shot专题

SAM2POINT:以zero-shot且快速的方式将任何 3D 视频分割为视频
摘要 我们介绍 SAM2POINT,这是一种采用 Segment Anything Model 2 (SAM 2) 进行零样本和快速 3D 分割的初步探索。 SAM2POINT 将任何 3D 数据解释为一系列多向视频,并利用 SAM 2 进行 3D 空间分割,无需进一步训练或 2D-3D 投影。 我们的框架支持各种提示类型,包括 3D 点、框和掩模,并且可以泛化到不同的场景,例如 3D 对象、室

速通GPT-3:Language Models are Few-Shot Learners全文解读
文章目录 论文实验总览1. 任务设置与测试策略2. 任务类别3. 关键实验结果4. 数据污染与实验局限性5. 总结与贡献 Abstract1. 概括2. 具体分析3. 摘要全文翻译4. 为什么不需要梯度更新或微调⭐ Introduction1. 概括2. 具体分析3. 进一步分析 Approach1. 概括2. 具体分析3. 进一步分析 Results1. 概括2. 具体分析2.1 语言模型

《Zero-Shot Object Counting》CVPR2023
摘要 论文提出了一种新的计数设置,称为零样本对象计数(Zero-Shot Object Counting, ZSC),旨在测试时对任意类别的对象实例进行计数,而只需在测试时提供类别名称。现有的类无关计数方法需要人类标注的示例作为输入,这在许多实际应用中是不切实际的。ZSC方法不依赖于人类标注者,可以自动操作。研究者们提出了一种方法,可以从类别名称开始,准确识别出最佳的图像块(patches),用

One-Shot Imitation Learning
发表时间:NIPS2017 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=4557560538297540609¬eId=2424799047081637376 作者单位:Berkeley AI Research Lab, Work done while at OpenAI Yan Duan†§ , Marcin Andrychow

One-Shot Imitation Learning with Invariance Matching for Robotic Manipulation
发表时间:5 Jun 2024 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=2408639872513958656¬eId=2408640378699078912 作者单位:Rutgers University Motivation:学习一个通用的policy,可以执行一组不同的操作任务,是机器人技术中一个有前途的新方向。然而,

零样本学习(zero-shot learning)——综述
-------本文内容来自对论文A Survey of Zero-Shot Learning: Settings, Methods, and Applications 的理解和整理,这里省去了众多的数学符号,以比较通俗的语言对零样本学习做一个简单的入门介绍,用词上可能缺乏一定的严谨性。一些图和公式直接来自于论文,并且省略了论文中讲的比较细的东西,如果感兴趣建议还是去通读论文 注1:为了方便,文中
![[论文笔记]Single Shot Text Detector with Regional Atterntion](https://img-blog.csdn.net/20171130092242746?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzI1MDQxNg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
[论文笔记]Single Shot Text Detector with Regional Atterntion
Single Shot Text Detector with Regional Atterntion 论文地址:https://arxiv.org/abs/1709.00138 创新点: 提出an atterntion mechanism,也就是an automatically learned attention map,从而实现抑制背景干扰。 模型架构: -text-sp

【王树森】Few-Shot Learning (2/3): Siamese Network 孪生网络(个人向笔记)
Learning Pairwise Similarity Scores Training Data 训练集有很多个类别的图片,每个类别的图片都有标注 Positive Sample:我们需要正样本来告诉神经网路什么东西是同一类 Negative Sample:负样本可以告诉神经网路事物之间的区别 我们用CNN来提取图片的特征: 把两张图片用同一个CNN提取特征向量,然后把得到的

【论文阅读】skill code 和 one-shot manipulate
文章目录 1. Interpretable Robotic Manipulation from Language针对痛点和贡献摘要和结论引言模型框架实验思考不足之处 2. One-Shot Imitation Learning with Invariance Matching for Robotic Manipulation针对痛点和贡献摘要和结论引言模型框架实验 1. Inte

One-Shot Visual Imitation Learning via Meta-Learning
发表时间:CoRL 2017 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=4667206488817680385¬eId=2408726470680795136 作者单位:University of California, Berkeley Motivation:为了使机器人成为可以执行广泛工作的通才,它必须能够在复杂的非结构化

Behavior Retrieval: Few-Shot Imitation Learning by Querying Unlabeled Datasets
发表时间:13 May 2023 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=1900983943467731200¬eId=2446646993511259136 作者单位:Stanford University Motivation:使机器人能够以数据有效的方式学习新的视觉运动技能仍然是一个未解决的问题,有无数的挑战。解决这

论文辅助笔记:Large Language Models are Zero-Shot Next LocationPredictors
论文理论部分:论文笔记:lunLarge Language Models are Zero-Shot Next LocationPredictors-CSDN博客 2 Data 2.1 Dataset类 2.2 下载文件 2.3 get_dataset 2.4 get_trajectories trajectory_split暂时略去 # save the tes

SSD: Single Shot MultiBox Detector解读
此SSD非彼SSD,不过都有一个特点快,我之前读过了这篇,这次算是重温,而且前面介绍了很多检测网络,尤其是FPN时更是对SSD有一个很根本的解读,所以这篇博客算是一个SSD精华介绍,哈哈。 贡献和特点 SSD最大的贡献,就是在多个feature map上进行预测,这点我在上一篇FPN也说过它的好处,可以适应更多的scale。第二个是用小的卷积进行分类回归,区别于YOLO及其faster

【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
目录 一、引言 二、零样本物体检测(zero-shot-object-detection) 2.1 概述 2.2 技术原理 2.3 应用场景 2.4.1 pipeline对象实例化参数 2.4.2 pipeline对象使用参数 2.4 pipeline实战 2.5 模型排名 三、总结 一、引言 pipeline(管道)是huggingface trans

vllm 部署GLM4模型进行 Zero-Shot 文本分类实验,让大模型给出分类原因,准确率可提高6%
文章目录 简介数据集实验设置数据集转换模型推理评估 简介 本文记录了使用 vllm 部署 GLM4-9B-Chat 模型进行 Zero-Shot 文本分类的实验过程与结果。通过对 AG_News 数据集的测试,研究发现大模型在直接进行分类时的准确率为 77%。然而,让模型给出分类原因描述(reason)后,准确率显著提升至 83%,提升幅度达 6%。这一结果验证了引入 reas
![[LightOJ 1292] Laser Shot (几何,判断共线)](/front/images/it_default.jpg)
[LightOJ 1292] Laser Shot (几何,判断共线)
LightOJ - 1292 刚开始写的时候是O( n3log(n) n^3log(n))的,枚举两个点,得到一条直线,用set记录下来,然后再 O( n n)地计数,居然没有卡过 orz 听了学长的教导,get到一个几何常用思路,正确解法如下 枚举一个点,再枚举其他点,计算到这个点的斜率,make_pair(dx,dy)塞到map里,把相同斜率的计数一下 这样时间复杂度为 O(n2log

【深度学习】GPT-3,Language Models are Few-Shot Learners(一)
论文: https://arxiv.org/abs/2005.14165 摘要 最近的研究表明,通过在大规模文本语料库上进行预训练,然后在特定任务上进行微调,可以在许多NLP任务和基准上取得显著的进展。虽然这种方法在结构上通常是任务无关的,但仍然需要数千或数万个示例的任务特定微调数据集。相比之下,人类通常可以通过少量示例或简单指令来执行新的语言任务,而当前的NLP系统在这方面仍然存在很大困难。

【机器学习300问】113、什么是One-Shot学习?它和传统机器学习有什么不同?
一、简要解释什么One-Shot学习? One-Shot学习是计算机视觉领域中一种学习范式,它允许机器学习模型仅凭一个样本就能识别并学习一个新的类别。 二、One-Shot学习与传统机器学习方法的主要区别是什么? 在传统的监督式学习中,模型通常需要大量的样本去学习如何区分不同的类别。而One-Shot学习的目标是使模型具有更强的泛化能力,使其在遇到未曾见过类别

论文笔记:Frozen Language Model Helps ECG Zero-Shot Learning
2023 MIDL 1 intro 心电图(ECG)被广泛应用于检测各种心脏疾病,包括心律失常、心脏病发作和心力衰竭等近些年深度学习方法在心电图数据分类领域取得了不错的效果。 基于深度学习的ECG数据分类方法,通常以监督学习范式进行训练,需要大量的高质量标记数据一些特殊形式的心电图数据往往难以获得准确的数据标签,需要受过专业培训的心脏病专家对心电图进行手动解释,耗费大量时间及成本 ——>部分研
zero shot,few shot以及无监督学习之间的关系是什么
Zero-shot learning、few-shot learning和无监督学习都是机器学习中的方法,它们共同的特点是在有限或没有标签数据的情况下进行学习。下面是这三种方法之间的关系和区别: Zero-shot Learning (零样本学习): 零样本学习是在模型训练过程中完全没有见过任何标签数据的类别的情况下,让模型能够识别新类别的方法。这通常通过利用类别之间的关系或属性来实现。例如,
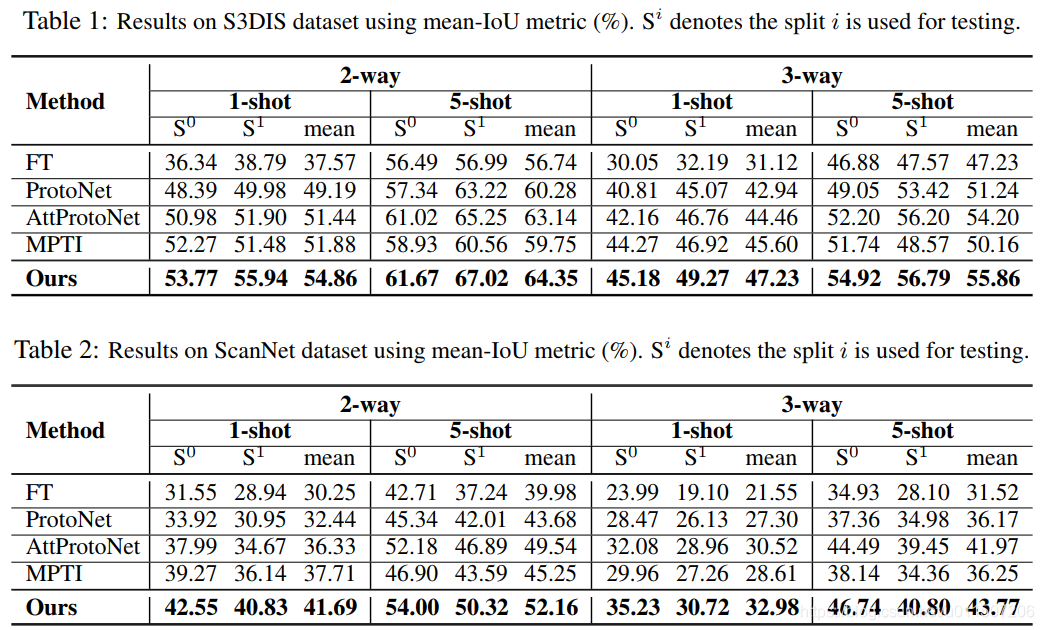
Few-shot 3D Point Cloud Semantic Segmentation 论文简记
Few-shot 3D Point Cloud Semantic Segmentation 论文简记 摘要 已有的点云语义分割方法需要大量的标签,点云逐点标记是困难的,另外对新的类别较差的泛化性。因此本文提出一个显著感知的多原型转化few-shot 分割方法。 具体地,每个类可以表示为多个原型来建模复杂分布地点云数据。然后,设计一个标签传播方法,来探索标注点和未标记点的多原型亲和度,以及未标注

基于Zero-shot实现LLM信息抽取
基于Zero-shot方式实现LLM信息抽取 在当今这个信息爆炸的时代,从海量的文本数据中高效地抽取关键信息显得尤为重要。随着自然语言处理(NLP)技术的不断进步,信息抽取任务也迎来了新的突破。近年来,基于Zero-shot(零样本学习)的大型语言模型(LLM)在信息抽取领域展现出了强大的潜力。这种方法能够在没有预先标注数据的情况下,通过理解自然语言指令来完成信息抽取任务,极大地提高了
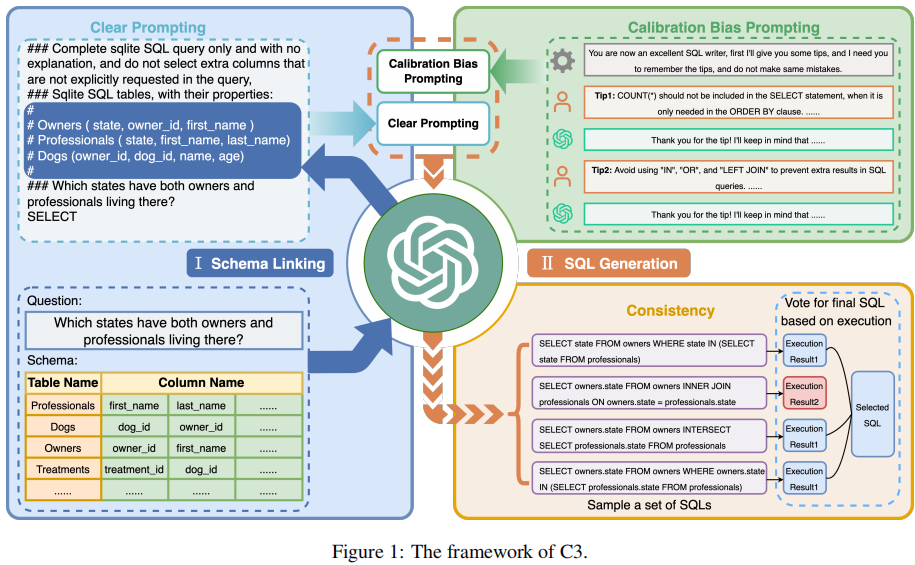
【Text2SQL 论文】C3:使用 ChatGPT 实现 zero-shot Text2SQL
论文:C3: Zero-shot Text-to-SQL with ChatGPT ⭐⭐⭐⭐ arXiv:2307.07306,浙大 Code:C3SQL | GitHub 一、论文速读 使用 ChatGPT 来解决 Text2SQL 任务时,few-shots ICL 的 setting 需要输入大量的 tokens,这有点昂贵且可能实际不可行。因此,本文尝试在 zero-shot 的

内涵:single shot multibox shot 在自己的数据上训练自己的模型
推荐两篇非常非常非常好的两篇文章: 1、如何把自己的数据制作为VOC格式的xml标签 http://www.itkeyword.com/doc/4119351835022951846/rcnn-pascal-voc 2、如何用VOC格式的数据训练SSD模型 http://blog.csdn.net/10km/article/details/70168526 可能会踩到的坑:OpenCV Erro
论文阅读:《A Deep Relevance Model for Zero-Shot Document Filtering》
ACL 2018 一种用于零样本文档过滤的深度相关性模型 A Deep Relevance Model for Zero-Shot Document Filtering 武汉大学、阿里巴巴集团 Wuhan University、Alibaba Group 【摘要】在大数据时代,能否在短时间内针对某些主题的文档信息进行分析是非常重要的需求,而信息过滤是实现这一目标不可或缺的任务之一。本

论文笔记丨FewRel 2.0: Towards More Challenging Few-Shot Relation Classification
作者:凯 单位:燕山大学 code:https://github.com/thunlp/fewrel paper:https://www.aclweb.org/anthology/D19-1649.pdf FewRel 2.0: Towards More Challenging Few-Shot Relation Classification 问题介绍FewRel 2.0BE