本文主要是介绍【语义分割研究】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 不可靠伪标签的半监督语义分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
作者信息:商汤科技, 上海交通大学, 香港中文大学
录用信息:CVPR 2022 → arXiv:https://arxiv.org/pdf/2203.03884.pdf
代码开源:https://github.com/Haochen-Wang409/U2PL
Project Page:https://haochen-wang409.github.io/U2PL/
背景
半监督学习的核心问题在于有效利用无标注数据,作为有标签样本的补充,以提升模型性能。
- 通常作法是通过样本筛选等方式降低错误伪标签的影响,然而只选择高置信度的预测结果作为无标签样本的伪标签,这种朴素的 self-training 策略会将大量的无标签数据排除在训练过程外,导致模型训练不充分。
- 此外,如果模型不能较好地预测某些 hard class,那么就很难为该类别的无标签像素分配准确的伪标签,从而进入恶性循环。
这篇论文的核心思想:低质量伪标签也应当被合理利用
Motivation: Every Pixel Matters
具体来说,预测结果的可靠与否,我们可以通过熵 (per-pixel entropy) 来衡量,低熵表示预测结果可靠,高熵表示预测结果不可靠。我们通过 Figure 2 来观察一个具体的例子,Figure 2(a) 是一张蒙有 entropy map 的无标签图片,高熵的不可靠像素很难被打上一个确定的伪标签,因此不参与到 re-training 过程,在 FIgure 2(b) 中我们以白色表示。
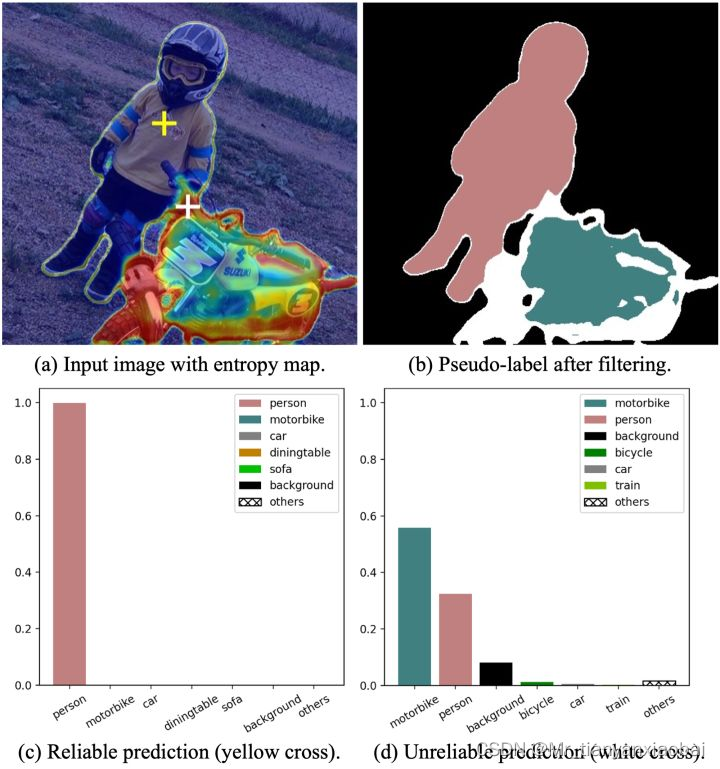
- figure.c 中的小孩的置信度很高,证明模型预测结果可行。figure.d 中像素点在 motorbike 和 person 两个类别上都具有不低的预测概率且在数值上较为接近,模型无法给出一个确定的预测结果,符合文中定义的 unralibale prediction。但是显然,不属于 car 或者 train这种类别
- 即使是不可靠的预测结果,虽然无法打上确定的伪标签,但可以作为部分类别的负样本,从而参与到模型的训练。这样所有的无标签样本都能在训练过程中发挥作用。
Method

- 对于有标签的数据,利用 student 进行学习训练。然后利用训练好的模型,将无标签数据中的像素分为 reliable 和 unreliable 两种,然后再在这个基础上进行对比表征学习。单个网络的具体组成主要参考的是 ReCo,具体包括 e n c o d e r h , d e c o d e r f encoder h, decoder f encoderh,decoderf 和表征头 g g g。
- 目标函数如下:
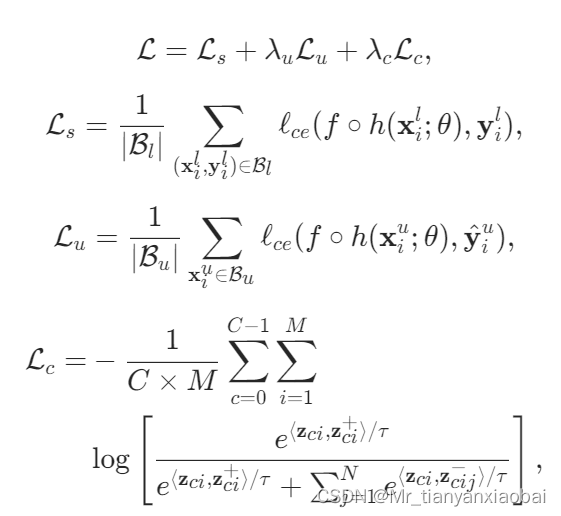
- 损失函数优化上,有标签数据直接基于标准的交叉熵损失函数 L s L_s Ls 进行优化。
- 无标签数据则先靠 teacher 给出预测结果,然后根据 pixel-level entropy 分成 reliable pixels 和 unreliable pixels 两大部分 最后分别基于 L u L_u Lu 和 L c L_c Lc 进行优化。这个 L c L_c Lc 就是对比表征的InfoNCE Loss
L c L_c Lc中的正负样本
- 正样本对: 对于有标签样本和无标签样本,筛选的标准是一致的,就是该样本在真值标签类别或伪标签类别上的预测概率大于一个阈值,
- 负样本对:对于有标签样本,因们明确知道其所属的类别,因此除真值标签外的所有类别都可以作为该像素的负样本类别;而对于无标签样本,由于伪标签可能存在错误,因此我们并不完全却行确信标签的正确性,因而我们需要将预测概率最高的几个类别过滤掉,将该像素认作为剩下几个类别的负样本。
实验结果
网络结构:ResNet-101 + Deeplab v3
数据集合:** Classic VOC, Blender VOC, Cityscapes **
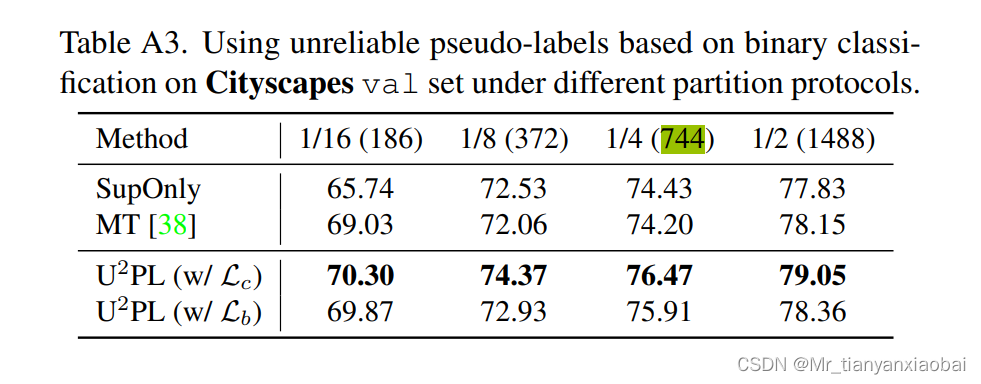
- 分数表示标签数据与无标签数据的比例
论文复现
- 具体思路可以按照github上的readMe来,当然可能有几个点需要修改:
文件目录下载
- 数据集下载:
- Download “eftImg8bit_trainvaltest.zip" from: https://www.cityscapes-dataset.com/downloads/
- Download “gtFine.zip” from: https://drive.google.com/file/d/10tdElaTscdhojER_Lf7XlytiyAkk7Wlg/view?usp=sharing
- 下载数据集合,然后将其放入项目中,文件目录如下:
data ├── cityscapes │ ├── gtFine │ └── leftImg8bit ├── splits │ ├── cityscapes │ └── pascal
模型训练
要求:由于图片过大,目前batchsize=4的情况下,也需要8个GPU才能跑。训练步骤如下:
-
迁移学习,下载ImageNet的预训练模型: Baidu Drive Fetch Code: 3p9h
-
for Cityscapes, a model supervised by
744labeled data and2231unlabeled data can be trained by:cd experiments/cityscapes/744/ours # use torch.distributed.launch sh train.sh <num_gpu> <port># or use slurm # sh slurm_train.sh <num_gpu> <port> <partition>After training, the model should be evaluated by
sh eval.sh
模型测试【以744 Cityscapes数据集为例】
- 由于模型训练过程要求的硬件太高,可以使用作者提供的预训练模型,直接进行测试。
- 为了复现作者结果可能需要修改几处代码:
- 第一处:修改
experiments/cityscapes/744/ours/config.yaml中的dataset的type:dataset: # Required.type: cityscapes_semi - 第二处:下载作者提供的训练好的模型【这里下载744的即可】,将其放在
experiments/cityscapes/744/ours/checkpoints - 第三处:在
experiments/cityscapes/744/ours/eval.sh中修改加载模型的路径:python $ROOT/eval.py \ --config=config.yaml \ --base_size 128 \ --scales 1.0 \ --model_path=checkpoints/city_744_AEL_U2PL_78.51.pth \ --save_folder=checkpoints/results \ 2>&1 | tee log/val_last_$now.txt - 第四处:增加加载语句: 大概率是由于作者提供的训练模型是很早之前的,然后新代码和这个模型的字段还有所不同因此,需要在
eval.py的122行添加一句话:..... checkpoint = torch.load(args.model_path) checkpoint = {'model_state': checkpoint}#需要添加的加载语句 key = "teacher_state" if "teacher_state" in checkpoint.keys() else "model_state" ````` ........
- 第一处:修改
- 开始测试:
sh cd experiments/cityscapes/744/ours sh eval.sh
结果如下【实验结果和论文结果基本一致】:[2022-11-08 18:07:48,490 INFO eval.py line 77 18926] Namespace(base_size=128, config='config.yaml', crop=False, model_path='checkpoints/city_744_AEL_U2PL_78.51.pth', names_path='../../vis_meta/cityscapes/cityscapesnames.mat', save_folder='checkpoints/results', scales=[1.0]) [2022-11-08 18:07:48,491 INFO eval.py line 118 18926] => creating model from 'checkpoints/city_744_AEL_U2PL_78.51.pth' ... [2022-11-08 18:07:49,253 INFO eval.py line 125 18926] => load checkpoint[model_state] [2022-11-08 18:07:51,020 INFO eval.py line 130 18926] Load Model Done! [2022-11-08 18:07:51,020 INFO eval.py line 317 18926] >>>>>>>>>>>>>>>> Start Evaluation >>>>>>>>>>>>>>>> [2022-11-08 18:07:58,969 INFO eval.py line 348 18926] Test: [10/500] Data 0.161 (0.155) Batch 0.780 (0.795). [2022-11-08 18:08:07,000 INFO eval.py line 348 18926] Test: [20/500] Data 0.165 (0.164) Batch 0.782 (0.799). [2022-11-08 18:08:15,025 INFO eval.py line 348 18926] Test: [30/500] Data 0.168 (0.167) Batch 0.793 (0.800). [2022-11-08 18:08:23,096 INFO eval.py line 348 18926] Test: [40/500] Data 0.160 (0.168) Batch 0.783 (0.802). [2022-11-08 18:08:31,215 INFO eval.py line 348 18926] Test: [50/500] Data 0.180 (0.169) Batch 0.819 (0.804). [2022-11-08 18:08:39,478 INFO eval.py line 348 18926] Test: [60/500] Data 0.175 (0.169) Batch 0.822 (0.808). [2022-11-08 18:08:47,866 INFO eval.py line 348 18926] Test: [70/500] Data 0.169 (0.170) Batch 0.854 (0.812). [2022-11-08 18:08:56,149 INFO eval.py line 348 18926] Test: [80/500] Data 0.171 (0.169) Batch 0.834 (0.814). [2022-11-08 18:09:04,485 INFO eval.py line 348 18926] Test: [90/500] Data 0.157 (0.169) Batch 0.821 (0.816). [2022-11-08 18:09:12,885 INFO eval.py line 348 18926] Test: [100/500] Data 0.162 (0.170) Batch 0.839 (0.819). [2022-11-08 18:09:21,369 INFO eval.py line 348 18926] Test: [110/500] Data 0.175 (0.170) Batch 0.877 (0.821). [2022-11-08 18:09:29,919 INFO eval.py line 348 18926] Test: [120/500] Data 0.181 (0.170) Batch 0.842 (0.824). [2022-11-08 18:09:38,498 INFO eval.py line 348 18926] Test: [130/500] Data 0.153 (0.170) Batch 0.828 (0.827). [2022-11-08 18:09:47,131 INFO eval.py line 348 18926] Test: [140/500] Data 0.157 (0.170) Batch 0.836 (0.829). [2022-11-08 18:09:55,671 INFO eval.py line 348 18926] Test: [150/500] Data 0.168 (0.170) Batch 0.839 (0.831). [2022-11-08 18:10:04,354 INFO eval.py line 348 18926] Test: [160/500] Data 0.167 (0.170) Batch 0.902 (0.833). [2022-11-08 18:10:12,982 INFO eval.py line 348 18926] Test: [170/500] Data 0.167 (0.170) Batch 0.848 (0.835). [2022-11-08 18:10:21,601 INFO eval.py line 348 18926] Test: [180/500] Data 0.180 (0.170) Batch 0.862 (0.837). [2022-11-08 18:10:30,361 INFO eval.py line 348 18926] Test: [190/500] Data 0.165 (0.170) Batch 0.856 (0.839). [2022-11-08 18:10:39,035 INFO eval.py line 348 18926] Test: [200/500] Data 0.165 (0.170) Batch 0.857 (0.840). [2022-11-08 18:10:47,812 INFO eval.py line 348 18926] Test: [210/500] Data 0.178 (0.170) Batch 0.867 (0.842). [2022-11-08 18:10:56,564 INFO eval.py line 348 18926] Test: [220/500] Data 0.178 (0.170) Batch 0.873 (0.843). [2022-11-08 18:11:05,361 INFO eval.py line 348 18926] Test: [230/500] Data 0.165 (0.170) Batch 0.861 (0.845). [2022-11-08 18:11:14,090 INFO eval.py line 348 18926] Test: [240/500] Data 0.193 (0.170) Batch 0.887 (0.846). [2022-11-08 18:11:22,847 INFO eval.py line 348 18926] Test: [250/500] Data 0.165 (0.171) Batch 0.862 (0.847). [2022-11-08 18:11:31,592 INFO eval.py line 348 18926] Test: [260/500] Data 0.165 (0.170) Batch 0.850 (0.848). [2022-11-08 18:11:40,389 INFO eval.py line 348 18926] Test: [270/500] Data 0.161 (0.170) Batch 0.855 (0.850). [2022-11-08 18:11:49,215 INFO eval.py line 348 18926] Test: [280/500] Data 0.187 (0.170) Batch 0.915 (0.851). [2022-11-08 18:11:58,026 INFO eval.py line 348 18926] Test: [290/500] Data 0.171 (0.170) Batch 0.899 (0.852). [2022-11-08 18:12:06,710 INFO eval.py line 348 18926] Test: [300/500] Data 0.155 (0.170) Batch 0.824 (0.852). [2022-11-08 18:12:15,464 INFO eval.py line 348 18926] Test: [310/500] Data 0.180 (0.170) Batch 0.888 (0.853). [2022-11-08 18:12:24,274 INFO eval.py line 348 18926] Test: [320/500] Data 0.165 (0.170) Batch 0.869 (0.854). [2022-11-08 18:12:33,070 INFO eval.py line 348 18926] Test: [330/500] Data 0.167 (0.170) Batch 0.868 (0.855). [2022-11-08 18:12:41,751 INFO eval.py line 348 18926] Test: [340/500] Data 0.180 (0.170) Batch 0.891 (0.855). [2022-11-08 18:12:50,462 INFO eval.py line 348 18926] Test: [350/500] Data 0.172 (0.170) Batch 0.876 (0.856). [2022-11-08 18:12:59,278 INFO eval.py line 348 18926] Test: [360/500] Data 0.175 (0.170) Batch 0.872 (0.856). [2022-11-08 18:13:08,047 INFO eval.py line 348 18926] Test: [370/500] Data 0.149 (0.170) Batch 0.856 (0.857). [2022-11-08 18:13:16,831 INFO eval.py line 348 18926] Test: [380/500] Data 0.173 (0.170) Batch 0.879 (0.857). [2022-11-08 18:13:25,601 INFO eval.py line 348 18926] Test: [390/500] Data 0.167 (0.170) Batch 0.869 (0.858). [2022-11-08 18:13:34,488 INFO eval.py line 348 18926] Test: [400/500] Data 0.171 (0.170) Batch 0.886 (0.859). [2022-11-08 18:13:43,271 INFO eval.py line 348 18926] Test: [410/500] Data 0.170 (0.170) Batch 0.851 (0.859). [2022-11-08 18:13:52,088 INFO eval.py line 348 18926] Test: [420/500] Data 0.165 (0.170) Batch 0.900 (0.860). [2022-11-08 18:14:00,866 INFO eval.py line 348 18926] Test: [430/500] Data 0.168 (0.170) Batch 0.879 (0.860). [2022-11-08 18:14:09,642 INFO eval.py line 348 18926] Test: [440/500] Data 0.180 (0.170) Batch 0.848 (0.860). [2022-11-08 18:14:18,372 INFO eval.py line 348 18926] Test: [450/500] Data 0.156 (0.170) Batch 0.883 (0.861). [2022-11-08 18:14:27,039 INFO eval.py line 348 18926] Test: [460/500] Data 0.166 (0.170) Batch 0.860 (0.861). [2022-11-08 18:14:35,745 INFO eval.py line 348 18926] Test: [470/500] Data 0.160 (0.170) Batch 0.854 (0.861). [2022-11-08 18:14:44,440 INFO eval.py line 348 18926] Test: [480/500] Data 0.158 (0.170) Batch 0.849 (0.861). [2022-11-08 18:14:53,127 INFO eval.py line 348 18926] Test: [490/500] Data 0.153 (0.170) Batch 0.857 (0.861). [2022-11-08 18:15:01,846 INFO eval.py line 348 18926] Test: [500/500] Data 0.169 (0.170) Batch 0.848 (0.862 - 可视化结果如下:

原图查看【图片太大可能需要下载】: https://github.com/MRtianyanxiaobai/U2PL/blob/main/data/%E5%9B%BE%E7%89%871.png
这篇关于【语义分割研究】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels 不可靠伪标签的半监督语义分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






