本文主要是介绍Few-shot 3D Point Cloud Semantic Segmentation 论文简记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Few-shot 3D Point Cloud Semantic Segmentation 论文简记
摘要
已有的点云语义分割方法需要大量的标签,点云逐点标记是困难的,另外对新的类别较差的泛化性。因此本文提出一个显著感知的多原型转化few-shot 分割方法。
具体地,每个类可以表示为多个原型来建模复杂分布地点云数据。然后,设计一个标签传播方法,来探索标注点和未标记点的多原型亲和度,以及未标注点之间的亲和度。最后,显著感知的多尺度特征学习网络建模点之间的语义相关性和几何相关性。
1. 解决关键问题
- 推广到新的类别 s.t. 不需要强的监督信号,并且生成新的类别。
- 目前一些弱监督或者半监督的方法忽略了泛化性的问题,即使使用元学习策略也会面临两个关键问题:1)从支持集中学到可表示新类的可区别性的特征是困难的;2)如何有效这些特征表示信息进行细分类。
2. 方法思路简记
本文主要是利用元学习的方法,预训练网络,在支撑集和查询集上进行fine-tunning。
下面以3-Way 5-Shot 为例说明论文的主要方法:根据类别信息(首字母顺序)划分训练集和测试集。划分支撑集和查询集,支撑集包含3个类别的点云(还包含属于该类别点的mask),每个类别5个样本。查询集中有T个样本和对应标签。训练过程是通过S集来预测Q集中每个点的类别分布:S集和Q集分别通过Embedding网络提取特征。在Embedding中对DGCNN加入attention,其实就是一种空间attention。提取到了每个点云中每个点的特征。作者认为一个Prototype不能很好的表示点云的类,所以引入多个Prototype。因此,就需要一个多Prototype生成器。根据这些Prototype要挖掘S和Q以及S-S,Q-Q之间的特征相似性,引入了KNN graph。通过构建的相似性来预测Q的标签,Q的标签和真实的标签提供交叉熵损失来训练网络。
结构入下:
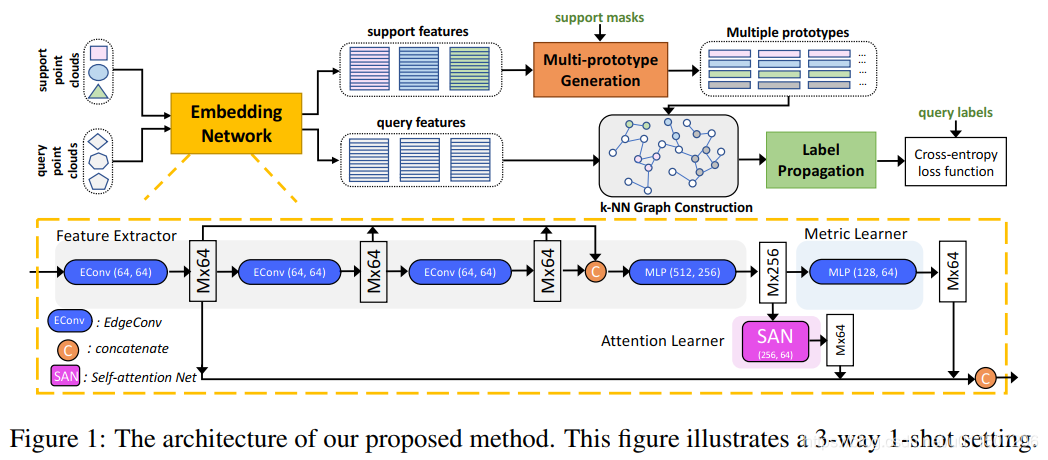
多Prototype生成器:作者将其转为一个聚类问题解决,通俗一些:随机种子数(n个),特征最远距离方法获取n个簇中心,在特征空间中计算每个点应该分配到哪个种子表示的簇上(距离近),该簇对应点的特征均值就是一个Prototype,于是就有了n个prototype。相当于对之前的方法直接求均值变为了对最大距离分布的特征簇的均值。
标签传播:构建一个类内和类间的图(KNN),相似度矩阵是所有类别的n个原型和所有查询点(T个样本,每个样本M个点)相互之间的相似度(高斯相似度),相应的生成所有点的标签。对其正则化,约束预测的标签分布。
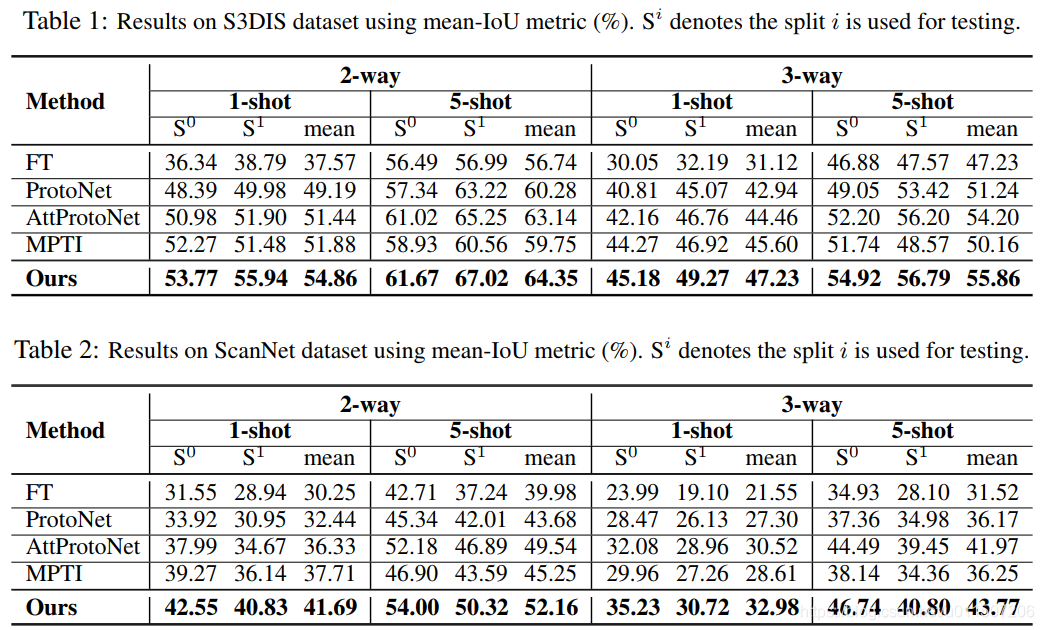
3. 实验结果:
这篇关于Few-shot 3D Point Cloud Semantic Segmentation 论文简记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








