本文主要是介绍谣言检测论文精度——10.CIKM-21Supervised Contrastive Learning for Multimodal Unreliable News Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
作者在这一小节提出了自己关于谣言检测的新见解以及新模型:
新闻报道的可信度不应孤立地考虑。相反,可以使用之前发布的关于类似事件的新闻文章来评估新闻报道的可信度。受此启发,我们提出了一个基于BERT的多模式不可靠新闻检测框架,该框架利用对比学习策略从不可靠文章中捕获文本和视觉信息。对比学习者与不可靠新闻分类器进行交互,将相似的可信新闻(或类似的不可靠新闻)推得更近,同时在多模态嵌入空间中将内容相似但可信度标签相反的新闻文章移得更远。
1.Introduction
作者指出,现有的关于多模态新闻检测只关注输入文章中文本和图像的相关性,而忽略了文章之间的微妙关系。 所以为了解决上面的问题,作者提出了一个新的对比学习框架,利用给定文章之前发布的可靠/不可靠新闻,在多模态嵌入空间中细化学习度量。
该文章的主要贡献:
(1)作者所提出的模型是首次尝试将对比学习用于多模态不可靠新闻检测;
(2) 每个输入图像被分割成一系列图像块,以构建一个类似BERT的统一多模式模型,更好地捕获文本和图像之间的微妙交互。
Related Work
作者介绍了谣言检测相关工作并指出了他们的不足,然后介绍了对比学习,在对比学习中,作者指出了没有谣言检测任务中使用对比学习的一个可能原因:在典型的监督对比学习中,假设正样本和随机选择的负样本之间的不相关程度可以通过比较它们的类标签来捕获对比损失。然而,在虚假新闻检测中,即使文章共享同一标签,也可能是无关的,因为它们可能讨论不同的事件或主题。
因此,需要制定一种不同的策略,在不可靠新闻检测中选择负面样本进行对比学习。
3.METHODOLOGY
我们提出了一种多模式不可靠新闻检测模型,该模型由三个主要组件组成:文本编码器、图像编码器和联合学习,使用存储库将交叉熵损失和结构损失结合起来。该模式的概述如图1所示。
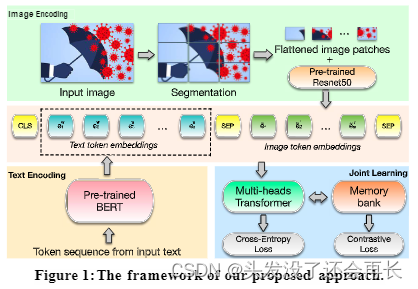
3.1Text Encoder
文本编码组件的输入是来自新闻文章的固定长度的单词序列w = {w1,w2, …,wn},预先训练的BERT模型[2]用于将文本序列编码为嵌入序列,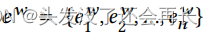
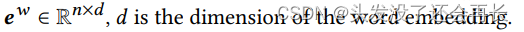
3.2Image Encoder
作者将图像分成m个小片,{I1,I2,…, Im},用预训练的ResNet-50将每一个图像小片被编码成一个向量eij,最后一个图像可以被表示成一个序列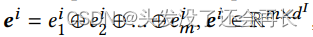
为了提取更多信息特征,表示形式ei首先经过两个线性投影,从dI维映射到d维。然后将其馈送到Transformer层,以捕获图像补丁之间的微妙相互作用。
最后,图像表示为:
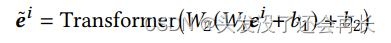
Joint Learning
多模态特征表示:为了结合视觉和文本特征,将3.1和3.2小结得到的文本和视觉表示结合起来
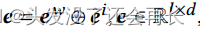
最后的表示x由一下公式给出:
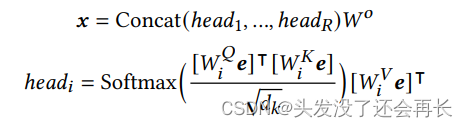
交叉熵损失:获得多模态特征之后,使用最大池化和平均池化执行下采样,droout=0.5,得到的最终文章表示xo被送入sigmoid生成预测标签y^=Sigmoid(Wc xd +bc),交叉熵损失定义为
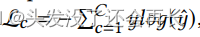
对比损失: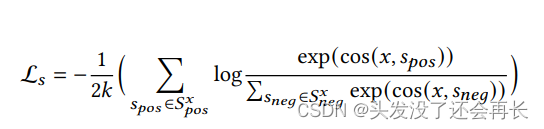
4.Experiment
Dataset
在新冠肺炎相关数据集ReCOVery[28]上进行实验
Results
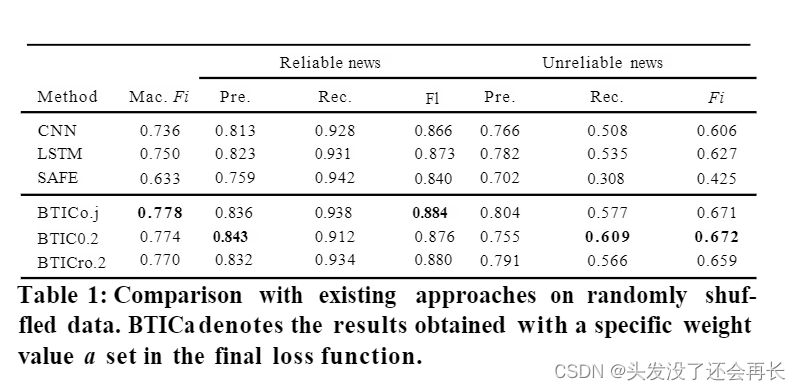
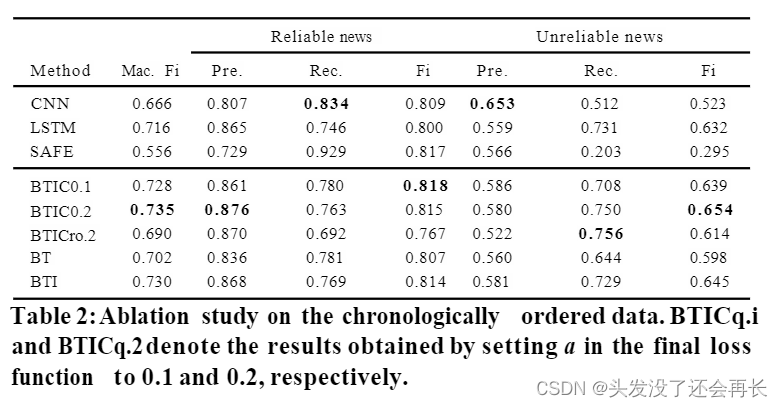
Conclusion
作者在假新闻检测中应用了对比学习机制,并且和以往多模态融合不同的是,作者还加入了以前的文章信息来对比学习。
这篇关于谣言检测论文精度——10.CIKM-21Supervised Contrastive Learning for Multimodal Unreliable News Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!