unreliable专题

IP Geolocation Databases: Unreliable?(2011年)
下载地址:IP geolocation databases: unreliable?: ACM SIGCOMM Computer Communication Review: Vol 41, No 2 被引用次数:472 Poese I, Uhlig S, Kaafar M A, et al. IP geolocation databases: Unreliable?[J]. ACM SI

Large stack use Severity:High Techniacl Impact:Denial of service, unreliable execution
Q:Large stack use Severity:High Techniacl Impact:Denial of service, unreliable execution Explain: 栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译
Cycle inside CryptoSwift; building could produce unreliable results.
Cycle inside CryptoSwift; building could produce unreliable results. This usually can be resolved by moving the target's Headers build phase before Compile Sources. 问题解决办法是其他网站看到的,下面是链接: R.swift 运行失

【语义分割研究】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 不可靠伪标签的半监督语义分割
论文标题:Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 作者信息:商汤科技, 上海交通大学, 香港中文大学 录用信息:CVPR 2022 → arXiv:https://arxiv.org/pdf/2203.03884.pdf 代码开源:https://github.com/Haochen-Wang409/

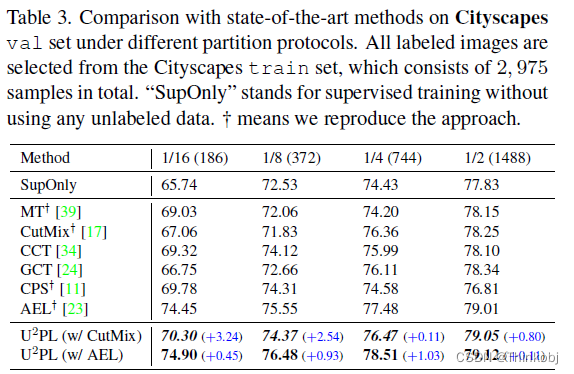
(2022 CVPR) U2PL Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
(2022 CVPR) U2PL Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels Motivation: 半监督语义分割的关键是为未标记图像的像素分配足够的伪标签。 即使是不可靠的预测结果,虽然无法打上确定的伪标签,但仍可以作为部分类别的负样本,从而参与到模型的训练,从而让所有的无标签样本都能在训练过程中
【CVPR2022】论文阅读笔记Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 使用不可靠伪标签的半监督语义分割 论文地址:https://arxiv.org/abs/2203.03884 代码地址 :https://haochen-wang409.github.io/U2PL. 摘要 半监督语义分割的关键是给无标签图像的像素分配
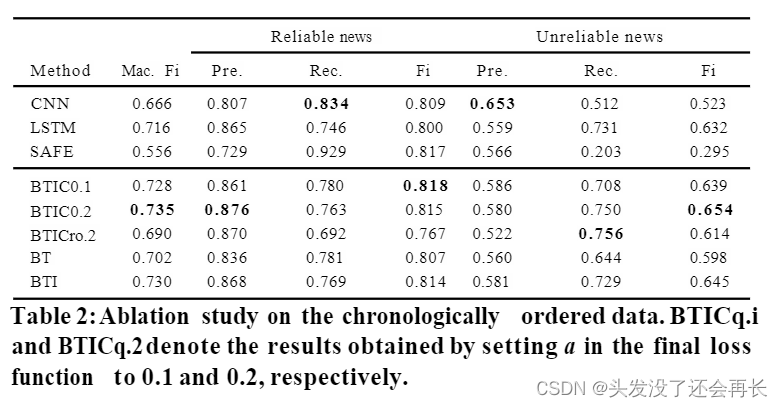
谣言检测论文精度——10.CIKM-21Supervised Contrastive Learning for Multimodal Unreliable News Detection
Abstract 作者在这一小节提出了自己关于谣言检测的新见解以及新模型: 新闻报道的可信度不应孤立地考虑。相反,可以使用之前发布的关于类似事件的新闻文章来评估新闻报道的可信度。受此启发,我们提出了一个基于BERT的多模式不可靠新闻检测框架,该框架利用对比学习策略从不可靠文章中捕获文本和视觉信息。对比学习者与不可靠新闻分类器进行交互,将相似的可信新闻(或类似的不可靠新闻)推得更近,同时在多模态嵌
TRAINING DEEP NEURAL-NETWORKS BASED ON UNRELIABLE LABELS 论文笔记
TRAINING DEEP NEURAL-NETWORKS BASED ON UNRELIABLE LABELS 论文笔记 论文摘要 本文解决的问题是如何使用不可靠的标签进行神经网络的训练。 作者通过假设一个噪声层,通过真实标签加上一个参数未知的噪声信道产生观察到的标签。 提出了一种学习神经网络参数和噪声分布的方法。 将这种方法和忽略了错误标签的标准的反向传播神经网络训练进行比较。 在

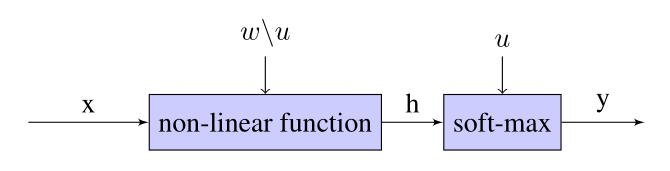
【Noise-Label】《Training a Neural Network Based on Unreliable Human Annotation of Medical Images》
2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) 文章目录 1 Background and Motivation2 Innovations3 Method3.1 TRAINING A DEEP NEURAL NETWORK WITH A NOISY CHANNEL 4 Experimen

【弱监督学习】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
0.前言 这是一篇在2022年发表在CVPR上的有关弱监督语义分割的文章,文章关注使用图像级标签进行语义分割弱监督训练。现有方法通常产生伪标签,然后通过某种方法对伪标签进行过滤,仅仅使用可靠的像素来进行弱监督训练,然而这样通常会损失大量的像素,导致许多没有被判定为可靠的像素没有被使用,为了提高无像素级标签数据的使用率,本文提出了了U2PL框架。 1.介绍 全监督方法通常需要大量高质量的像素级

POJ 2041 Unreliable Message G++
#include <iostream>#include <cstdio>#include <string>#include <algorithm>using namespace std;//英语 抄博友程序 模拟 string s;int n;void J(){char c=s[n-1];s.erase(n-1,1);s.insert(0,1,c);//

文献阅读--Federated Learning with Unreliable Clients: Performance Analysis and Mechanism Design
本文讲述了在联邦学习中,如何确定上传异常梯度的 Unreliable Clients,并提出了DeepSA算法,用来屏蔽Unreliable Clients上传的本地模型参数。除此以外,本文还推算了在异常场景下中心模型损失函数收敛的上界,并得到了最佳本地训练epoch的数量。 创新点:使用卷积神经网络鉴别异常参数(通过观察发现针对同一用户,其第k轮的数据及其领域几轮的数据具有相关性,这样的相关性