本文主要是介绍The Devil is in the Labels: Noisy Label Correction forRobust Scene Graph Generation阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:标注、标签、关系的意思相同,指都是的主语宾语间的谓词,样本指
三元组
标题分析
The Devil is inthe Labels:模仿俚语“TheDevil is in the details”概括本文的研究重点:标签。
Noisy LabelCorrection:论文方法,对噪声标签进行修正。
for Robust SceneGraph Generation:论文任务,生成更鲁棒的场景图,鲁棒的场景图生成。
动机
数据集中,GT的关系标注存在两种不合理的情况:
标注出的关系不一定合适(噪声正样本)。
图像中,存在部分切实出现但未被标注关系(噪声负样本)。

图1数据集中三种噪声标签示意图
图1是对数据集标注不合理的进一步解释,(a)类称为“倾向于笼统的样本”,数据集仅仅是用on,near,in(a中红色字体)作为GTrelation,不采用信息量更多也更合理的关系(a中绿色字体),(b)类称为“同义词随机的样本”,对于有同义词的关系(man和shirt的关系可以是has或with,表达的意思是一样的),数据集随机取一种关系作为GT,影响了SGG模型的表现,两张t-SNE图是使用论文方法前后,对数据集中谓词has和with特征的可视化。(a)和(b)中的错误关系统称为噪声正样本。(c)为噪声负样本,指的是数据集未标注出的潜在关系。数据集中的这些噪声样本妨碍了SGG模型的训练,也会影响在测试集上的实验结果。
论文提出模型通用的噪声标签纠正方法(modelagnosticNoIsy label CorrEction,NICE)检测噪声标签并纠正,主要包含三部分:negative NoisySample Detection (Neg-NSD),positive NSD (Pos-NSD),and Noisy Sample Correction (NSC),实验结果表明与原始数据集训练模型相比,使用改进后数据集的模型表现更好,并且在多种类型的模型上进行实验发现,这种提升无关模型种类,证明本文方法的泛化能力很强。
贡献
首次指出SGG数据集GT中出现的两个不合理的情况:1)默认所有被标出的正样本都是合理的2)默认图像背景中不存在未被标注出的样本。
提出解决方法NICE,提高了SGG数据集中样本的质量,并通过实验验证了本文方法的可行性及可泛化性。
方法概述
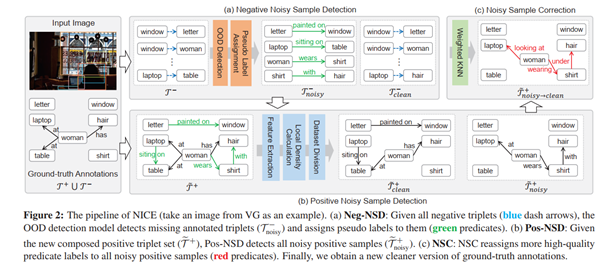
图2NICE处理过程
顺序:Input -->Neg-NSD-->Pos-NSD-->NSC -->Output
图2以一张输入图像为例,输入图像的样本集合记为τ,由正样本集合τ+和负样本集合τ-组成,先通过Neg-NSD检测出τ-中被忽略的关系(噪声负样本集τnoisy-),并为τnoisy-中每个样本分配一个伪标签,随后将τnoisy-与τ+组成新的正样本集合τ+并输入Pos-NSD中,使用聚类算法得到噪声正样本集τnoisy+,对τnoisy+在NSC中经过权重KNN(wKNN)纠正,最后输出由noisy变clean的样本集合,遍历整个数据集图像,得到质量更高的数据集。
具体方法
Negative Noisy Sample Detection (Neg-NSD)
输入:负样本集合τ-
输出:负样本子集τclean-和噪声负样本集τnoisy-
Neg-NSD由两个分支组成:
1. 分类分支:Neg-NSD预测负样本ti-主语与宾语之间标签的类别概率分布p,p中的类别与正样本集合τ+包含的类别(称为正谓词类别)相同。
2. 置信度分支:预测负样本ti-集合是前景(有relation)的概率,称为置信度分数ci∈[0,1],同时设定阈值θ,若样本i的置信度分数大于阈值θ就认为该样本是噪声负样本。

当置信度大于阈值时取

,此时认为样本ti-为噪声负样本,并将对样本ti-预测的p中概率最大的标签(对应概率记作pi)作为ti-该样本的伪标签。
Training of Neg-NSD:Neg-NSD将正样本集合τ+作为训练集,预测τ+中的样本是前景的置信度分数ci,并给出概率最大值pi,将预测概率pi和在τ+中与pi类别相同的预测概率yi组合为新的概率pi',pi'通过置信度分数调整两概率的权重。
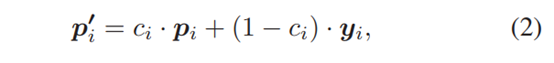
损失函数由交叉熵损失和惩罚损失组成
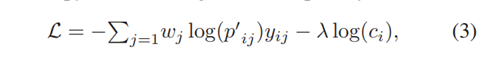
wj是第j个谓语类别的频率的倒数。对(2)的理解:当Neg-NSD不确定样本i的标签是不是pi对应的类别时,会按照GT的预测概率判断Neg-NSD的错误有多严重,并调整交叉熵损失大小。惩罚损失防止Neg-NSD为了最小化损失L而将ci恶意压低的情况出现。
Positive Noisy Sample Detection (Pos-NSD)
输入:新的正样本集合τ+(τ+∪τnoisy-)
输出:噪声正样本集合τnoisy+和正样本子集τclean+
使用聚类算法将τ+分成多个子集,把最noisy的子集作为噪声正样本集。
理论支撑:如果一个样本和同类别视觉相似的样本的特征保持一致,可以确定该样本是正样本,比如下面这张图,在左侧分布图上的两个相似的window in room特征距离很近,但window in room与people in elephant这种预测错误的样本in的特征距离会很远。
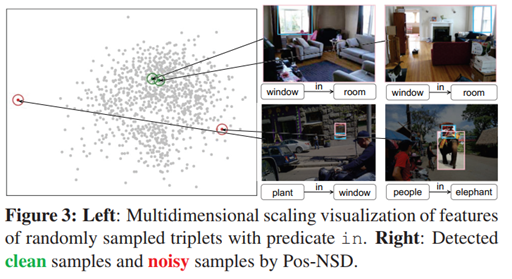
图3对含有谓词in的三元组特征的可视化
由此,计算类别为k的第i个样本与第j个样本视觉特征的欧氏距离
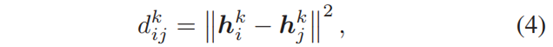
hik表示类别为k的第i个样本的特征,||·||计算的欧氏距离,dijk可以表示特征相似程度,越小说明ij样本i与j越相似,随后计算能衡量样本i噪声程度的值ρik
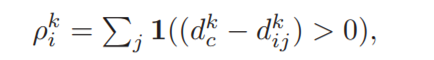
设定距离阈值dck,对所有k类别的dijk(假设共n个距离值)从小到大排序,dck取第(n*α%)个距离。根据公式可知ρik越大,样本i越不可能是噪声正样本类。对τ+中样本分别计算ρik(每个样本的值简称为ρ),根据K-means算法按ρ值大小分成多个子集(汇集ρ相同的样本到一起),把ρ值最小的这些样本(最noisy)视为噪声正样本送入NSC内纠正。
Noisy Sample Correction (NSC)
输入:噪声正样本集合τnoisy+
输出:纠正后正样本集合τnoisy→clean+
相同标签样本的特征应该保持一致,尤其在主语宾语相同的时候。
论文采用带有权重的k近邻(weightedK-Nearest Neighbor,wKNN)算法纠正噪声正样本,为噪声正样本重新分配标签的计算过程如下:
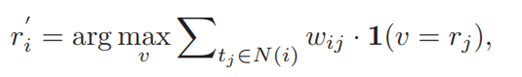
N(i):样本ti按特征距离取的K个邻居样本形成的集合
v:预测类别
rj:样本tj的谓词标签
1(·):indicator function 事件发生时置1
wij:为每个邻居分配到权重计算公式为,abc均为超参,ti与tj特征距离越小,分配的权重就越大。
公式的理解:在类别集合中(可能有in at on...)选择一个,假设找了“at”,遍历邻居集合,找到属于at类别的样本就加1(但可能离得近也可能离的远,所以要乘权重),最后得到一个值。遍历v中所有类别,取最大的值对应的类别作为噪声正样本的类别。
实验
数据集:VG数据集,总共包含108,073张图片。本文保留150个最频繁的对象类别和50个最频繁的谓词类别。数据集中70%的图像是训练集,30%的图像是测试集。根据训练集的样本数量,将所有谓词类别分为三部分:头部(>10k),身体(0.5k∼10k),和尾部(<0.5k)。
任务:1) 谓词分类(PredCls)。给定带有标签的GT框,只需预测谓词类别。2) 场景图分类(SGCls):给定目标的GT框,预测目标类别和谓词类别。3)给定一个图像,预测目标边界框,并预测目标类别和谓词类别。
评价指标:1)Recall@K(R@K),计算按置信度排序的top-K个三元组中预测正确三元组的比例,K={50,100}。2)meanRecall@K(mR@K),分别计算每个谓词类别的召回率,然后对所有谓词的R@K进行平均,更强调尾部的类别。3)Mean,mR@K和R@K分数的平均值。R@K倾向于头部谓词,而mR@K倾向于尾部谓词,Mean可以反映模型在不同谓词上的表现。
性能实验
baseline:Motifs &VCTree
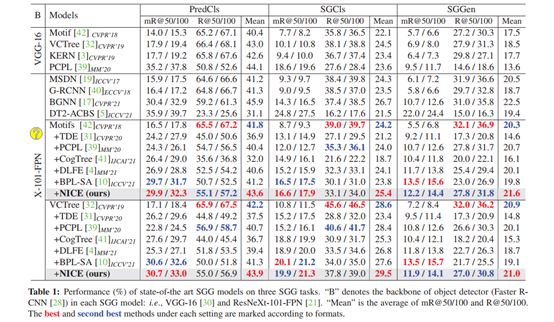
如表1(红色第一,蓝色第二),与两个baseline(即Motifs和VCTree)相比,NICE可以在三个任务中提高模型在mR@K上的性能。与其他模型相比,NICE不仅在mR@K指标上性能最好,在R@K指标上也有不错的表现,NICEMean指标上也达到了SOTA,这些都证明了论文方法能显著提高预测尾部类别的性能,同时保持预测头部类别的良好性能。
表1在SGG的三个任务上的性能实验
消融实验
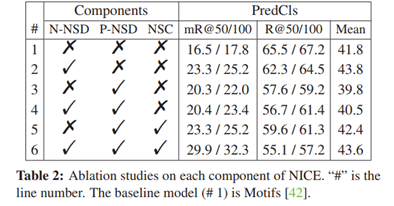
表2是在VGG数据集上对应的消融实验,六种情况对应了对数据集的不同操作,也证明了论文方法的每各部分都可以单独使用,并且均可提高在mR@K指标上的性能。
表2对NICE各部分的消融实验
对超参的实验如下表
表3对超参的消融实验

表3(a)是对噪声负样本的采集范围的消融实验,共有三种情况1)所有谓词类别,2)身体和尾部类别3)只有尾部类别,根据实验结果,可以得出:1)不同的阈值设置对mR@K指标有轻微影响,但对R@K指标的影响相对较大。2)当只挖掘Neg-NSD中缺失的尾部谓词时,该模型获得了最佳性能。
表3(b)是对超参dc的消融实验,不同的dc直接影响每个谓词类别的聚类结果,而较小的dc更适合于具有多种语义的谓词(比如in,表达的意思可以为“在…里”或“穿着”)。L,M,S表示dc取大、中、小。本文认为对于具有多种语义的谓词类别(头部类别),小dc对噪声样本检测更有利。对于具有独特语义的谓词类别(尾部类别),较大的dc则更好。实验结果表明设置为(S,M,L)的表现最好,验证了作者的猜想。
表3(c)是对wKNN中的超参数K(邻居样本个数)的消融实验,实验表明改变K对SGG模型性能的影响不大,本文将K设置为3。
可视化实验
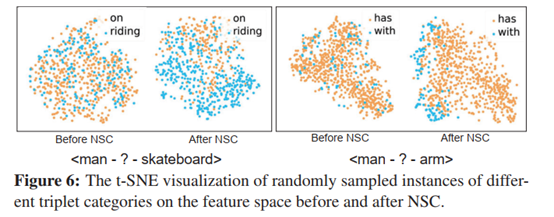
图4对经过NICE处理前后的谓词特征可视化
对处理前后的噪声正样本使用t-SNE特征可视化,可以看到使用NICE使两类标签的特征在t-SNE图上由无序à规律。
思考
本文超参太多,感觉调参很困难,尤其是wKNN部分,不确定能否使用其他最近邻算法。论文也指出方法的局限性:无法在不同评价指标上找到一个最合适的超参。
论文的损失函数以前从未接触过,本文的理解方式很有趣(将引入的GT预测概率比喻成提示,并引入了惩罚损失),但是计算损失使用的GT是场景图模型预测后的概率分布,一般的GT都是one-hot形式,所以感觉应用在其他方法时会受限制。
写作分析
摘要分析
1-2句:介绍传统方法存在的问题:忽视了数据集GT中会出现错误标注的情况。默认认为 1)所有正样本的标注是对的2)所有未标注的负样本都是背景。
3句:接上文引出本文发现的问题,证明了这两个假设是不恰当的,即SGG数据集中存在大量的noisyGT谓词标签,并且他影响了对无偏场景图模型的训练。
4-5句:基于问题本文提出了解决方案,SGG中的模型纠正型策略:NICE,检测出noisy样本同时加以改正,重新为其分配一个高质量谓词标签,通过NICE策略训练后会得到更清楚的SGG数据集。
6-9句:进一步介绍方法的细节,NICE主要是三部分内容
1) 负样本noisy检测(Neg-NSD):将视为out-of-distribution检测问题,代表的是前景被标记为背景的那部分。并分配伪标签给噪声负样本。
2) 正样本noisy 检测(Pos-NSD):通过基于聚类的算法将所有正样本分为多个集合,将最有噪声的集合视为噪声正样本。
3) noisy样本纠正:通过加权KNN算法为噪声正样本分配新的谓词标签。
10句:展示结果:在许多baseline上都有效,且NICE的各部分是普遍适用的
结论分析
1句:提出本文最主要针对的问题,即两个看似合理的假设实际上在SGG数据集中是不合适的。
2句:由此将SGG作为噪声标签学习问题的方向重新思考,提出了NICE策略
3-4句:介绍NICE的主要内容,还有他取得的成果,结论就是每个部分都很有效且很适用。
这篇关于The Devil is in the Labels: Noisy Label Correction forRobust Scene Graph Generation阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









