
源码 MNIST_Training_By_FileName_Dataset MNIST_Training_By_TXTLabel 简介 本文主要探讨两种不同的数据集获取labels的方法 根据图片的文件名中获取文件标签 根据与图片名称相同的.txt文件获取文件名 根据图片名称获取labels 主要的区别在__init__方法中 def __init

Gym 102452D Defining Labels 进制转换+找规律
https://codeforces.com/gym/102452/problem/D 令k=10, 则1->0,2->1,3->2,4->3,5->4,6->5,7->6,8->9,9->8,10->9,11->00,… 令k=5, 则1->5,2->6,3->7,4->8,5->9,6->55,7->56,8->57,9->58,10->59,11->65,… 再看在五进制下的1到11,为
kubernetes:Labels and Selectors
什么是Lable 标签是附加到对象(如pod)的键/值对。标签用于指定对象的标识属性,这些属性对用户有意义且相关,但不直接向核心系统暗示语义。标签可用于组织和选择对象的子集。标签可以在创建时附加到对象,然后可以随时添加和修改。每个对象都可以定义一组键/值标签。对于给定的对象,每个键必须是唯一的 "metadata": {"labels": {"key1" : "value1","key2" :

UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels
预测的标签中缺少实际的标签。 避免警告的方法如下: import warningswarnings.filterwarnings("ignore")

noisy labels and label smothing
我要看懂这个代码!! import numpy as npimport tensorflow as tfimport matplotlib.pyplot as pltnp.random.seed(0) # for reproducibilityX = np.random.randint(0, 3, (32*1100, 10), np.int32) # inputsY = np.equal(
leetcode【763】Partition Labels(使用贪心算法划分字母区间)
写在最前面: 刷leetcode就像头脑风暴,也是各种算法的灵活运用。 其实介绍一点语法,介绍一个模块的调用相比刷leetcode,做算法轻松太多,用来刷积分,刷文章数再简单不过. 可总要做一点有挑战的事才有意义吧. by the way,我破邮的教室都装上空调了,果然评了双一流就是不一样,反正教研室也没有多的位置,其实我更喜欢一个人自由自在的想一点事情。 一道中等难度的算法
Partition Labels-面试题
题目:分割字符串使得同种字符分隔到一起 A string S of lowercase letters is given. We want to partition this string into as many parts as possible so that each letter appears in at most one part, and return a list of int
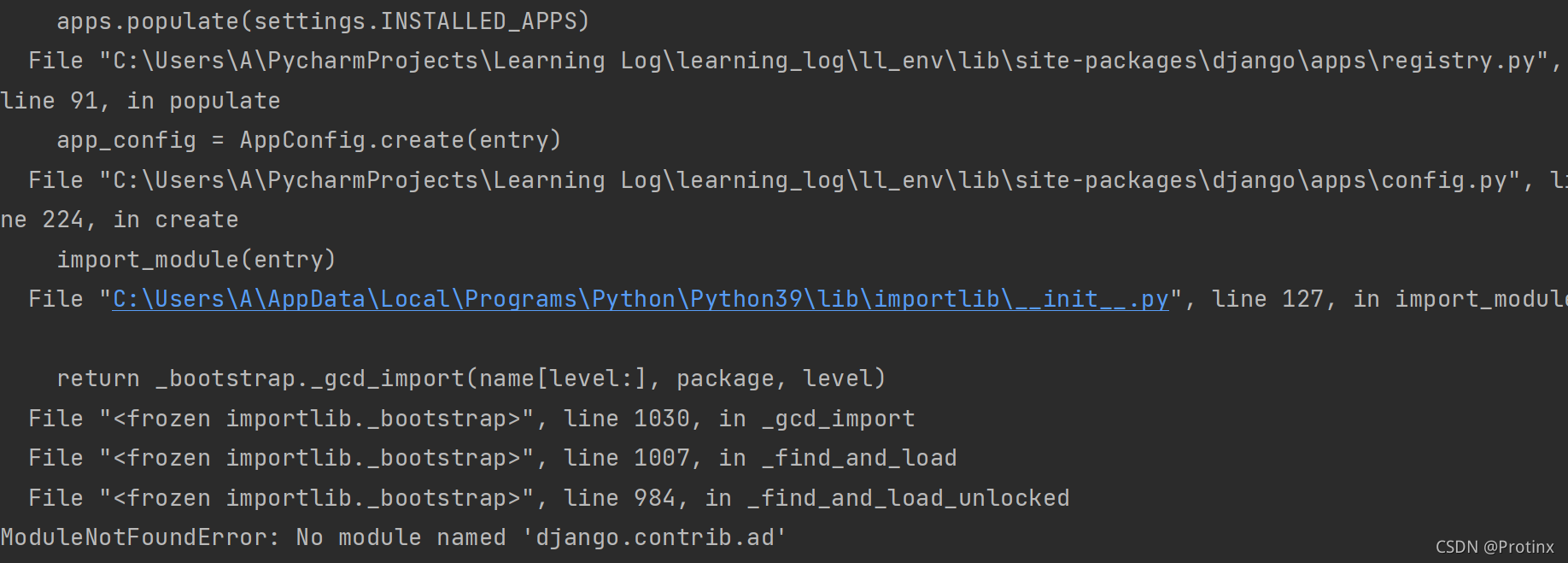
django.core.exceptions.ImproperlyConfigured: Application labels aren‘t unique, duplicates: admin详解
在Django修改数据库,使其能够存储与模型Topic 相 关的信息。为此,在终端窗口中执行下面的命令: python manage.py makemigrations learning_logs 如果出现以下页面: 那么就是说与django自带的‘django.contrib.auth’冲突,所以就会报错 解决办法是:将创建的app重新命名,尽量不要以’admin, au
TensorFlow ValueError Only call softmax_cross_entropy_with_logits with named arguments labels logits
TensorFlow报错: ValueError: Only call softmax_cross_entropy_with_logits with named arguments (labels=…, logits=…, …) 定位到出错点: self.loss = tf.nn.softmax_cross_entropy_with_logits(z, self.target) 原来
【英/中,前端】Form <input> elements must have labels每一个元素应当都有一个标签
原文如下: Form elements must have labels | Axe Rules | Deque University | Deque Systems 编程式的关联标签和窗体控件。 下面以推荐程度从高到低依次排列,使用label元素->使用for和id属性显示关联,就这样。 label标签的包裹 or 不包裹 <label for="firstname">First name:
LeetCode763. Partition Labels
文章目录 一、题目二、题解 一、题目 You are given a string s. We want to partition the string into as many parts as possible so that each letter appears in at most one part. Note that the partition is done

Matplotlib中的titles(标题)、labels(标签)和legends(图例)
Matplotlib是一个Python中常用的绘图库,用于创建各种类型的图表。在Matplotlib中,你可以使用titles(标题)、labels(标签)和legends(图例)来增强你的图表。本文讨论Python的Matplotlib绘图库中可用的不同标记选项。 Figure, subplots 和axes列表 在Matplotlib中,Figure是整个图形窗口,它可以包含一个或多个

Python matplotlib 绘图报错:No handles with labels found to put in legend 解决办法
做数据挖掘降维作业的时候出现问题,红字报错:No handles with labels found to put in legend. 别慌,我估摸着应该是label这个参数少了,百度一下还真的是,我夸我自己 首先我看到的一个博主说是 matplotlib.pyplot .plot 时,没有设置参数label=“xx” 其实,不只是plot这个方法,还有plt.legend()方法,我

Matplotlib制作图例时报错No handles with labels found to put in legend.解决办法
1.问题现象 报错:No handles with labels found to put in legend. 2. 解决办法 1)“画图”时未指定label (如下图,没有红框中的内容) 对应的解决办法:添加上即可 2)制作图例在画图之前,则也会报错 对应的解决办法:先plt.plot(),再plt.legend() 如下图:

IMDB-WIKI – 500k+ face images with age and gender labels论文学习
DEX: Deep EXpectation of apparent age from a single image 这个论文我们使用深度学习解决了在静态人脸图像中面部年龄的估计。我们的卷积神经网络使用了VGG-16结构,并在用于图像分类的ImageNet的数据集上预训练。除此之外,由于面部年龄的注释图像数量的限制,我们探究了微调带有可用年龄的爬取的网络人脸图片的好处。我们从IMDB和Wikipe

VLDB-2020 论文简析:检测和预防众包数据中的混淆标签-Detecting and Preventing Confused Labels in Crowdsourced Data
VLDB2020论文简析:检测和预防众包数据中的混淆标签-Detecting and Preventing Confused Labels in Crowdsourced Data 研究背景研究目标问题挑战作者贡献总体模型1 真值发现器的生成模型2 检测混淆观测的推理算法(MCMC-C)3 基于MV的贪婪算法数据集实验分析困惑/思考 研究背景 如今,众包通常用于解决类似AI相关
k8s metadata.labels,spec.template.metadata.labels,spec.selector 三者之间的关系。
在 Kubernetes 配置文件中,metadata.labels 和 spec.selector 通常在一起使用,。他们起着不同的作用: metadata.labels:这些标签(labels)附加在你创建的对象(例如 Pod、Service、或 Deployment)上。标签是键值对,可以被用来组织和分类这些对象。 spec.selector:这个字段定义了如何找到你想要该 Kuber
[Machine Learning] Learning with Noisy Labels
文章目录 随机分类噪声 (Random Classification Noise, RCN)类别依赖的标签噪声 (Class-Dependent Noise, CCN)二分类多分类 实例和类别依赖的标签噪声 (Instance and Label-Dependent Noise, ILN) 标签噪声是指分类任务中的标签被错误地标记。这可能是由于各种原因,如数据收集错误、主观偏见

论文:learning to propagate labels :transductive propagation network for few-shot learning
论文题目:learning to propagate labels:transductive propagation network for few-shot learning 论文发表:ICLR2019 Github:github.com/csyanbin/TPN 摘要:少样本学习的目标:在少量训练数据下(每个类别的样本很少),学习到一个有较强泛化能力的分类器。一种解决方式就是通过元学习(m

论文笔记《Robust Federated Learning with Noisy Labels》
读论文:Robust Federated Learning with Noisy Labels 应用背景(问题与挑战)相关工作Federated learningLearning on noisy data 解决方案的局限性(motivation) 方案介绍Problem definition and notationsLocal updateslocal clean setnaive av
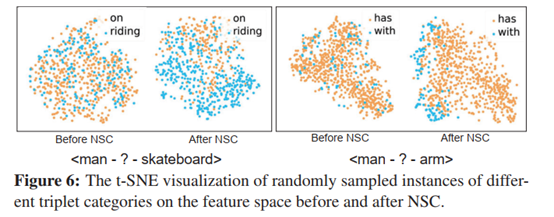
The Devil is in the Labels: Noisy Label Correction forRobust Scene Graph Generation阅读笔记
注:标注、标签、关系的意思相同,指都是的主语宾语间的谓词,样本指 三元组 标题分析 The Devil is inthe Labels:模仿俚语“TheDevil is in the details”概括本文的研究重点:标签。 Noisy LabelCorrection:论文方法,对噪声标签进行修正。 for Robust SceneGraph Generation:论文任务,生成更鲁棒的场景图
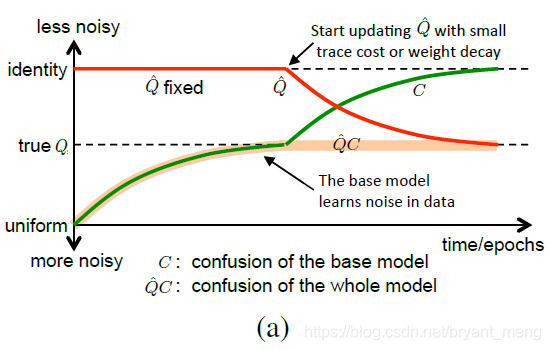
【Noise-Label】《Learning from Noisy Labels with Deep Neural Networks》
arXiv-2014 文章目录 1 Background and Motivation2 Advantages3 Innovations4 Method4.1 Bottom-up Noise Model4.2 Estimating Noise Distribution Using Clean Data4.3 Learning Noise Distribution From Noisy

UnNAS: Are Labels Necessary for Neural Architecture Search?
无监督网络架构搜索 当前业界主流的NAS算法都是利用有监督数据来搜索,然后再用有监督数据(可能和搜索数据不一样)来训练和评估。这篇论文提出一个崭新的方法,利用无监督的数据来搜索架构,称为Unsupervised Neural Architecture Search (UnNAS)。 和其他的NAS算法一样,UnNAS也分成两个阶段:搜索阶段(Search Phase)和评估阶段(Evaluat