本文主要是介绍论文:learning to propagate labels :transductive propagation network for few-shot learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文题目:learning to propagate labels:transductive propagation network for few-shot learning
论文发表:ICLR2019
Github:github.com/csyanbin/TPN
摘要:少样本学习的目标:在少量训练数据下(每个类别的样本很少),学习到一个有较强泛化能力的分类器。一种解决方式就是通过元学习(meta-learning)在有大量训练数据的任务中学习一个通用的泛化能力强的分类器,然后再应用在少数据任务中。文章的一个做法就是在meta-learning的框架中加入传导机制,也就是标签传播来应对少数据的问题。提出Transductive Propagation Network (TPN),对特征嵌入参数和图构建参数进行联合学习。
问题现状:与深度学习需要大量训练样本不同的是现实中人类的学习并不需要学习目标出现多次,如孩子学会“苹果”只需要看几次就能学会。这个情景更符合少样本学习的定义,深度学习中使用fine-tuning的方式会会造成过拟合的情况,是因为样本的分布不同而造成高方差,泛化能力差。
目前解决方法:元学习策略:episodic training,在每个episode包含了训练集和测试集,算法学习有标签的示例(support set)在嵌入空间的表示,通过对未标签集(query set)数据在嵌入空间表示的距离来预测其标签。episodic training模拟了真实场景下少样本数据和未标签数据集的情况,减小数据分布差异,提高泛化能力。这个方法可以缓解泛化能力的缺点,但是数据量太少的问题仍然存在。文章提出使用 transductive inference的思想在episode中对训练集和测试集进行标签传播,应对数据量少的情况,对无标注数据进行标签预测。
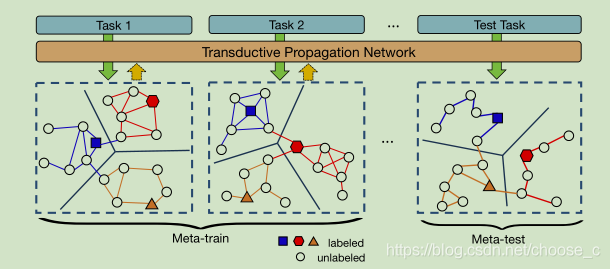
TPN:转导传播网络如图分为4个部分:特征嵌入、图构建、标签传播、损失计算。
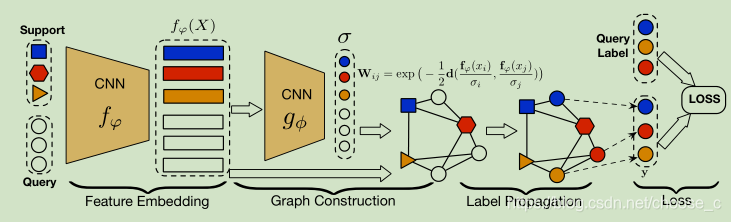
1.特征嵌入:通过CNN网络对输入样本进行特征抽取生成embedding编码,得到support set数据和query set数据在相同特征空间的表示。
2.图构建:图是一个无向图,主要是各个样本节点之间的连接权重计算。通过下面的相似性函数计算权重值。参数δi和δj通过神经网络学习得到。
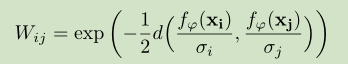
3.标签传播:得到五向图的权重之后,进行标签传播预测query set数据的标签。标签传播的公式如下:
![]()
最后预测标签F*收敛于 ![]() ,S为节点之间的相似性权重,Y为初始标签(初始化),I是单位矩阵。
,S为节点之间的相似性权重,Y为初始标签(初始化),I是单位矩阵。
4.损失计算:通过计算交叉熵损失函数,反向传播更新网络参数。
实验结果:在两个数据集上达到了比较好的效果。同时也对半监督学习也做了实验对比。
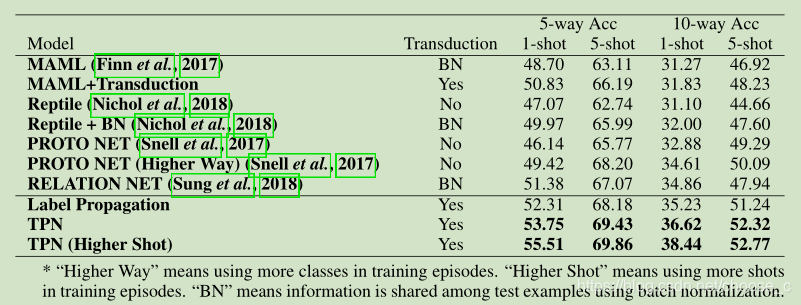
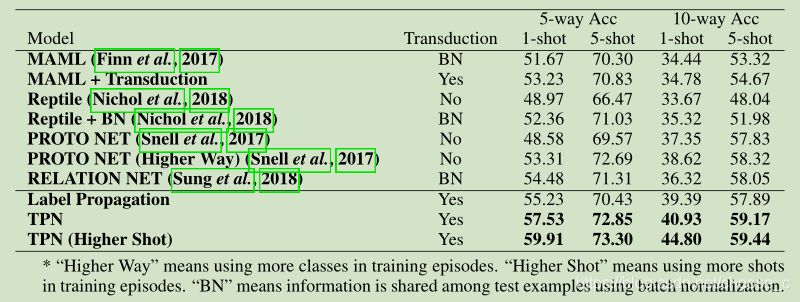

结论:本文提出传导机制用于少样本学习,将TPN网络用于元学习框架,通过特征嵌入、图构建、标签传播、损失计算四个步骤实现端到端的学习。
这篇关于论文:learning to propagate labels :transductive propagation network for few-shot learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
