propagate专题

MountVolume.SetUp: couldn't propagate object cache: timed out waiting for the condition
问题描述 Kubernetes 集群某个节点无法正常启动 Pod,一直呈 ContainerCreating 状态 查看 Pod 状态,报类似如下错误: Warning FailedMount 39m kubelet, node1.example.com MountVolume.SetUp failed for volume "default-token-f622k" : cou
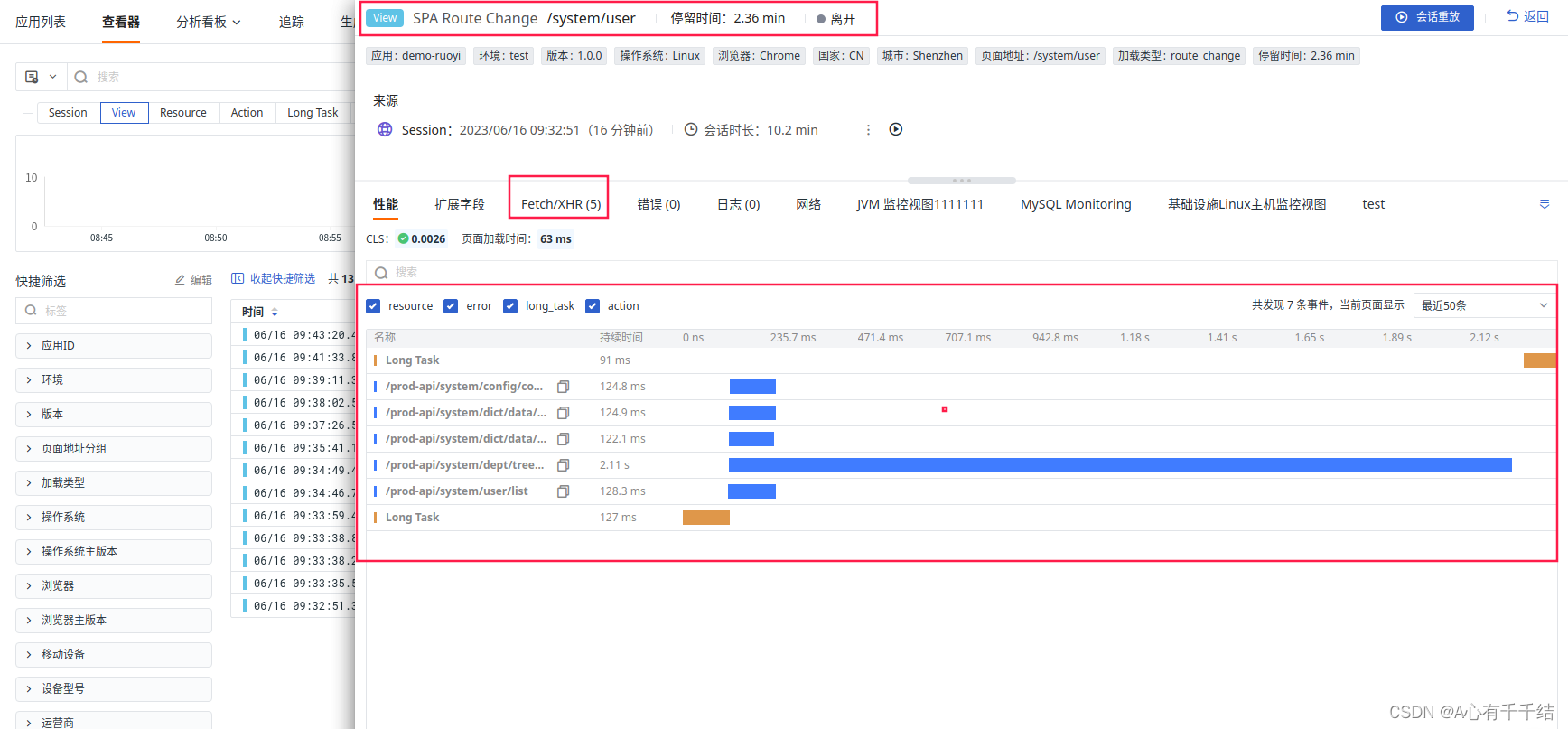
链路传播(Propagate)机制及使用场景
服务间链路追踪传播机制是指在微服务架构中,通过记录和跟踪服务之间的请求和响应信息,来实现对服务间链路的追踪和监控。这种机制可以帮助开发人员快速定位服务间出现的问题,并进行优化和调整。 具体来说,服务间链路追踪传播机制可以通过在每个服务的请求和响应中添加唯一标识符来实现。当一个服务发送请求到另一个服务时,它会将自己的唯一标识符添加到请求头中,并发送给目标服务。目标服务收到请求后,会将请求头中的唯一
aqs中关于propagate状态的思考
https://blog.csdn.net/cq_pf/article/details/113387256?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-113387256-blog-110535122.pc_relevant_default&spm=100

AQS源码深入分析之共享模式-你知道为什么AQS中要有PROPAGATE这个状态吗?
本文基于JDK-8u261源码分析 本篇文章为AQS系列文的第二篇,前文请看:[传送门] 第一篇:AQS源码深入分析之独占模式-ReentrantLock锁特性详解 1 Semaphore概览 共享模式就是有多个线程可以同时拿到锁资源,共享模式用Semaphore来举例,其与ReentrantLock的结构类似,也有公平和非公平两种模式: 1 public class Se
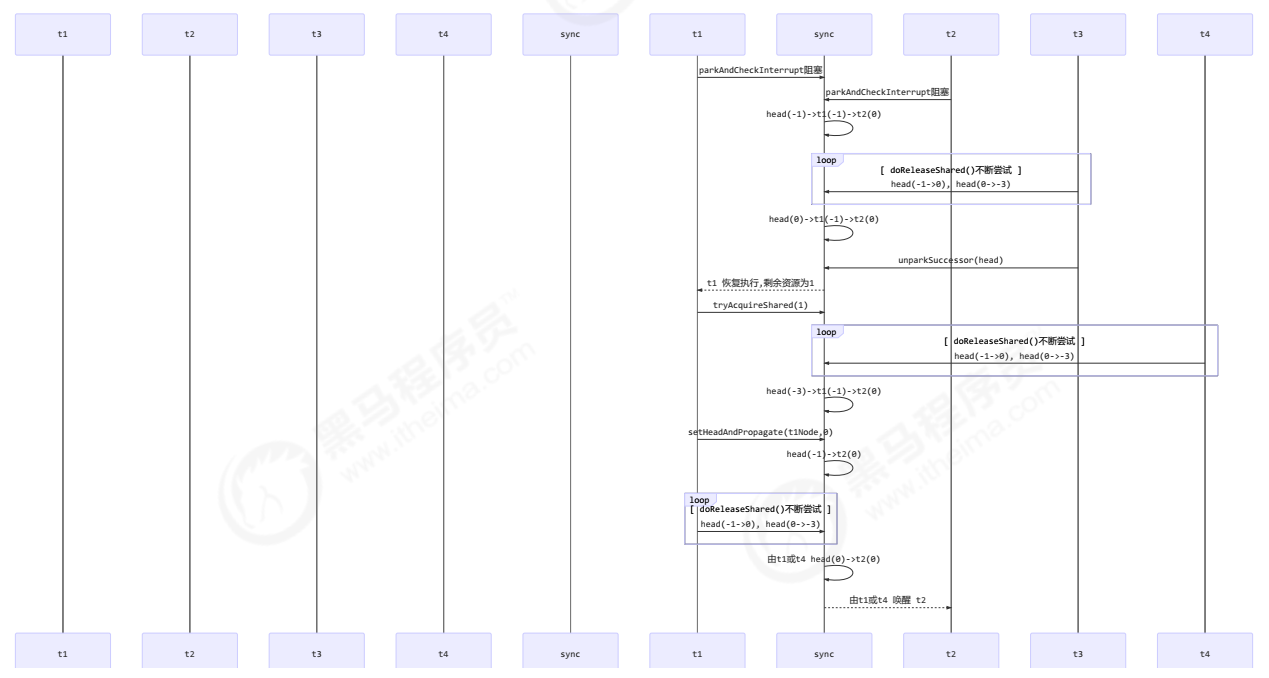
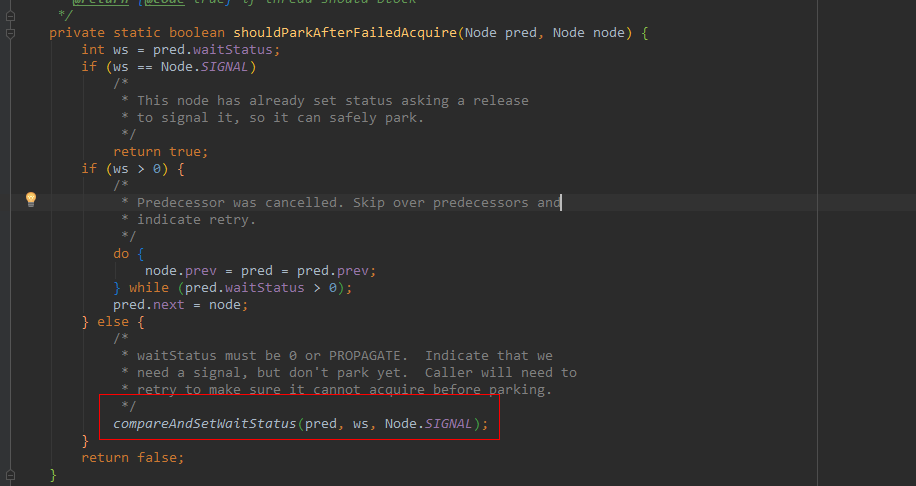
源码解析AQS的PROPAGATE有什么用?
文章目录 AQS的PROPAGATE有什么用?bug修复前的代码(Java 5)正常流程产生 bug 的情况 bug 修复后的代码 (java 7) AQS的PROPAGATE有什么用? waitStatus=PROPAGATE值为-3,当前线程处在SHARED共享模式下,该字段才会使用 比如信号量Semaphore,读写锁ReentrantReadWriteLock的读
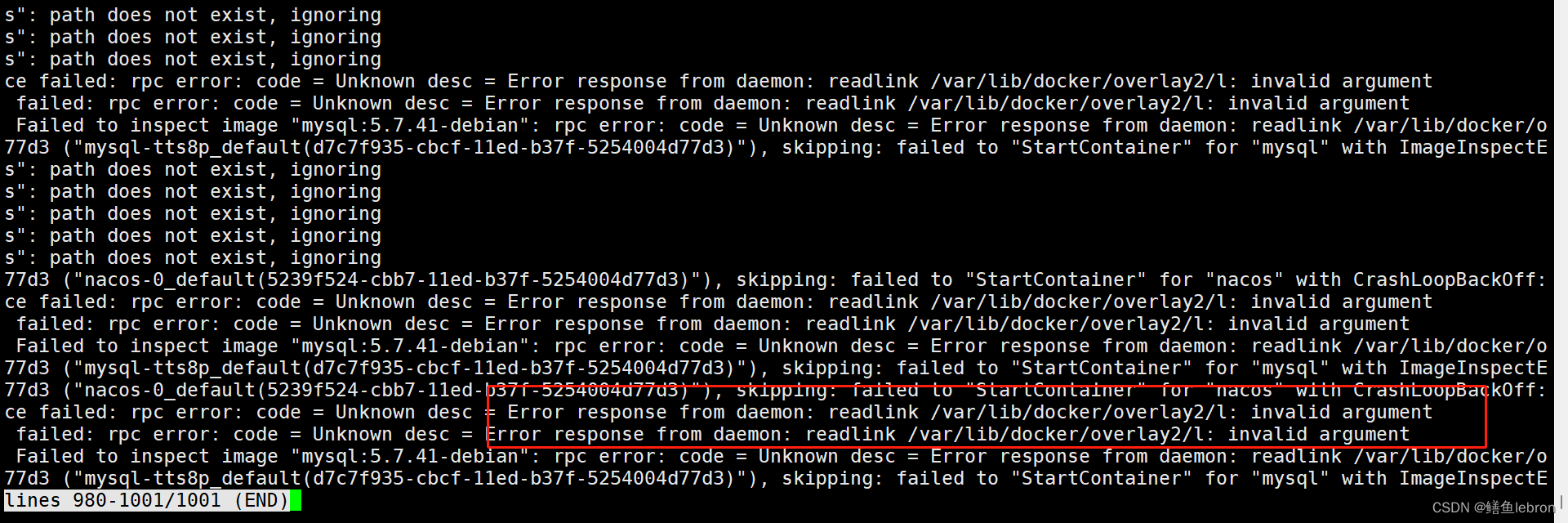
BS问题:MountVolume.SetUp failed for volume “default-token-7pl9w“ : couldn‘t propagate object cache: ti
K8S部署MySQL 运行一段时间之后,打开虚拟机就这样了 MountVolume.SetUp failed for volume "default-token-7pl9w" : couldn't propagate object cache: timed out waiting for the condition 描述一下: kubectl describe pod mysql-tts
面试官问我AQS中的PROPAGATE有什么用?
之前分析过AQS的源码,但只分析了独占锁的原理。 而刚好我们可以借助Semaphore来分析共享锁。 如何使用Semaphore public class SemaphoreDemo {public static void main(String[] args) {// 申请共享锁数量Semaphore sp = new Semaphore(3);for(int i = 0; i < 5;

《Predict then Propagate: Graph Neural Networks meet Personalized PageRank》论文阅读笔记
文章:Predict then Propagate: Graph Neural Networks meet Personalized PageRank 出处:ICLR 2019 作者:Johannes Klicpera, Aleksandar Bojchevski & Stephan Gunnemann 机构:Technical University of Munich, Germany

PREDICT THEN PROPAGATE: GRAPH NEURAL NETWORKS MEET PERSONALIZED PAGERANK
Motivation 传统GCN在节点分类中达到了不错的效果,但只能在将层数限制在2-3层,加深层数会导致两个问题: (1)、出现过平滑现象:即最后所有节点趋向同一个值。 (2)、随着层数的加深,参数量也呈指数级增长。 但是试验表明,一般要将层数达到4-5层才能使才能覆盖所有的节点。 为了解决这个问题,引进了PageRank方法。 问题一 由于PageRand方法可能陷入“陷阱问题”和“终止

图神经网络(十九)PREDICT THEN PROPAGATE: GRAPH NEURAL NETWORKS MEET PERSONALIZED PAGERANK
本文收录于ICLR2019,作者来自于慕尼黑工业大学。这篇文章说的还是GCN的邻域无法扩展的问题,因此作者利用GCN和PageRank之间的关系,推导出一种基于个性化PageRank的改进传播方案,利用这个传播方案构造了一个简单的模型:个性化的神经预测传播(PPNP)及其快速逼近(APPNP)。该模型需要使用较少的训练时间和较少的参数数量,实验表明,该模型的性能提升较为明显。在看这篇文章之前,可以
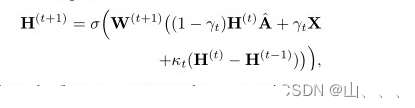
Why Do Attributes Propagate in Graph Convolutional Neural Networks?
这篇论文是收录在The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21)上面关于图神经网络的一篇论文。我看完的感觉是,真的很厉害了!内容很多,看完收获满满! 这篇论文解决了什么问题?? 1. 解释了GNN中传播的本质 2.提出了一个新的GNN模型——GCCN 这篇论文采用什么方法解决这个问题的? 1

论文:learning to propagate labels :transductive propagation network for few-shot learning
论文题目:learning to propagate labels:transductive propagation network for few-shot learning 论文发表:ICLR2019 Github:github.com/csyanbin/TPN 摘要:少样本学习的目标:在少量训练数据下(每个类别的样本很少),学习到一个有较强泛化能力的分类器。一种解决方式就是通过元学习(m

MuleSoft知识总结-22.Mule组件,错误处理(Try,On Error Continue,On Error Propagate)
文章目录 前言TryOn Error ContinueOn Error Propagate 前言 在《MuleSoft自学分享-21.Mule组件(Until Successful)》我们尝试使用Until Successful组件,在Request请求失败时以一定间隔时间重新发送请求(请求成功时不会调用)。同时我们产生了一个新的问题——如何捕获错误,其实在导入Design Ce