本文主要是介绍TRAINING DEEP NEURAL-NETWORKS BASED ON UNRELIABLE LABELS 论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TRAINING DEEP NEURAL-NETWORKS BASED ON UNRELIABLE LABELS 论文笔记
论文摘要
本文解决的问题是如何使用不可靠的标签进行神经网络的训练。
作者通过假设一个噪声层,通过真实标签加上一个参数未知的噪声信道产生观察到的标签。
提出了一种学习神经网络参数和噪声分布的方法。
将这种方法和忽略了错误标签的标准的反向传播神经网络训练进行比较。
在几个标准的分类任务中展示了该方法对性能的改进。
证明了该方法有提升,即使标签是手动设置的正确标签,也能得到提升。
TRAINING NN WITH NOISY LABELS
首先我们要训练一个多类别分类神经网络
p ( y = i ∣ x ; w ) p(y=i \mid x ; w) p(y=i∣x;w)
- x x x为特征向量
- w w w为网络参数
进一步假设我们不能观察到正确的标签 y y y,我们只能获得带有噪声的标签 z z z
噪声是通过参数 θ ( i , j ) = p ( z = j ∣ y = i ) \theta(i, j)=p(z=j \mid y=i) θ(i,j)=p(z=j∣y=i)产生的,其中噪声的分布是未知的,需要作为训练的一部分。
观察到带有噪声标签 z z z 的几率和特征向量 x x x 之间的关系如下:
p ( z = j ∣ x ; w , θ ) = ∑ i = 1 k p ( z = j ∣ y = i ; θ ) p ( y = i ∣ x ; w ) p(z=j \mid x ; w, \theta)=\sum_{i=1}^{k} p(z=j \mid y=i ; \theta) p(y=i \mid x ; w) p(z=j∣x;w,θ)=∑i=1kp(z=j∣y=i;θ)p(y=i∣x;w)
- k k k为分类数
整个模型的过程如下图:
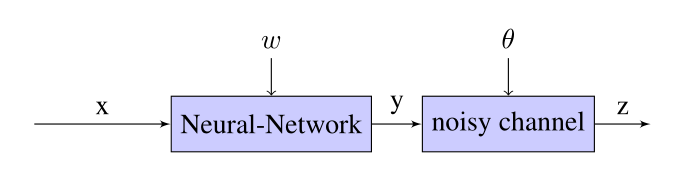
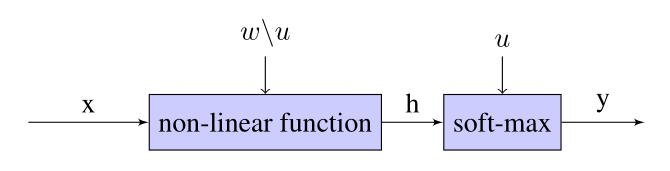
假设分类神经网络的中间层使用的是非线形层,输出层使用的是softmax分类器
input x x x 通过非线性层 :
h = h ( x ) h = h(x) h=h(x)
通过softmax层:
p ( y = i ∣ x ; w ) = exp ( u i ⊤ h ) ∑ j = 1 k exp ( u j ⊤ h ) , i = 1 , … , k p(y=i \mid x ; w)=\frac{\exp \left(u_{i}^{\top} h\right)}{\sum_{j=1}^{k} \exp \left(u_{j}^{\top} h\right)}, \quad i=1, \ldots, k p(y=i∣x;w)=∑j=1kexp(uj⊤h)exp(ui⊤h),i=1,…,k
- 其中 u 1 , . . . , u k u_1,...,u_k u1,...,uk为softmax的参数,属于神经网络参数 w w w的子集
在训练的过程中,给出n个特征向量, x 1 , . . . , x n x_1,...,x_n x1,...,xn,和他们对应的标签 z 1 , . . . , z n z_1,...,z_n z1,...,zn ,( z 1 , . . . , z n z_1,...,z_n z1,...,zn 是由正确标签 y 1 , . . . , y n y_1,...,y_n y1,...,yn加上噪声得来的)
模型参数 w w w的对数似然函数为:
L ( w , θ ) = ∑ t = 1 n log ( ∑ i = 1 k p ( z t ∣ y t = i ; θ ) p ( y t = i ∣ x t ; w ) ) L(w, \theta)=\sum_{t=1}^{n} \log \left(\sum_{i=1}^{k} p\left(z_{t} \mid y_{t}=i ; \theta\right) p\left(y_{t}=i \mid x_{t} ; w\right)\right) L(w,θ)=∑t=1nlog(∑i=1kp(zt∣yt=i;θ)p(yt=i∣xt;w))
训练的目标是:1.找到噪声 θ θ θ 的的分布。2.找到参数 w w w对应的最大似然函数
因为 y 1 , . . . , y n y_1,...,y_n y1,...,yn被隐藏了,使用EM算法来求解最大似然参数。
EM-auxiliary func-tion如下:
Q ( w 0 , θ 0 , w , θ ) = ∑ t = 1 n ∑ i = 1 k p ( y t = i ∣ x t , z t ; w 0 , θ 0 ) ⋅ ( log p ( y t = i ∣ x t ; w ) + log p ( z t ∣ y t = i ; θ ) ) \begin{aligned} Q\left(w_{0}, \theta_{0}, w, \theta\right) &=\sum_{t=1}^{n} \sum_{i=1}^{k} p\left(y_{t}=i \mid x_{t}, z_{t} ; w_{0}, \theta_{0}\right) \cdot\left(\log p\left(y_{t}=i \mid x_{t} ; w\right)+\log p\left(z_{t} \mid y_{t}=i ; \theta\right)\right) \end{aligned} Q(w0,θ0,w,θ)=t=1∑ni=1∑kp(yt=i∣xt,zt;w0,θ0)⋅(logp(yt=i∣xt;w)+logp(zt∣yt=i;θ))
- w 0 , θ 0 w_0, θ_0 w0,θ0 为当前的参数
- 我们要寻找参数$w, \theta $来最大化EM auxiliary function。
在更新参数的时候使用了EM算法:
EM算法分为两步,即E步和M步。
-
在E步中,根据含有噪声标签和当前参数来估计隐藏的真实数据标签。
c t i = p ( y t = i ∣ x t , z t ; w 0 , θ 0 ) = p ( z t ∣ y t = i ; θ 0 ) p ( y t = i ∣ x t ; w 0 ) ∑ j p ( z t ∣ y t = j ; θ 0 ) p ( y t = j ∣ x t ; w 0 ) = θ 0 ( i , z t ) exp ( u i 0 ⊤ h 0 ( x t ) ) ∑ j θ 0 ( j , z t ) exp ( u j 0 ⊤ h 0 ( x t ) ) \begin{aligned} c_{t i} &=p\left(y_{t}=i \mid x_{t}, z_{t} ; w_{0}, \theta_{0}\right) \\ &=\frac{p\left(z_{t} \mid y_{t}=i ; \theta_{0}\right) p\left(y_{t}=i \mid x_{t} ; w_{0}\right)}{\sum_{j} p\left(z_{t} \mid y_{t}=j ; \theta_{0}\right) p\left(y_{t}=j \mid x_{t} ; w_{0}\right)} \\ &=\frac{\theta_{0}\left(i, z_{t}\right) \exp \left(u_{i 0}^{\top} h_{0}\left(x_{t}\right)\right)}{\sum_{j} \theta_{0}\left(j, z_{t}\right) \exp \left(u_{j 0}^{\top} h_{0}\left(x_{t}\right)\right)} \end{aligned} cti=p(yt=i∣xt,zt;w0,θ0)=∑jp(zt∣yt=j;θ0)p(yt=j∣xt;w0)p(zt∣yt=i;θ0)p(yt=i∣xt;w0)=∑jθ0(j,zt)exp(uj0⊤h0(xt))θ0(i,zt)exp(ui0⊤h0(xt))
其中 u 10 , . . . , u k 0 u_{10}, ..., u_{k0} u10,...,uk0和 h 0 ( x ) h_0(x) h0(x)是参数 w 0 w_0 w0的一部分。
-
在M步中,同时更新神经网络参数和噪声参数。
θ ( i , j ) = ∑ t c t i 1 { z t = j } ∑ t c t i , i , j ∈ { 1 , … , k } \theta(i, j)=\frac{\sum_{t} c_{t i} 1_{\left\{z_{t}=j\right\}}}{\sum_{t} c_{t i}}, \quad i, j \in\{1, \ldots, k\} θ(i,j)=∑tcti∑tcti1{zt=j},i,j∈{1,…,k}
为了找到更新后的NN参数w,我们需要最大化以下函数:
S ( w ) = ∑ t = 1 n ∑ i = 1 k c t i log p ( y t = i ∣ x t ; w ) S(w)=\sum_{t=1}^{n} \sum_{i=1}^{k} c_{t i} \log p\left(y_{t}=i \mid x_{t} ; w\right) S(w)=∑t=1n∑i=1kctilogp(yt=i∣xt;w)
NLNN算法
input: 数据 x 1 , . . . , x n ∈ R d x_1,...,x_n \in R^d x1,...,xn∈Rd,和对应的噪声标签 $z_1, …, z_n \in (1, …, k) $
**output:**神经网络参数 w w w,噪声参数 θ \theta θ
EM算法在两个步骤之间进行迭代:
-
E-step:根据当前参数值估计真实标签
c t i = p ( y t = i ∣ x t , z t ; w 0 , θ 0 ) c_{ti} =p(y_{t}=i \mid x_{t}, z_{t} ; w_{0}, \theta_{0}) cti=p(yt=i∣xt,zt;w0,θ0)
-
M-step:更新噪声参数 θ \theta θ
θ ( i , j ) = ∑ t c t i 1 { z t = j } ∑ t c t i \theta(i, j)=\frac{\sum_{t} c_{t i} 1_{\left\{z_{t}=j\right\}}}{\sum_{t} c_{t i}} θ(i,j)=∑tcti∑tcti1{zt=j}
训练神经网络,找到 w w w使下面函数最大化:
L ( w ) = ∑ t = 1 n ∑ i = 1 k c t i log p ( y t = i ∣ x t ; w ) L(w)=\sum_{t=1}^{n} \sum_{i=1}^{k} c_{t i} \log p\left(y_{t}=i \mid x_{t} ; w\right) L(w)=∑t=1n∑i=1kctilogp(yt=i∣xt;w)
-
EM算法和反向传播算法可以交替使用
-
在训练时可以先用标准方法训练神经网络,将得到参数w作为EM迭代的初始值。
-
计算训练数据上的混淆矩阵,然后用来初始噪声参数θ
θ ( i , j ) = ∑ t 1 { z t = j } p ( y t = i ∣ x t ; w ) ∑ t p ( y t = i ∣ x t ; w ) , i , j ∈ { 1 , … , k } \theta(i, j)=\frac{\sum_{t} 1_{\left\{z_{t}=j\right\}} p\left(y_{t}=i \mid x_{t} ; w\right)}{\sum_{t} p\left(y_{t}=i \mid x_{t} ; w\right)}, \quad i, j \in\{1, \ldots, k\} θ(i,j)=∑tp(yt=i∣xt;w)∑t1{zt=j}p(yt=i∣xt;w),i,j∈{1,…,k}
EXPERIMENTS
作者在手写数字的MNIST数据库和TIMIT声学-音素连续语音语料库进行了测试。
第一类数据随机修改了标签,第二类数据按照概率分布修改了标签。
在MNIST数据上训练NLNN模型时,先在有噪声的数据上,使用反向传播迭代100个epoch初始化参数w,然后再使用EM算法直到收敛。在每次迭代中,用50个epoch来训练NN估计标签。在每次EM迭代中,先用随机参数进行反向传播。
这篇关于TRAINING DEEP NEURAL-NETWORKS BASED ON UNRELIABLE LABELS 论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






